Clear Sky Science · nl
Een hiërarchisch conform raamwerk voor onzekerheidsbewuste voorspelling van ligduur in multi-ziekenhuisomgevingen
Waarom voorspellingen van ziekenhuisopnames ertoe doen
Wanneer iemand in het ziekenhuis wordt opgenomen, is een van de eerste vragen die familieleden en personeel stellen: “Hoe lang zullen ze hier blijven?” Het antwoord beïnvloedt veel meer dan nieuwsgierigheid: het bepaalt de beschikbaarheid van bedden, dienstroosters, plannen voor operatiekamers en zelfs of een patiënt veilig naar huis kan of extra ondersteuning nodig heeft. Dit artikel beschrijft een nieuwe manier om de ligduur te voorspellen die niet alleen een enkel getal geeft, maar ook een realistisch interval dat weergeeft hoe onzeker die voorspelling is — cruciaal voor veilige en efficiënte zorg.
De uitdaging van het voorspellen van verblijfsduur
Het voorspellen van ligduur is lastiger dan het lijkt. Ziekenhuizen behandelen een brede mix van patiënten, van routinematige gevallen tot complexe noodgevallen, en hun werkwijzen verschillen naar grootte, eigendom, opleidingsstatus en regio. Dit betekent dat patiënten “geclusterd” zitten binnen ziekenhuizen en regio’s, waardoor hun uitkomsten niet onafhankelijk zijn. Veel huidige machine-learningmodellen leveren een beste schatting maar geven weinig betrouwbaar inzicht in hoe groot de fout kan zijn. Voor ziekenhuisbestuurders die overbelaste afdelingen of lege bedden moeten vermijden, kan die ontbrekende onzekerheid leiden tot onveilige ontslagen, onnodige annuleringen of verspilde ‘voor het geval dat’-buffers.
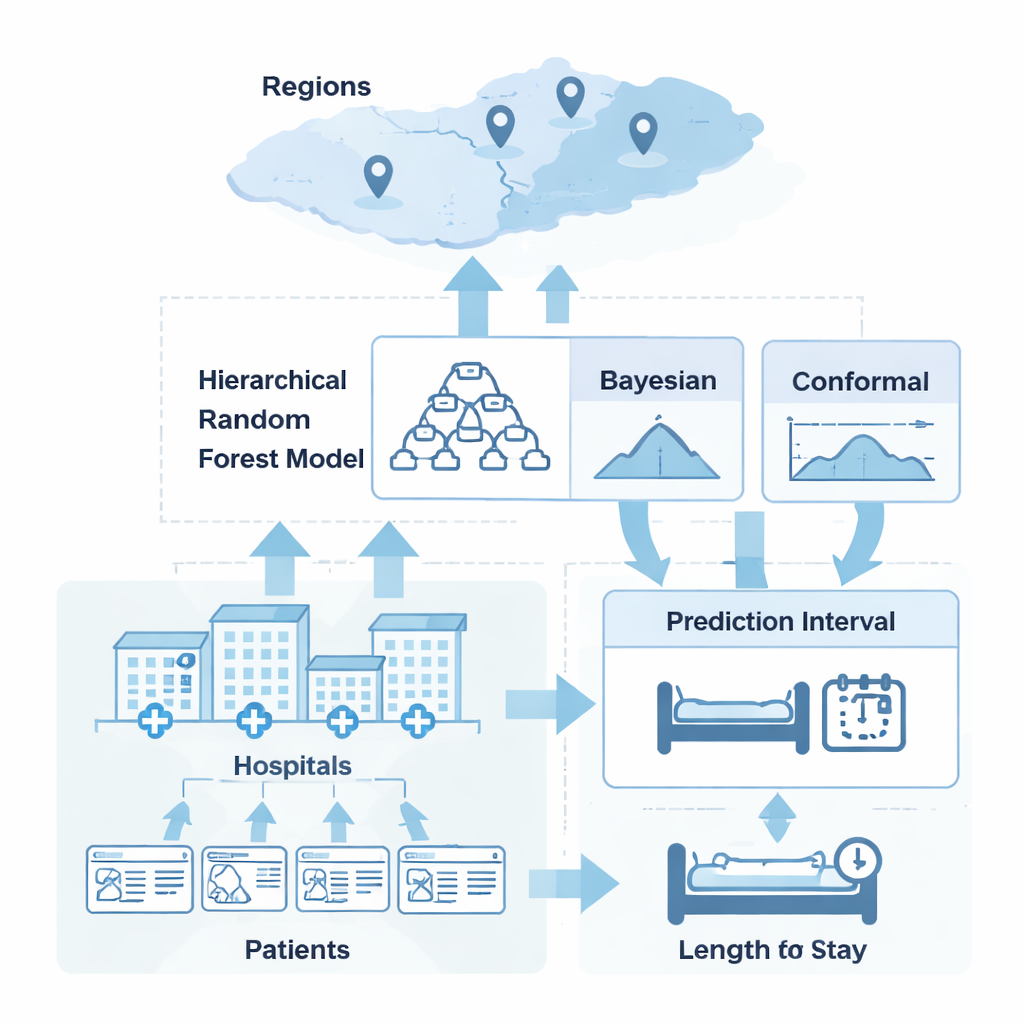
Het combineren van twee denkrichtingen over onzekerheid
De auteurs onderzochten twee gangbare manieren om onzekerheid vast te leggen en ontdekten dat beide op zichzelf serieuze nadelen hebben. Bayesiaanse methoden modelleren onzekerheid rechtstreeks en kunnen complexe structuren weergeven, zoals ziekenhuizen genest binnen regio’s, maar in de praktijk kunnen hun