Clear Sky Science · nl
Verbetering van medische kennisrepresentatie in grote taalmodellen door optimalisatie van klinische tokens
Waarom slimmer medisch lezen ertoe doet
Achter elke medische AI-assistent schuilt een eenvoudige maar cruciale vaardigheid: hoe hij tekst opsplitst in stukjes die hij kan begrijpen. Als dat "hakwerk" misgaat — vooral bij complexe Chinese medische termen — kan de AI belangrijke ideeën in doktersnotities of patiëntvragen missen. Dit artikel toont aan dat een kleine maar gerichte wijziging in die eerste stap grote taalmodellen beter kan maken in het lezen, redeneren over en beantwoorden van vragen over Chinese medische gegevens, zonder dat er een volledig nieuw systeem gebouwd hoeft te worden.
Tekst op de juiste manier in stukken verdelen
Moderne taalmodellen lezen niet direct karakters of woorden; ze zetten tekst eerst om in korte eenheden die tokens worden genoemd. Voor het Engels werkt dat redelijk goed, omdat spaties al woordgrenzen aangeven. Chinees is lastiger: er zijn geen spaties en veel medische uitdrukkingen zijn lange, gespecialiseerde zinnen. Standaard-tokenizers, voornamelijk ontworpen voor Engels, hebben de neiging deze uitdrukkingen in vele willekeurige fragmenten te snijden. Wanneer een model een ziektenaam of een labtest in meerdere losse stukken ziet, heeft het meer moeite te leren wat die term werkelijk betekent, en kunnen de antwoorden op medische vragen vaag of onnauwkeurig worden.
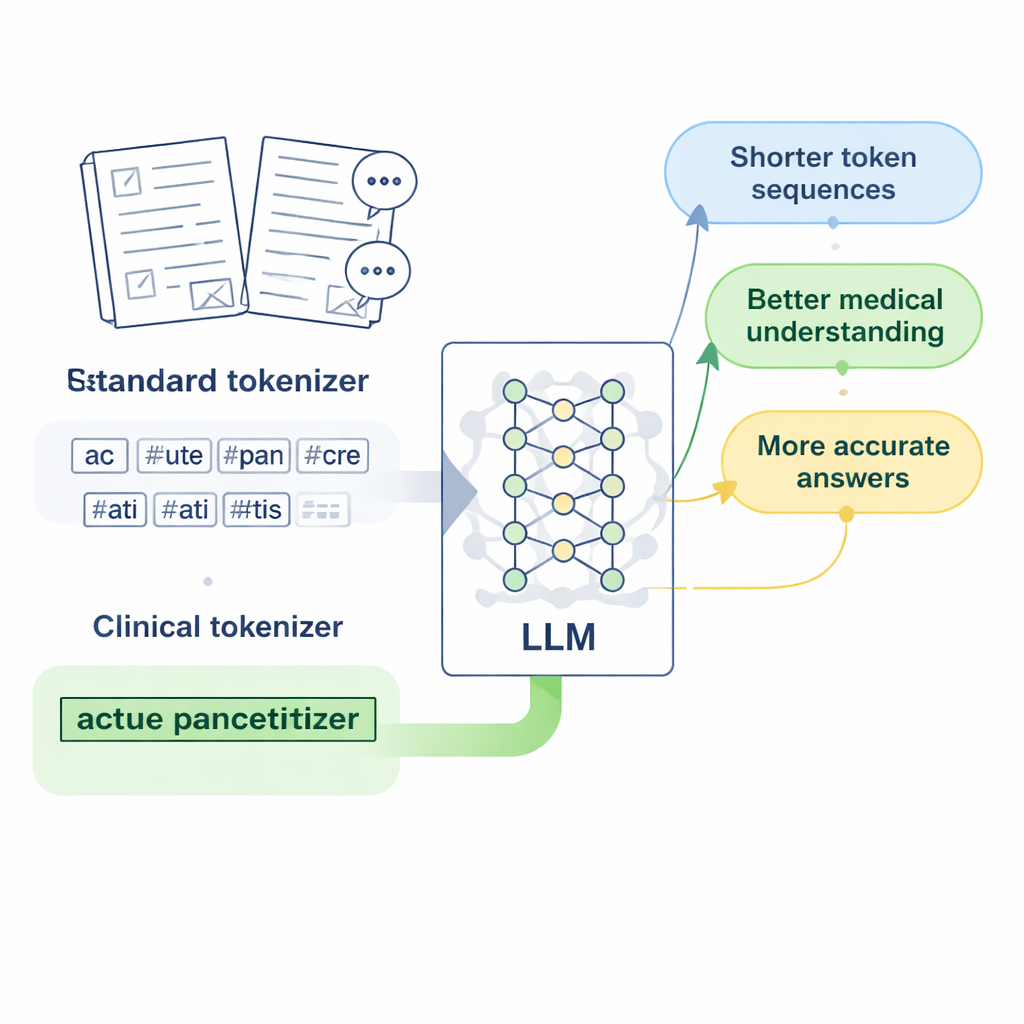
Het ontwerpen van "klinische tokens" voor Chinese geneeskunde
De onderzoekers richten zich op LLaMA2, een populair open-source groot taalmodel, en vragen: wat als we zijn tokenizer simpelweg een rijkere medische woordenschat leren? Ze verzamelen grote verzamelingen Chinese medische tekst, waaronder zorgvuldig bewerkte traditionele Chinese geneeskunde-databases, duizenden klinische dossiers en dokter-patiënt vraag-en-antwoordparen. Met een byte-level versie van het Byte Pair Encoding-algoritme, geïmplementeerd met het SentencePiece-hulpmiddel, trainen ze een nieuwe tokenizer die leert veelvoorkomende medische uitdrukkingen als enkele eenheden te behouden. Deze nieuwe eenheden, die de auteurs "klinische tokens" noemen, worden vervolgens in LLaMA2’s originele vocabulaire samengevoegd, waardoor het beter de Chinese medische taal dekt zonder weg te gooien wat het model al wist.
