Clear Sky Science · nl
Het verkennen van anatomische gelijkenis in zero-shot learning voor detectie van botafwijkingen
Waarom slimmer röntgenonderzoek ertoe doet
Gebroken botten behoren tot de meest voorkomende verwondingen, maar het bevestigen van een fractuur op een röntgenfoto berust nog steeds sterk op het getrainde oog van een radioloog. Die expertise is waardevol, maar ook tijdrovend en schaars in veel ziekenhuizen en klinieken wereldwijd. Deze studie stelt een eenvoudige maar krachtige vraag: kan een kunstmatig-intelligentiesysteem leren om botproblemen in één lichaamsdeel — bijvoorbeeld de elleboog — te herkennen en vervolgens zonder opnieuw te worden getraind vergelijkbare problemen in andere delen, zoals de pols of vingers, te vinden?
Een computer leren botten te lezen
Om dit idee te onderzoeken, gebruikten de onderzoekers een grote openbare verzameling röntgenfoto’s van de bovenste extremiteit genaamd de MURA-dataset. In plaats van zich alleen op fracturen te richten, labelt MURA elke patiëntstudie eenvoudig als “normaal” of “abnormaal.” Het team trainde een compact deep-learningmodel op röntgenbeelden van één specifiek deel van de arm, zoals de elleboog of pols, en vroeg het model vervolgens te beoordelen of studies uit andere regio’s gezond leken of niet. Belangrijk is dat het model tijdens de training nooit voorbeelden uit deze nieuwe regio’s te zien kreeg — een benadering die bekendstaat als “zero-shot” of out-of-domain learning.
Elke combinatie van lichaamsdelen testen
In plaats van te stoppen bij een paar handige tests, probeerden de auteurs systematisch elke mogelijke train–testcombinatie over zeven bovenarmregio’s: schouder, humerus, elleboog, onderarm, pols, hand en vinger. Ze behandelden ook elk patiëntbezoek, dat meerdere röntgenbeelden kan bevatten, als één besluitvormings-eenheid door de vertrouwensscores van het model over de beelden te middelen — dichter bij hoe artsen naar een casus kijken. Voor elk paar berekenden ze nauwkeurigheid en rigoureuze betrouwbaarheidsintervallen, en herhaalden ze zelfs belangrijke experimenten met een tweede, expressievere neurale netwerkarchitectuur om te zien of de trends onafhankelijk van het modelontwerp standhielden.
Wanneer vergelijkbare botten elkaar helpen
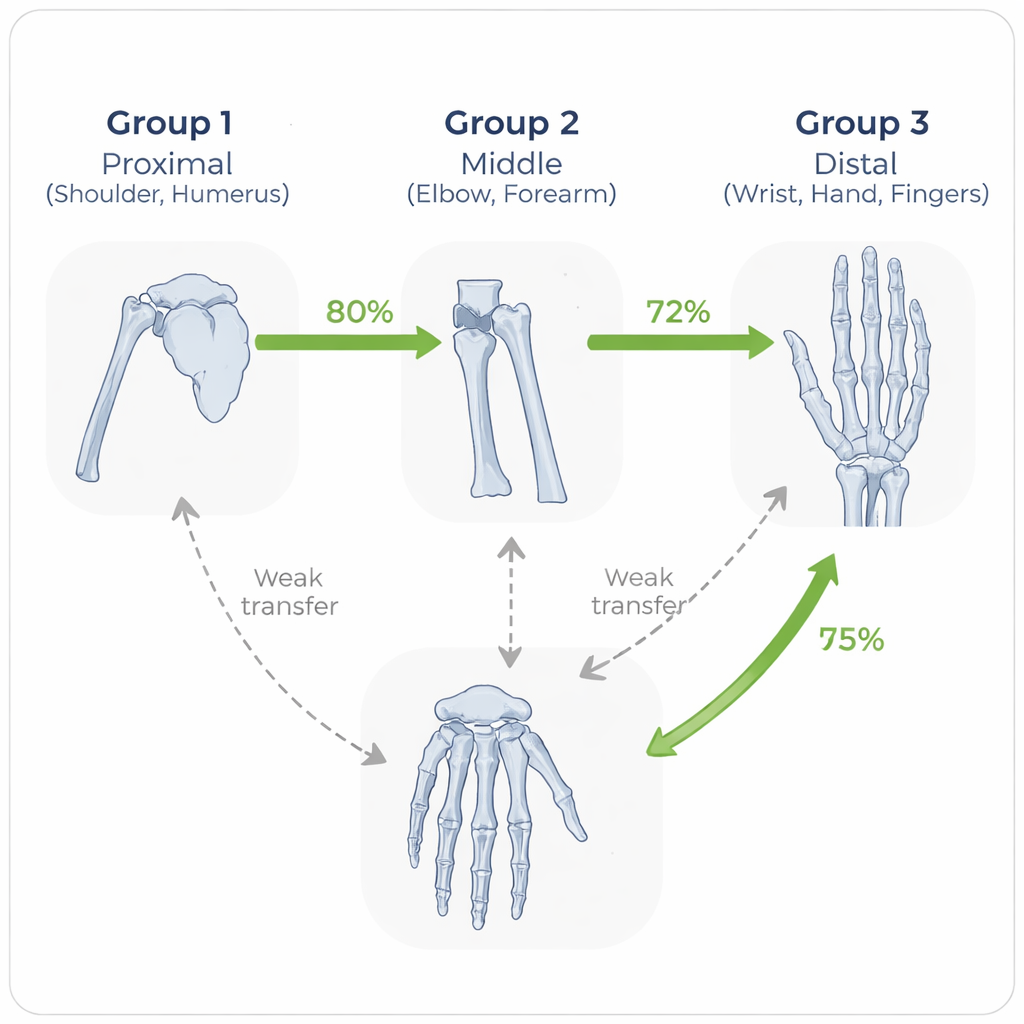
