Clear Sky Science · nl
Prestatie-evaluatie van generatieve voorgetrainde transformer op het Nationale Veterinaire Licentie-examen in Japan
Waarom slimmere veterinaire examens iedereen aangaan
Achter elk bezoek aan het dierenziekenhuis schuilen jaren van intense opleiding en een hoog inzetend nationaal examen. In Japan moeten aspirant‑dierenartsen slagen voor het National Veterinary Licensing Examination (NVLE), dat alles test van basisbiologie tot complex klinisch oordeel. Deze studie stelde een actuele vraag: kunnen de geavanceerde AI‑taalmodellen van vandaag, hetzelfde soort dat populaire chatbots aandrijft, dit veeleisende examen in het Japans oplossen — en wat zou dat kunnen betekenen voor veterinaire opleiding en dierzorg?
AI testen op een echt veterinaire licentie-examen
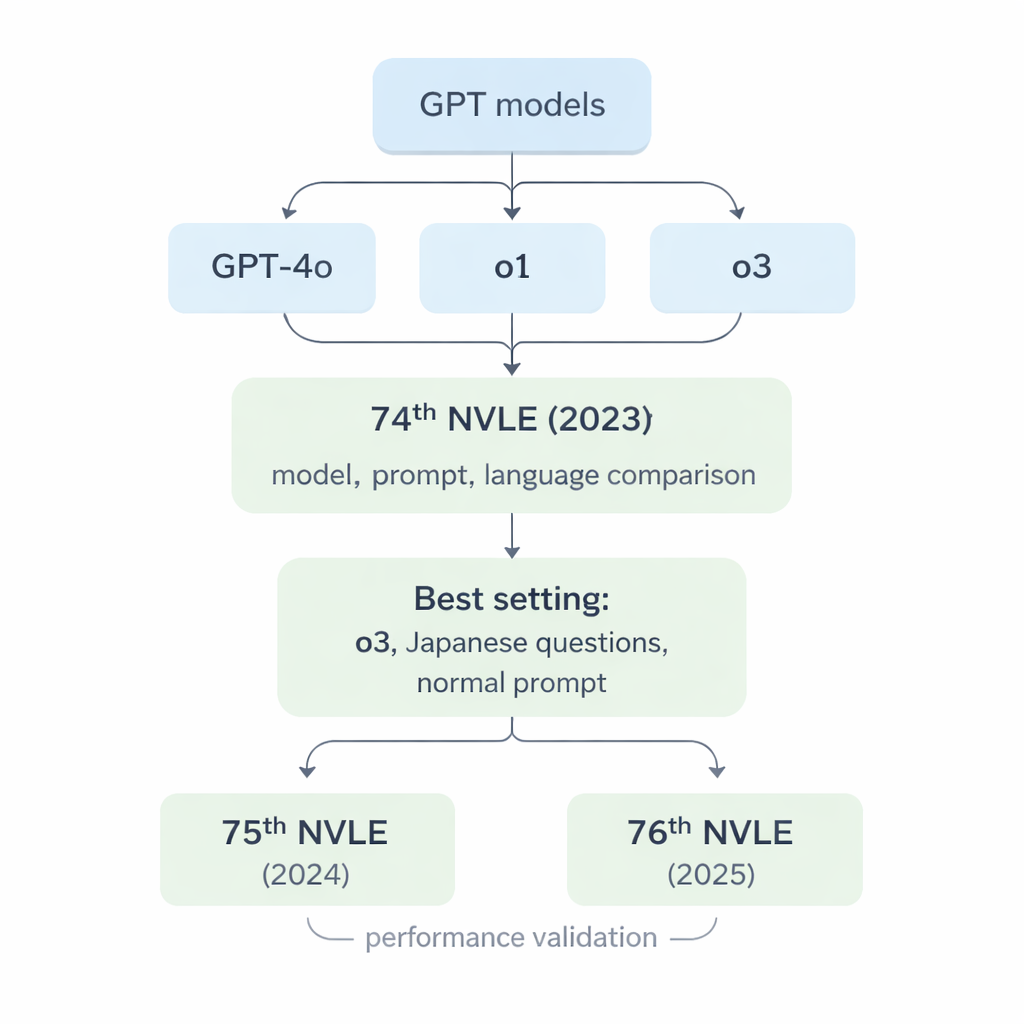
De onderzoekers concentreerden zich op drie generaties grote taalmodellen van OpenAI: GPT‑4o, o1 en o3. Deze systemen zijn ontworpen om mensachtige tekst te lezen en te genereren, maar ze zijn niet specifiek getraind in diergeneeskunde. Om ze te toetsen gebruikte het team de 74e NVLE van Japan (2023) als benchmark. Het examen is verdeeld in vijf onderdelen, waaronder alleen‑tekstvragen en beeldgebaseerde vragen met röntgenfoto’s, foto’s of diagrammen. Alle vragen zijn meerkeuze met vijf opties, net als het echte examen dat studenten afleggen. De modellen kregen elke vraag via een gestandaardiseerd computerscript en moesten alleen het gekozen optiesnummer teruggeven, zonder de mogelijkheid om te “verklaren” of hun antwoord te onderbouwen.