Van betere tokens naar een beter medisch model
Het toevoegen van nieuwe tokens is slechts de eerste stap; het model moet goede representaties voor die tokens leren. Het team past LLaMA2’s interne embedlaag aan zodat het vectoren voor het uitgebreid vocabulaire kan opslaan en test twee manieren om deze nieuwe vectoren te initialiseren. De ene methode gemiddeld de vectoren van oudere substukken van elk woord, terwijl de andere zorgvuldig geschaalde willekeurige waarden gebruikt. Tegenintuïtief presteert de willekeurige methode beter, waarschijnlijk omdat deze voorkomt dat het model vastloopt in een slechte initiële inschatting van de betekenis van elk woord. De auteurs trainen het model daarna verder op medische tekst en fijnslijpen het op instructiestijl medische Q&A met een hulpbron-efficiënte methode genaamd LoRA, wat resulteert in een gespecialiseerde versie die ze Medical-LLaMA noemen.
Het meten van winst in snelheid, context en nauwkeurigheid
Met het uitgebreide vocabulaire vereist elk Chinees karakter nu ongeveer de helft minder tokens dan eerder, wat betekent dat het model langere passages kan verwerken binnen hetzelfde vaste tokenvenster. In de praktijk verdubbelt de effectieve Chinese contextlengte ruwweg en wordt de fijnstijltijd op een grote medische Q&A-set bijna gehalveerd. Om de antwoordkwaliteit te beoordelen combineren de auteurs twee evaluatiestrategieën: BERTScore, dat meet hoe semantisch dicht een gegenereerd antwoord bij een referentie staat, en een geavanceerd beoordelingsmodel (DeepSeek-R1) dat relevantie, nauwkeurigheid, volledigheid en vloeiendheid scoort. Over deze maatstaven heen verslaat Medical-LLaMA consequent zowel de originele LLaMA2 als een Chinees-geoptimaliseerde variant die geen medische-specifieke tokens bevatte. Het laat ook kleine maar gestage verbeteringen zien bij gerelateerde taken zoals het herkennen van medische entiteiten en het classificeren van klinische tekst, terwijl de prestaties op algemene, niet-medische vragen behouden blijven.
Wat dit betekent voor toekomstige medische AI
Voor niet-specialisten is de kernboodschap dat slimmere "leesbrillen" voor AI — hier een betere manier om medische taal op te delen — merkbaar kan verbeteren hoe goed het gezondheidsvragen begrijpt en beantwoordt. Door zorgvuldig gekozen klinische tokens in het vocabulaire van een bestaand model in te voegen, verhogen de auteurs zowel efficiëntie als nauwkeurigheid zonder enorme nieuwe trainingsruns of volledig nieuwe architecturen nodig te hebben. Hoewel het werk beperkt is tot een model met 7 miljard parameters en Chinese medische tekst, wijst het op een praktisch recept: pas de vroegste laag van taalverwerking aan op het domein en train vervolgens licht bij. Deze strategie kan toekomstige medische AI-hulpmiddelen helpen betrouwbaardere partners te worden voor clinici en patiënten, vooral in talen en specialismen die standaardmodellen moeilijk lezen.
Bronvermelding: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
Trefwoorden: medische taalmodellen, Chinese klinische tekst, tokenisatie, klinische woordenschat, medische vraag-antwoord systemen