Clear Sky Science · nl
De invloed van de keuze van K in K‑fold cross‑validation op bias en variantie in gealloceerde leermodellen
Waarom je model twee keer controleren echt telt
Van medische diagnose tot kredietbeoordeling: veel beslissingen hangen nu af van machine‑learningmodellen die op historische gegevens zijn getraind. Maar hoe weten we of een model dat er op ons scherm goed uitziet, zich ook goed zal gedragen bij nieuwe, ongeziene gevallen? Een veelgebruikte manier om modellen te "testen" is k‑fold cross‑validation, waarbij data herhaaldelijk in trainings‑ en teststukken worden verdeeld. Deze studie stelt een schijnbaar eenvoudige maar cruciale vraag: hoeveel stukken—hoe groot moet k zijn—en hoe beïnvloedt die keuze stilletjes de betrouwbaarheid van de gerapporteerde modelprestaties?
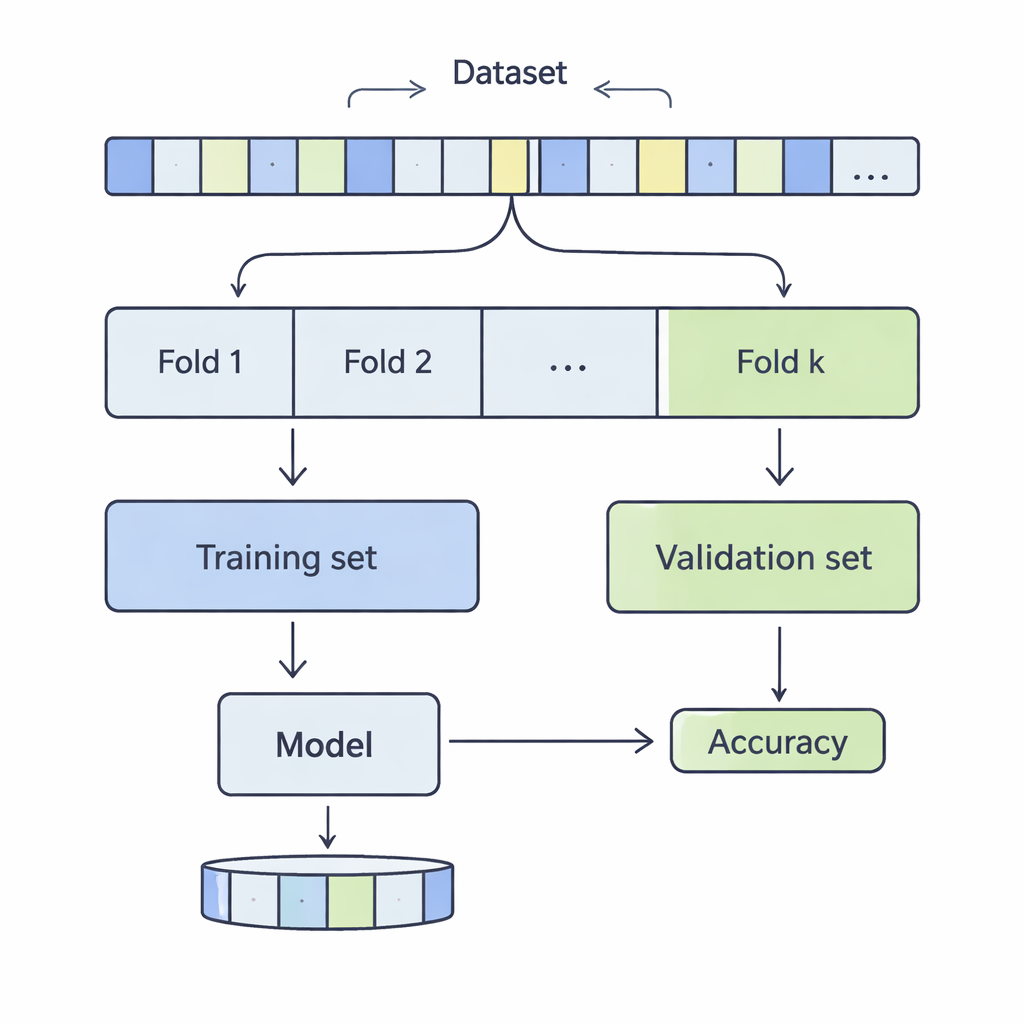
Hoe data worden gesneden voor een realiteitscheck
Bij k‑fold cross‑validation wordt een dataset geschud en verdeeld in k gelijke delen, of folds. Het model wordt getraind op k‑1 van die folds en geëvalueerd op de overgebleven fold; dit proces herhaalt zich totdat elke fold eenmaal als testset heeft gefungeerd. De auteurs onderzochten k‑waarden van 3 tot 20, over 12 datasets uit de praktijk variërend van enkele duizenden tot meer dan een half miljoen observaties, en met onderwerpen als inkomensvoorspelling, medische uitkomsten, cyberaanvallen, spellen en wijnkwaliteit. Ze paste vier gangbare classificatiemethoden toe—Support Vector Machines, Decision Trees, Logistic Regression en k‑Nearest Neighbours—en maten zorgvuldig hoe de keuze van k twee belangrijke aspecten van de prestatie beïnvloedde: bias en variantie.
