Clear Sky Science · nl
RiemannInfer: verbetering van transformer‑inference via Riemanniaanse geometrie
Waarom dit belangrijk is voor alledaagse AI‑gebruikers
Moderne chatbots en AI‑assistenten kunnen wiskundeproblemen oplossen, essays schrijven en zelfs medische onderwerpen uitleggen, maar we weten nog steeds niet goed hoe ze tot hun conclusies komen—of hoe we hun redeneringen betrouwbaarder kunnen maken. Dit artikel introduceert “RiemannInfer”, een nieuwe manier om binnen grote taalmodellen (LLM’s) te kijken door hun interne activiteit te behandelen als beweging op een gekromd geometrisch oppervlak. Dat perspectief biedt niet alleen een intuïtiever beeld van hoe deze systemen denken, maar maakt hun redeneren ook sneller en nauwkeuriger.
AI‑denken als een geometrische reis
Binnen een LLM zoals GPT‑4 of Llama wordt elk woord in een zin gerepresenteerd door een vector met hoge dimensie, en lagen van “attention” bepalen hoe sterk woorden elkaar beïnvloeden. De auteurs merken op dat deze verborgen toestanden gezien kunnen worden als punten in een uitgestrekte ruimte waarvan de globale vorm het begrip van taal door het model encodeert. In plaats van redeneren te zien als een reeks waarschijnlijkheidsberekeningen over tekst, herinterpreteren zij het als een padvondstprobleem: het model reist van een initiële toestand (de vraag) naar een eindtoestand (het antwoord) langs een route in deze ruimte. Met hulpmiddelen uit de Riemanniaanse geometrie—de wiskunde van gekromde oppervlakken—construeren ze een gekromde variëteit die vastlegt hoe aandachtspatronen dit interne landschap buigen en rekken.
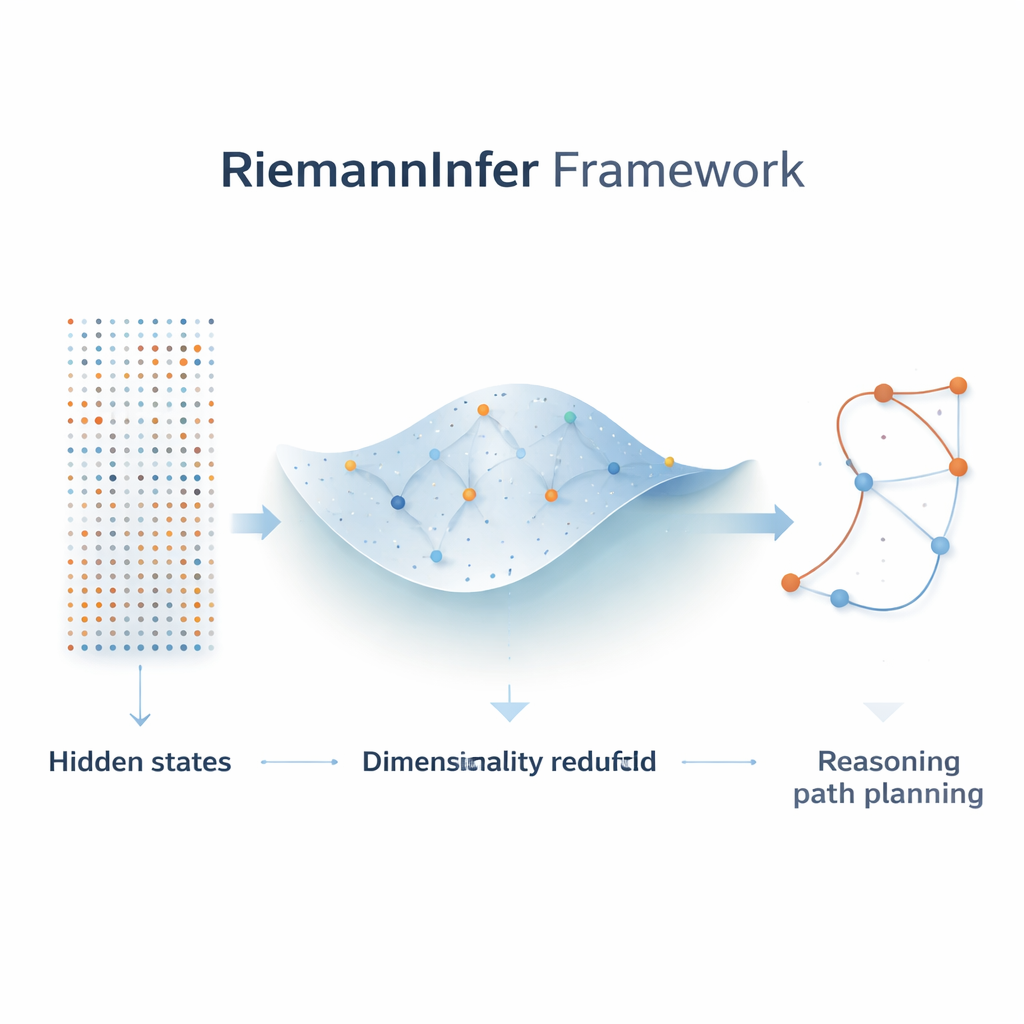
Complexiteit comprimeren zonder het grotere geheel te verliezen
Aangezien de ruwe interne ruimte van een LLM enorm is, is de eerste stap in RiemannInfer deze te verkleinen terwijl de essentiële structuur behouden blijft. De auteurs combineren technieken uit de topologie, die onderzoekt hoe punten met elkaar verbonden zijn, met een populaire dimensiereductie‑algoritme genaamd UMAP. Voordat ze het aantal dimensies verminderen, analyseren