onzekerheidsintervallen overmoedig zijn wanneer modelaannames ook maar licht afwijken. Conformiteitsvoorspelling daarentegen doet bijna geen aannames over de data en kan garanderen dat haar intervallen het werkelijke resultaat een gekozen percentage van de tijd bevatten, maar meestal geeft het voor elke patiënt intervallen van gelijke breedte en negeert het hoe moeilijk of gemakkelijk een bepaald geval te voorspellen is. Het kernidee van dit werk is een hybride te creëren die iedere benadering gebruikt waarvoor zij het beste geschikt is: Bayesiaanse modellering om in te schatten welke patiënten meer of minder onzeker zijn, en conformiteitsvoorspelling om de algehele betrouwbaarheid van de intervallen te waarborgen.
Hoe het hybride systeem in de praktijk werkt
Het systeem begint met een “hiërarchisch random forest”, een boomgebaseerd machine-learningmodel dat patronen leert op drie niveaus: individuele patiënten, hun ziekenhuizen en de bredere regio’s waartoe die ziekenhuizen behoren. Vanuit deze basis bekijkt een Bayesiaanse laag de residuele fouten en schat in hoe onzeker elke nieuwe voorspelling is, rekening houdend met ziekenhuis- en regiokenmerken. Apart daarvan bepaalt een conforme kalibratiestap aan de hand van eerdere voorspellingsfouten over duizenden patiënten hoe breed de intervallen moeten zijn om een gewenste betrouwbaarheidsniveaus te bereiken — in deze studie ongeveer 95 procent. De hybride aanpak schaalt deze conforme aanpassingen omhoog voor gevallen die de Bayesiaanse laag als risicovol beoordeelt en omlaag voor gevallen die als eenvoudig worden gezien, waardoor patiëntspecifieke intervallen ontstaan die zowel voorzichtig als efficiënt van formaat zijn.
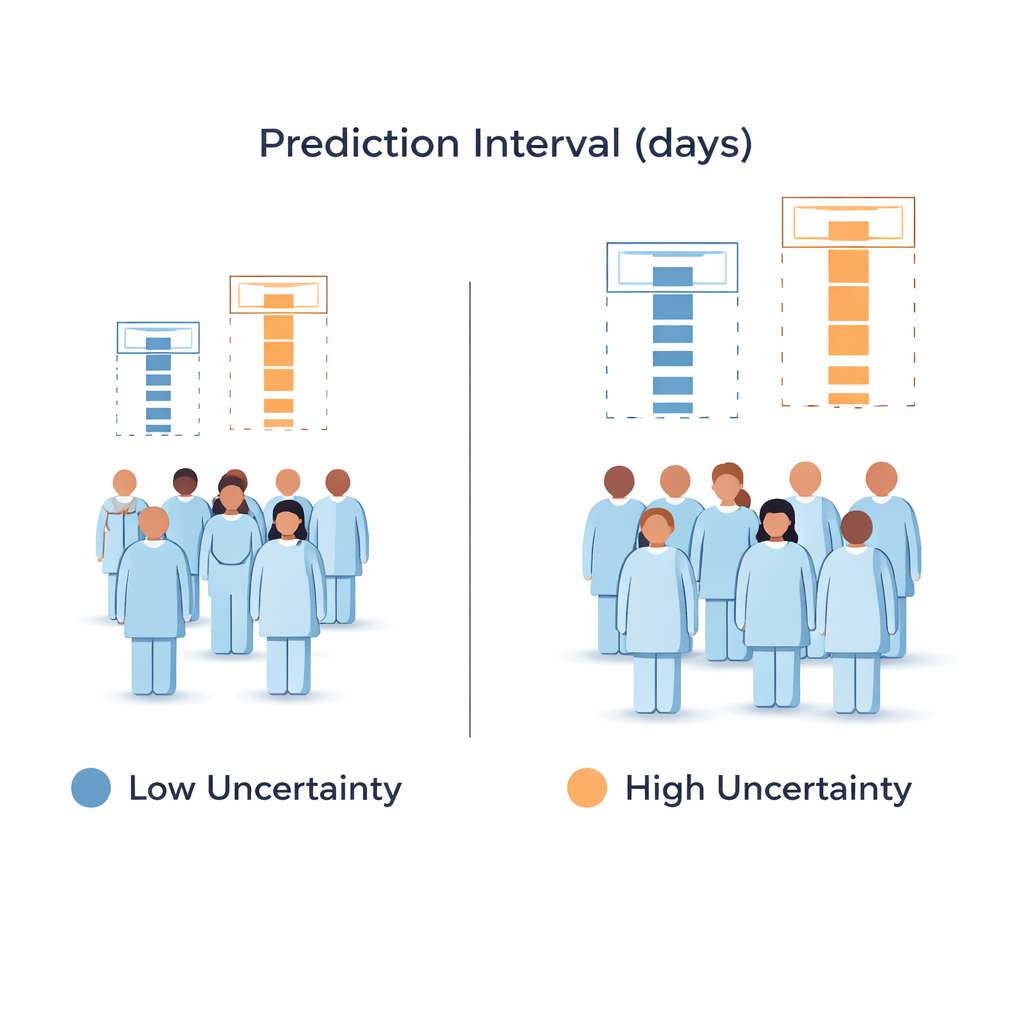
Wat de data zeggen over prestaties