Welk AI‑model kwam als winnaar uit de bus?
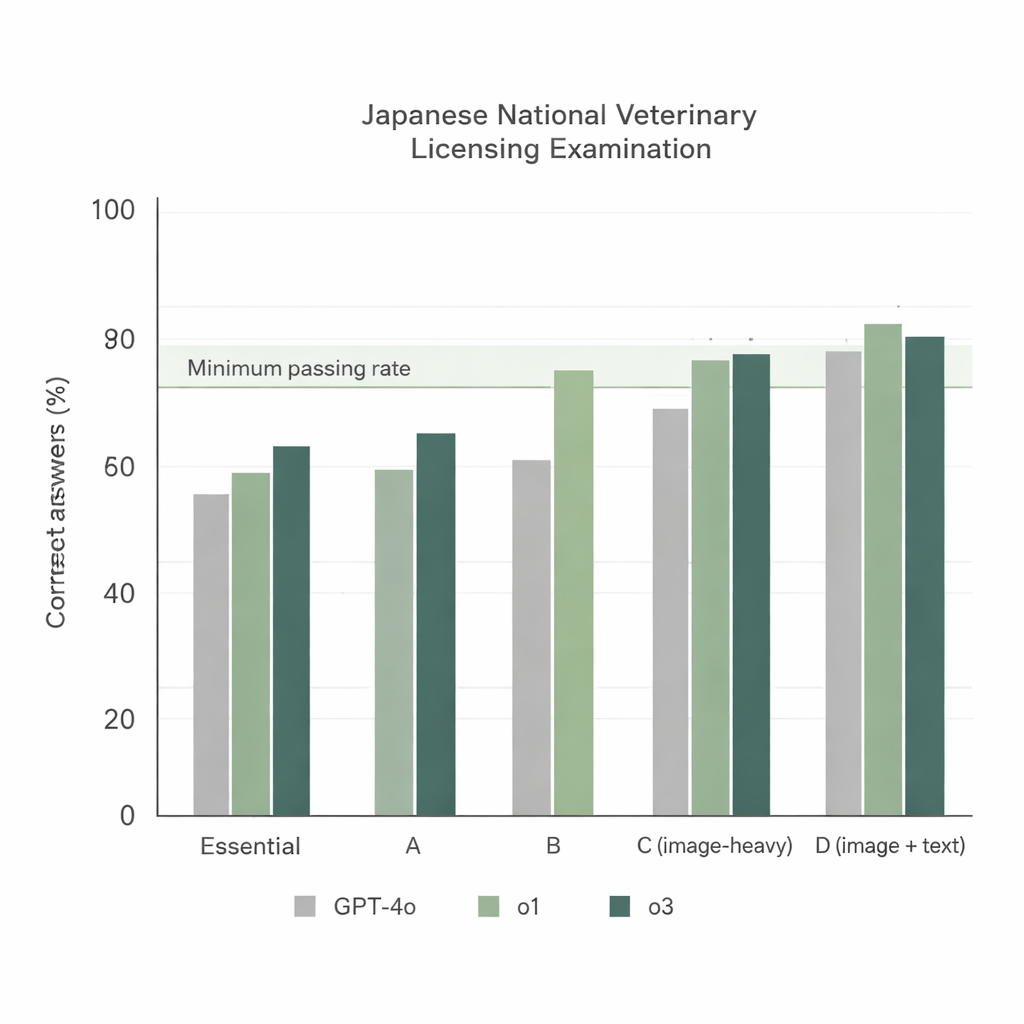
Toen de drie modellen de 74e NVLE met de eenvoudigste opzet aanpakten — Japanse vragen en een directe instructieprompt — kwamen twee duidelijke trends naar voren. Ten eerste presteerden alle modellen sterk op tekstgebaseerde onderdelen, maar o1 en o3 behaalden consequent hogere scores dan GPT‑4o. Ten tweede daalden de prestaties bij beeldzware onderdelen, maar o1 en o3 bleven boven de officiële minimumslagscore, terwijl GPT‑4o in één van deze onderdelen tekortschiet. In totaal beantwoordde GPT‑4o ongeveer 78% van de vragen correct, terwijl o1 ongeveer 92% en o3 ongeveer 93% behaalde. Omdat o3 o1 net iets versloeg in totaalscore, kozen de onderzoekers o3 voor de resterende experimenten.