ze de “vorm” van de wolk van verborgen toestanden om te garanderen dat belangrijke connectiviteits‑patronen de compressie overleven. Het resultaat is een lager‑dimensionale ruimte waarin belangrijke relaties tussen tokens—zoals welke woorden sterk aandacht aan elkaar geven—grotendeels bewaard blijven. Deze compacte geometrische kaart maakt het haalbaar om precieze berekeningen te doen over afstanden, kortste paden en kromming.
Een gekromde kaart bouwen uit attention
De kerninnovatie is het omzetten van attention‑gewichten in een geometrische maat voor afstand. Wanneer het model sterke aandacht tussen twee tokens toont, behandelt RiemannInfer die als dicht bij elkaar op de variëteit; zwakke aandacht plaatst ze verder uit elkaar. Vanuit deze relaties definiëren de auteurs een metriek—een wiskundige regel die lengtes en hoeken bepaalt—en gebruiken die om geodeten te berekenen, de gekromde tegenhangers van rechte lijnen, evenals kromming, die meet hoe scherp de ruimte buigt. Multi‑head attention wordt op natuurlijke wijze een mengsel van meerdere metriekcomponenten, elk die een ander aspect van taalkundige structuur vastlegt, zoals grammatica of betekenis. Met deze constructie kunnen modelbeslissingen worden geïnterpreteerd als het kiezen van bepaalde paden door een landschap waarvan pieken en dalen weergeven waar informatie dicht of schaars is.
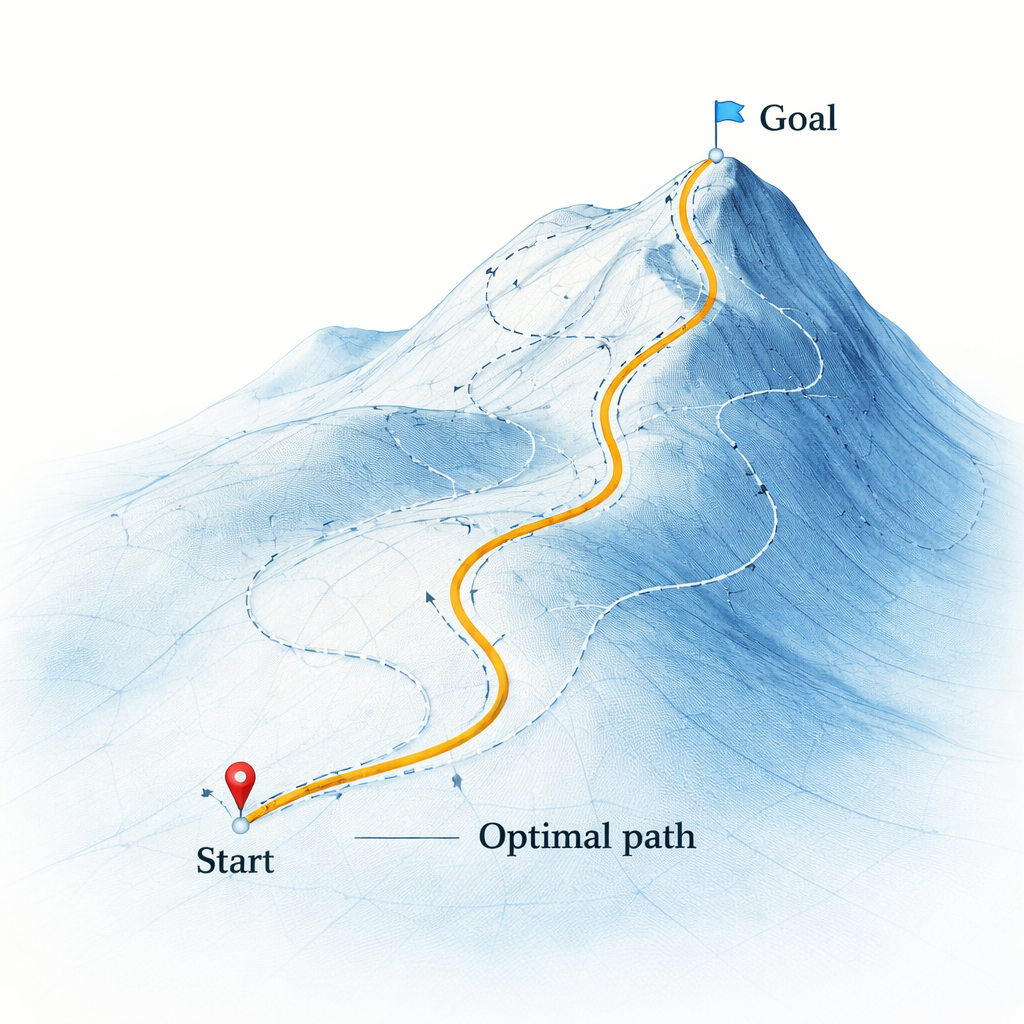
Plannen van laag‑inspanning redeneringspaden
Zodra de variëteit is opgebouwd, herformuleren de auteurs redeneren als het vinden van een “makkelijk” pad van vraag naar antwoord—een pad dat de totale arbeid langs de route minimaliseert. Ze lenen een analogie uit het bergbeklimmen: een steile, ruwe route vergt meer energie dan het volgen van een vloeiendere rug naar dezelfde top. In de LLM‑context speelt kromming de rol van steilheid, en komt de redeneringsarbeid van het model overeen met hoeveel interne onzekerheid langs een pad wordt teruggedrongen. Met behulp van benaderende formules voor geodeten en kromming, gecombineerd met een efficiënte grafzoekalgoritme (Dijkstra’s algoritme), identificeert RiemannInfer snel routes die deze arbeid minimaliseren en leidt het model effectief naar efficiëntere denkpaden.
