Clear Sky Science · nl
Geautomatiseerde onkruidsegmentatie met kennisgebaseerde labeling voor toepassingen van machine learning
Waarom slimmer onkruidbeheer ertoe doet
Onkruid steelt stilletjes een groot deel van ’s werelds voedselproductie. Het verdringt gewassen, verlaagt de opbrengsten en zorgt ervoor dat boeren meer herbicide moeten spuiten, wat zowel financieel als ecologisch kostbaar is. Deze studie laat zien hoe drones en slimme beeldanalyse automatisch onkruid in tarwevelden kunnen in kaart brengen—zonder dat iemand planten zorgvuldig met de hand hoeft aan te wijzen. Zulke automatisering kan de ontwikkeling van instrumenten voor gerichter spuiten versnellen, waardoor chemisch gebruik afneemt terwijl oogsten op peil blijven.
Van blanket-spuiten naar gerichte behandeling
Wereldwijd kunnen velden zonder effectief onkruidbeheer tussen een vijfde en bijna de volledige potentiële opbrengst verliezen. In gebieden zoals de prairieprovincies van Canada lopen de herbicidekosten jaarlijks al in de honderden miljoenen dollars en verspreiden zich herbicideresistente onkruiden. Nieuwe tools voor “precisielandbouw” zijn erop gericht alleen te spuiten waar onkruid daadwerkelijk voorkomt, in plaats van hele percelen te behandelen. Daarvoor hebben machines eerst nauwkeurige onkruidkaarten nodig, en moderne benaderingen vertrouwen op machine-learningmodellen die elke pixel van een beeld analyseren. Het knelpunt is dat deze modellen enorme, zorgvuldig gelabelde trainingsdatasets vereisen—meestal gemaakt doordat mensen onkruiden in elk beeld met de hand omlijnen. Deze studie vraagt: kunnen we die handmatige labeling stap volledig overslaan?
Een droneblik op tarwe en onkruid
De onderzoekers werkten op een experimenteel tarweveld van 2.000 vierkante meter nabij Saskatoon, Canada. Tarwe was in rechte rijen geplant en stroken met verschillende onkruidsoorten—onder meer kochia, akkerhaver, kruiskruid en valse kleefkruid—waren opzettelijk tussen de rijen ingezaaid. Een drone met een hoge-resolutie RGB-camera vloog 10 meter boven de grond en legde beelden vast die zo gedetailleerd waren dat elke pixel minder dan een millimeter op het veld voorstelde. Deze beelden werden aan elkaar gekoppeld tot één orthofoto, in wezen een nauwkeurige kaartachtige weergave van het veld, die dienstdeed als invoer voor een geautomatiseerde computerworkflow.
Kleur en vorm omzetten in automatische labels
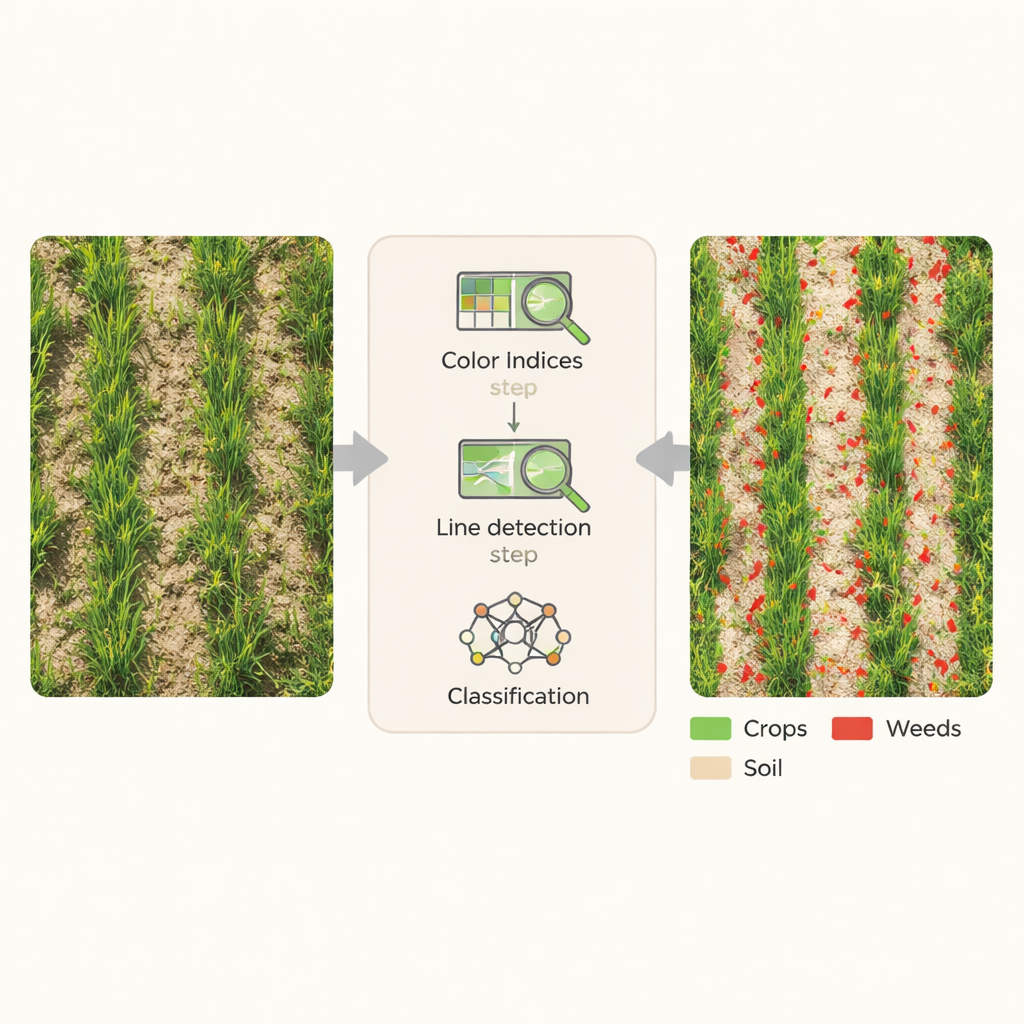
In plaats van een deep-learningmodel te trainen met duizenden handgelabelde voorbeelden, bouwde het team een kennisgebaseerde pijplijn binnen gespecialiseerde beeldanalysetools. Eerst verbeterden ze de afbeelding met eenvoudige kleurformules die groene planten tegenover bruin grond goed benadrukken. Indexen zoals de Excess Green Index en een Color Index of Vegetation werden gecombineerd om vegetatie duidelijk van kale grond te scheiden. Vervolgens zocht het systeem naar lange, dunne, lijnachtige structuren die overeenkomen met de vorm en oriëntatie van tarwebladeren en -rijen. Door het beeld onder veel hoeken te scannen en convolutiefilters toe te passen—wiskundige schuifvensters die terugkerende structuren accentueren—kon de workflow vaststellen waar de gewasrijen lagen en, in contrast daarmee, waar onkruid waarschijnlijk tussen of binnen die rijen groeide.
