Clear Sky Science · nl
Een hybride kader voor kenmerkselectie en uitlegbaarheid voor de voorspelling van opgeloste zuurstof in waterzuiveringsinstallaties voor drinkwater
Waarom zuurstof in drinkwater ertoe doet
Opgeloste zuurstof—de kleine belletjes zuurstofgas gemengd in water—bepaalt stilletjes of ons drinkwater helder, veilig en smakelijk blijft. Te weinig zuurstof in het bronwater kan metalen zoals ijzer en mangaan vrijmaken, schadelijke microben bevorderen en de behandeling moeilijker en duurder maken. Deze studie laat zien hoe slim gebruik van werkelijke bedrijfsgegevens en moderne machine learning zuurstofniveaus in een grote drinkwaterinstallatie kan voorspellen, waardoor operators de waterkwaliteit hoog kunnen houden en tegelijk tijd, energie en laboratoriumkosten besparen.
Leven blazen in waterzuivering
In veel stuwmeren en rivieren schommelen de zuurstofniveaus met seizoenen, vervuiling en waterbeweging. Wanneer water stil komt te staan of te veel voedingsstoffen bevat, kan de zuurstof dalen en zo omstandigheden creëren die ongewenste stoffen uit sedimenten vrijmaken en probleemgevende microben bevoordelen. In drinkwaterzuiveringsinstallaties is het handhaven van gezonde zuurstofniveaus vooral belangrijk voor biologische filters en ter voorkoming van het vrijkomen van metalen en andere verbindingen die moeilijk te verwijderen zijn. Toch hebben de meeste eerdere studies zich gericht op rivieren of rioolwaterzuiveringen, waardoor een kenniskloof blijft voor gezuiverde drinkwatersystemen, waar processtappen zoals coagulatie, filtratie en chloorbehandeling het zuurstofgedrag op unieke wijze veranderen.
Tien jaar aan data van rivier tot kraan
De onderzoekers gebruikten tien jaar aan dagelijkse gegevens van een grootschalige waterzuiveringsinstallatie in Ahvaz, Iran, die water uit de Karun-rivier behandelt voor ongeveer 450.000 mensen. Zij gebruikten zeven routinematig gemeten eigenschappen van het gefilterde instroomwater—historische opgeloste zuurstof, nitriet, chloride, elektrische geleidbaarheid, troebelheid, pH en temperatuur—om het zuurstofniveau in het uitlaatbekken van de installatie te voorspellen. Na zorgvuldige controle van de data, het behandelen van uitbijters en het standaardiseren van de metingen, trainden ze twee populaire boomgebaseerde machine learning-modellen, Random Forest en XGBoost. Deze modellen leren patronen door veel beslissingsbomen te bouwen en hun resultaten te combineren, waardoor ze complexe, niet-lineaire relaties kunnen vastleggen zonder handgemaakte vergelijkingen nodig te hebben. 
De signalen vinden die er echt toe doen
Een belangrijke uitdaging was beslissen welke van de zeven invoermetingen werkelijk het zuurstofgedrag aansturen en welke ruis of onnodige complexiteit toevoegen. In plaats van op één rangschikkingsmethode te vertrouwen, bouwde het team een "hybride" selectieprocedure die de data vanuit meerdere invalshoeken bekeek. Mutual Information benadrukte variabelen die het sterkst verband hielden met zuurstof, Mean Decrease in Impurity toonde welke metingen binnen de bomen het meest bruikbaar waren, en Permutation Importance testte hoeveel de voorspellingen verslechterden wanneer de waarden van een variabele werden door elkaar gehusseld. Daarnaast verklaarde de SHAP-methode, geval voor geval, hoe elk kenmerk de voorspelling omhoog of omlaag duwde, wat zowel globale als casusspecifieke inzichten gaf. Over alle vier technieken heen vielen drie invoeren duidelijk op: het zuurstofniveau van de voorgaande dag, watertemperatuur en troebelheid. Maten zoals pH en nitriet, hoewel wetenschappelijk interessant, droegen weinig bij aan het verbeteren van de voorspellingen in deze installatie.