Helpen prompts of vertalingen echt?
Er is veel geschreven over “prompt engineering” — het formuleren van uitgebreide instructies om betere antwoorden van AI te krijgen — en over het vertalen van lokale examenvragen naar het Engels om aan te sluiten bij de trainingsdata van modellen. De studie testte deze ideeën rechtstreeks met het o3‑model, door een basale oplossingsprompt te vergelijken met een gedetailleerdere, geoptimaliseerde prompt, en Japanse vragen te vergelijken met versies die eerst door hetzelfde model naar het Engels waren vertaald. Verrassend genoeg maakte geen van deze aanpassingen wezenlijk verschil: o3 slaagde ruim in alle zes combinaties, en de eenvoudigste aanpak (originele Japanse tekst met de basale prompt) presteerde even goed als de complexere opzetten. Dit suggereert dat, althans voor deze veterinaire vragen, de nieuwste modellen Japans al betrouwbaar begrijpen en geen ingewikkelde prompting nodig hebben om op hoog niveau te presteren.
Hoe stabiel zijn de prestaties op nieuwere examens?
Om te onderzoeken of de sterke resultaten toevallig waren, gaf het team o3 vervolgens de 75e (2024) en 76e (2025) NVLE’s, opnieuw alleen met de originele Japanse vragen en de normale prompt. Het model behaalde op beide examens totaalscores boven 92% en overschreed de slaagdrempel in elk onderdeel, inclusief de beeldzware gebieden. De meeste vragen kregen dezelfde antwoordkeuze in drie onafhankelijke runs, wat aantoont dat o3’s antwoorden over het algemeen stabiel waren, zelfs wanneer enige willekeur werd toegelaten. Bij nader onderzoek van de fouten bleek dat die clusterden in twee gebieden: praktisch veterinaire kennis (zoals Japanse veterinaire wetten) en klinische geneeskunde, die landenspecifieke regels en meerstapsredenering vereisen in plaats van eenvoudige feitereproductie.
Wat dit betekent — en wat niet
De studie concludeert dat moderne GPT‑achtige modellen nu het Japanse veterinair licentie-examen kunnen halen, zonder vertaaltrucs of complexe prompts. Voor veterinaire scholen en studenten opent dit de deur naar het gebruik van AI als studiepartner, vraaggenerator of uitleggever van examengerelateerde onderwerpen. Voor het publiek geeft het aan dat AI een krachtig hulpmiddel wordt voor het ordenen en delen van veterinaire kennis. De auteurs benadrukken echter dat deze systemen nog niet gereed zijn om dierenartsen te vervangen of zelfstandig medische beslissingen te nemen. De modellen kunnen afbeeldingen nog verkeerd interpreteren, moeite hebben met genuanceerd klinisch oordeel en soms feiten verzinnen. Bij zorgvuldig gebruik kunnen ze waardevolle assistenten worden in veterinaire educatie en informatiedeling — maar de verantwoordelijkheid voor de diergezondheid blijft stevig in menselijke handen.
Bronvermelding: Kako, T., Kato, D., Iguchi, T. et al. Performance evaluation of generative pre-trained transformer on the National Veterinary Licensing Examination in Japan. Sci Rep 16, 4306 (2026). https://doi.org/10.1038/s41598-026-37300-9
Trefwoorden: veterinaire licentieexamens, grote taalmodellen, kunstmatige intelligentie in de geneeskunde, GPT-prestaties, Japanse veterinaire opleiding