Van pixels naar onkruidkaarten zonder handmatig tekenen
Zodra gewasrijen en plantbedekte zones waren geïdentificeerd, paste de software automatische drempelwaarden toe om elke pixel in te delen in één van drie klassen: gewas, onkruid of kale grond. Schakbordachtige segmentatie en afstandsberekeningen tot de rij hielpen deze beslissingen te verfijnen, vooral op lastige plekken waar onkruid binnen de gewasrijen groeide. Belangrijk is dat al deze stappen volgens een vaste set regels verliepen—gebaseerd op agronomische kennis over hoe tarwe en onkruid eruitzien en waar ze groeien—zonder gebruik te maken van handmatig gelabelde trainingsvoorbeelden. De afbeelding werd efficiënt per kleine tegel verwerkt en vervolgens weer samengevoegd tot één volledig geclassificeerde kaart van het gehele veld.
Hoe nauwkeurig is “geen-training” onkruidmapping?
Om de methode te testen vergeleek het team hun geautomatiseerde kaart met duizenden willekeurige controlepunten in de veldbeelden, en met menselijke schattingen van onkruiddekking en tellingen. In totaal labelde de workflow 87% van de punten correct, en een statistische maat voor overeenstemming, bekend als kappa, was 0,81, wat als sterk wordt beschouwd. De detectie van onkruid had specifiek een gebruikersnauwkeurigheid van 76%, waarbij de meeste fouten optraden waar dichte gewas- en onkruiddaklagen overlappen. Toch volgden geautomatiseerde onkruiddekking en tellingen de menselijke veldbeoordelingen en visuele schattingen nauw, met sterke relaties die genoeg vertrouwen geven dat het systeem echte biologische patronen vastlegt en niet alleen ruis in de beelden.
Wat dit betekent voor toekomstige boerderijen
Dit werk toont aan dat hoogkwalitatieve onkruidkaarten geproduceerd kunnen worden uit dronebeelden met behulp van deskundige regels in plaats van handgelabelde trainingssets. Op een standaard desktopcomputer werd het vel van 2.000 vierkante meter volledig verwerkt in ongeveer 20 minuten. De resulterende gelabelde kaarten kunnen direct taken ondersteunen zoals het evalueren van herbicideprestaties, het aansturen van variabeldoserende spuitmachines, of het voeden van meer geavanceerde machine- en deep-learningmodellen met kant-en-klare trainingsdata. Voor zowel boeren als onderzoekers biedt dergelijke geautomatiseerde labeling een weg naar sneller, goedkoper en duurzamer onkruidbeheer, waardoor precisielandbouw dichter bij dagelijkse praktijk komt.
Bronvermelding: Ha, T., Aldridge, K., Johnson, E. et al. Automated weed segmentation with knowledge based labeling for machine learning applications. Sci Rep 16, 6220 (2026). https://doi.org/10.1038/s41598-026-37475-1
Trefwoorden: precisielandbouw, onkruidmapping, dronebeelden, geautomatiseerde labeling, gewasmonitoring