Nauwkeurige voorspellingen met slankere modellen
Door te focussen op de meest informatieve invoeren en de minst nuttige te laten vallen, verminderden de onderzoekers de modelcomplexiteit met maximaal 70 procent terwijl de nauwkeurigheid vrijwel ongewijzigd bleef. Zowel Random Forest als XGBoost reproduceerden de gemeten uitlaat-zuurstofniveaus met hoge precisie, verklaarden meer dan 93 procent van de variatie en hielden typische fouten onder 0,3 milligram per liter—ruim binnen het bereik dat nuttig is voor dagelijkse operaties. XGBoost presteerde iets beter in het algemeen, maar beide modellen bleken robuust, zelfs wanneer de set invoeren werd verkleind. Deze efficiëntie is in de praktijk belangrijk: minder benodigde metingen betekenen lagere monitoringskosten en snellere, betrouwbaardere voorspellingen die in de besturingssystemen van de installatie kunnen worden geïntegreerd. 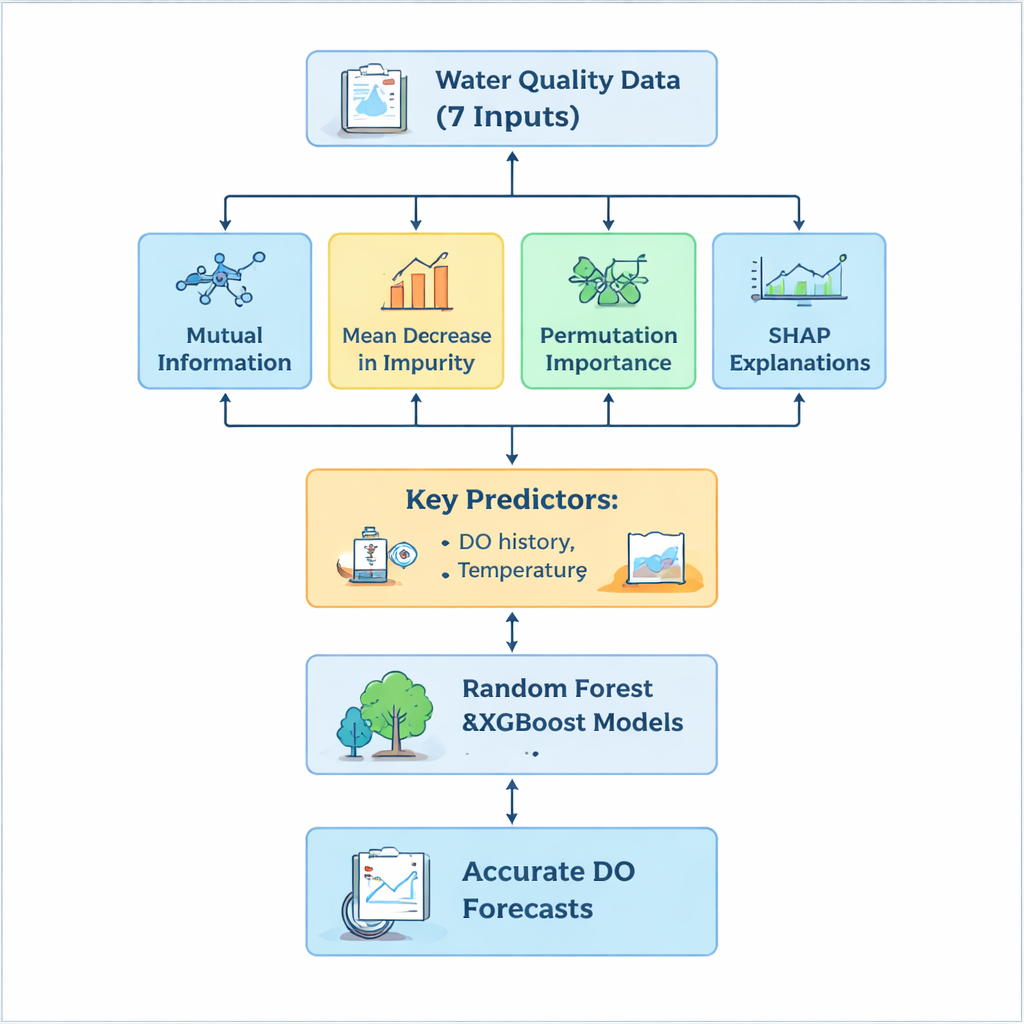
Wat dit betekent voor veilig, efficiënt drinkwater
Voor niet-specialisten is de kern eenvoudig: door verschillende data-gedreven methoden te laten "stemmen" over welke metingen het belangrijkst zijn, kunnen operators compacte, transparante voorspellingshulpmiddelen bouwen die opgeloste zuurstof in realtime betrouwbaar voorspellen. Het van tevoren weten wanneer zuurstof kan dalen stelt een installatie in staat beluchting bij te stellen, filters te beschermen en situaties te vermijden die metalen vrijmaken of schadelijke microben ondersteunen—en dat alles zonder onnodig energie- en chemicaliëngebruik. Buiten deze ene installatie en parameter kan dezelfde hybride aanpak worden toegepast op andere milieuvragen, van het volgen van verontreinigingen tot het voorspellen van algenbloei, en zo helderder en betrouwbaarder advies bieden waar waterkwaliteit en volksgezondheid elkaar raken.
Bronvermelding: Hoshyarzadeh, R., Hafshejani, L.D., Tishehzan, P. et al. A hybrid framework of feature selection and interpretability for dissolved oxygen prediction in drinking water treatment plants. Sci Rep 16, 6912 (2026). https://doi.org/10.1038/s41598-026-37276-6
Trefwoorden: opgeloste zuurstof, drinkwaterzuivering, machine learning, kenmerkselectie, waterkwaliteitsmonitoring