Wat de experimenten laten zien voor echte modellen
De auteurs testen RiemannInfer op verschillende state‑of‑the‑art LLM’s, waaronder GPT‑4o, Llama‑3‑405B en DeepSeek‑V2‑400B, op veeleisende wiskunde‑ en redeneerbenchmarks zoals GSM8K, MATH500, StrategyQA en AGIEval. In elk geval verhoogt het inpakken van deze modellen met het RiemannInfer‑kader hun nauwkeurigheid met enkele procentpunten—kleine verschillen die desalniettemin betekenisvol zijn aan de prestatiegrens—terwijl de snelheid behouden blijft of licht verbetert. Een vergelijking met een eenvoudiger, puur lineaire methode toont dat het negeren van de gekromde geometrie van de verborgen toestanden de prestaties sterk schaadt, wat het belang van het variëteits‑perspectief onderstreept.
Groot geheel: AI‑redenering een fysiek gevoel geven
Voor een brede lezer is de belangrijkste conclusie dat de auteurs de ondoorzichtige interne werking van grote taalmodellen hebben omgezet in iets tastbaars: een reis over een gekromd landschap waar goed redeneren overeenkomt met het volgen van vloeiende, laag‑inspanningspaden. Door aandachtspatronen en redeneerstappen te funderen in geometrische en fysieke concepten—afstand, kromming en arbeid—biedt RiemannInfer zowel een praktische manier om resultaten te verbeteren als een conceptuele brug tussen AI en de fysica van continue ruimten. Hoewel de huidige methoden benaderend zijn en veel details nog verfijnd moeten worden, wijst dit kader op toekomstige AI‑systemen waarvan de denkprocessen geanalyseerd, geoptimaliseerd en mogelijk zelfs ontworpen kunnen worden met het taalgebruik van geometrie en natuurkunde.
Bronvermelding: Mao, R., Zhang, Z., Yang, M. et al. RiemannInfer: improving transformer inference through Riemannian geometry. Sci Rep 16, 6636 (2026). https://doi.org/10.1038/s41598-026-37328-x
Trefwoorden: grote taalmodellen, geometrische deep learning, Riemanniaanse variëteit, aandachtmechanismen, redeneringsefficiëntie