Er verscheen een opvallend patroon: het model presteerde het best wanneer het werd getest op hetzelfde lichaamsdeel waarop het was getraind, en als tweede het best wanneer trainings- en testdelen anatomisch vergelijkbaar waren. Bijvoorbeeld, een model getraind op onderarmbeelden transfereerde goed naar elleboogbeelden, en een op pols getraind model deed het relatief goed op hand- en vingerstudies. Daarentegen daalde de prestatie wanneer het model moest overspringen naar zeer verschillende regio’s, zoals van hand naar humerus. Door botten te groeperen in proximale (schouder, humerus), middelste (elleboog, onderarm) en distale (pols, hand, vinger) regio’s, toonde het team aan dat transfers binnen een groep consequent sterker waren dan transfers tussen groepen.
Voorbij één dataset of netwerk
Om te controleren dat deze observaties geen eigenaardigheden van één dataset of model waren, testten de onderzoekers hun getrainde systemen op een tweede verzameling röntgenfoto’s genaamd FracAtlas, die hand-, schouder-, heup- en beendata van verschillende ziekenhuizen bevat. Zonder enige fijnafstemming deed een model getraind op MURA-handbeelden het goed op beenfracturen maar toonde zwakkere prestaties op heup en schouder. Ze herhaalden ook enkele experimenten met een andere neurale netwerkarchitectuur en zagen vergelijkbare cross-regio patronen. Aanvullende analyses varieerden de beeldresolutie en onderzochten waar het model “keek” in de röntgenfoto met behulp van heatmaps, wat onthulde dat succesvolle voorspellingen vaak op klinisch relevante botgebieden waren gericht, terwijl fouten soms voortkwamen uit afleidingen zoals labels of randen in het beeld.
Wat dit betekent voor zorg in de praktijk
Voor niet-specialisten en zorgsystemen met beperkte middelen is de boodschap zowel bemoedigend als waakzaam. De studie laat zien dat een AI-hulpmiddel dat op één goed gelabelde set röntgenfoto’s is getraind, zinvol kan helpen bij de beoordeling van andere, vergelijkbare lichaamsdelen zonder telkens enorme nieuwe datasets te vereisen. De betrouwbaarheid neemt echter af wanneer de nieuwe regio’s te sterk verschillen van wat het eerder heeft gezien. In dagelijkse termen kan een systeem dat fracturen in de pols leert herkennen een nuttige assistent zijn voor hand en vingers, maar het mag niet blindelings worden vertrouwd voor schouder of heup. Het begrijpen van deze grenzen kan leiden tot efficiëntere gegevensverzameling — met prioriteit voor belangrijke anatomische groepen — en ondersteunt veiliger inzet van AI in klinieken met weinig radiologen, zodat meer patiënten tijdig en nauwkeurig beoordeeld worden op botletsels.
Bronvermelding: Kutbi, M., Shaban, K. & Khogeer, A. Exploring anatomical similarity in zero-shot learning for bone abnormality detection. Sci Rep 16, 6390 (2026). https://doi.org/10.1038/s41598-026-37516-9
Trefwoorden: detectie van botbreuken, AI voor medische beeldvorming, zero-shot learning, röntgenanalyse, transfer learning