De auteurs testten hun raamwerk op meer dan 61.000 ziekenhuisopnames uit bijna 3.800 Amerikaanse ziekenhuizen in een nationale opname-database. Pure conforme voorspelling behaalde bijna precies de 95 procent target maar gebruikte in wezen voor iedereen hetzelfde brede interval. Een puur Bayesiaanse toevoeging leverde zeer smalle intervallen op maar omvatte de werkelijke ligduur slechts in ongeveer 14 procent van de gevallen — veel te laag voor veilig gebruik. De hybride aanpak kwam dicht bij het doel en dekte ongeveer 94,3 procent van de gevallen, terwijl de gemiddelde interval bescheiden kleiner werd en, belangrijker, de breedte herverdeeld werd: ongeveer 21 procent smallere intervallen voor de minst onzekere patiënten en ongeveer 6 procent bredere voor de meest onzekere. Deze adaptieve intervallen bleven stabiel over verschillende typen ziekenhuizen en zelfs wanneer het model werd getest op volledig onbekende instellingen.
Wat dit betekent voor patiënten en ziekenhuizen
Voor niet-specialisten is de belangrijkste conclusie dat deze methode zwart‑doosvoorspellingen verandert in instrumenten met begrijpelijke en betrouwbare foutmarges. In plaats van één wankel getal krijgen ziekenhuizen intervallen die statistisch onderbouwd zijn en meebewegen met de moeilijkheid van het geval: strakker voor routinematige patiënten, ruimer voor degenen die clinici kunnen verrassen. Dit maakt het realistischer plannen van bedden en personeel eenvoudiger en helpt tegelijk te signaleren welke patiënten extra aandacht en noodplanning verdienen. Hoewel de huidige intervallen in kalenderdagen nog vrij breed zijn, toont het raamwerk aan hoe zorgvuldige statistiek ziekenhuizen kan verschuiven van gokken naar meer betrouwbare, onzekerheidsbewuste beslissingen die zowel veiligheid als efficiëntie ondersteunen.
Bronvermelding: Shahbazi, M.A., Baheri, A. & Azadeh-Fard, N. A hierarchical conformal framework for uncertainty-aware length of stay prediction in multi-hospital settings. Sci Rep 16, 6564 (2026). https://doi.org/10.1038/s41598-026-37450-w
Trefwoorden: ligduur in het ziekenhuis, kwantificatie van onzekerheid, conforme voorspelling, Bayesiaanse modellering, zorganalyses