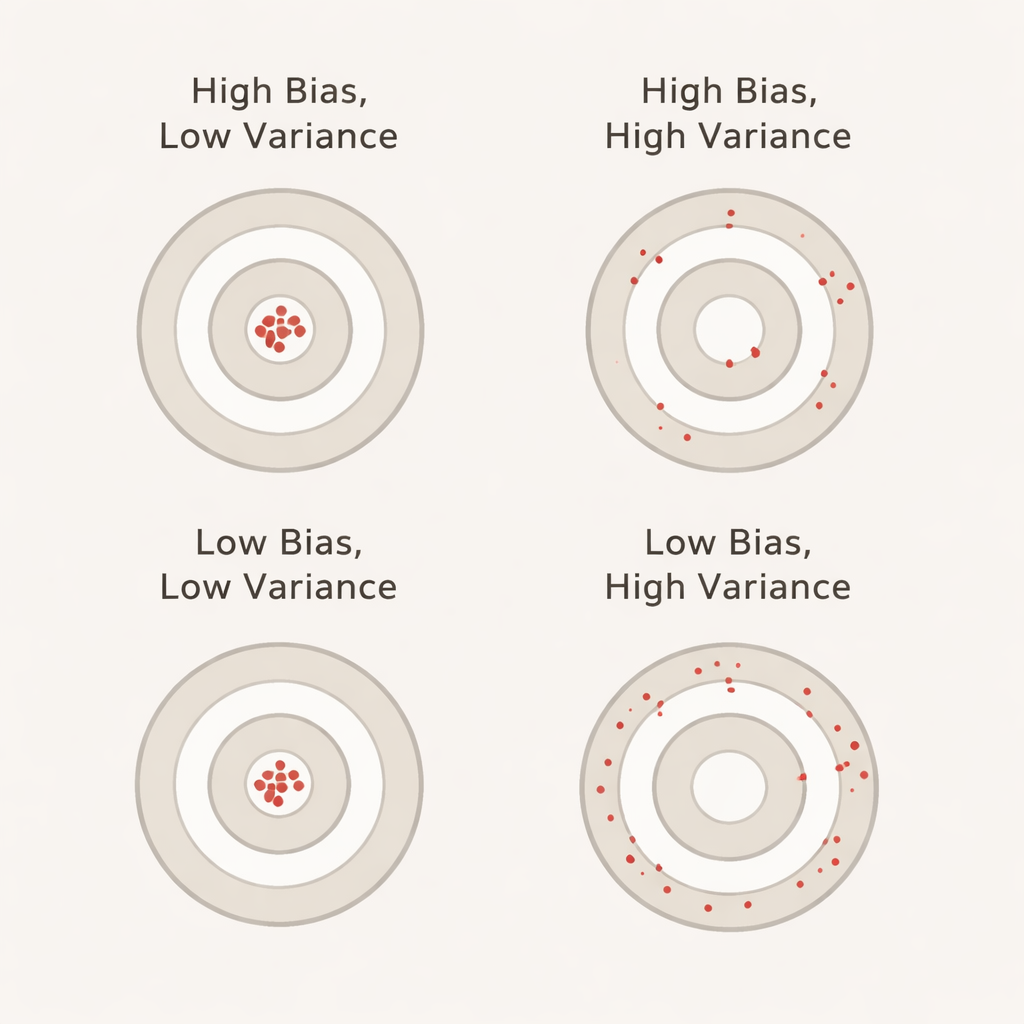
Wat bias en variantie in gewone taal betekenen
Bias beschrijft hier hoeveel beter het model tijdens cross‑validation lijkt te presteren dan het daadwerkelijk doet op een aparte, onaangeraakte testset. Een grote positieve bias betekent dat het model tijdens validatie te optimistisch oogt—vergelijkbaar met een student die oefentoetsen perfect maakt maar in het echte examen faalt. Variantie weerspiegelt hoeveel de prestaties van het model van fold tot fold schommelen: lage variantie betekent dat de scores stabiel zijn over verschillende dataportioneringen, terwijl hoge variantie grote fluctuaties aangeeft. Idealiter willen we zowel lage bias als lage variantie, zodat de gerapporteerde nauwkeurigheid zowel realistisch als consistent is.
Wat er gebeurt als we het aantal folds vergroten
Over alle twaalf datasets en alle vier algoritmen viel één patroon duidelijk op: naarmate k toenam, nam de variantie vrijwel altijd toe. Met andere woorden, meer folds maakte de gerapporteerde nauwkeurigheid minder stabiel van de ene fold naar de andere. Dit spreekt een veelgehoorde overtuiging tegen dat meer folds automatisch betere, betrouwbaardere schattingen opleveren. De reden is dat bij grote k elke validatie‑slice zeer klein en minder representatief wordt, waardoor resultaten gevoeliger worden voor eigenaardigheden in de data. Tegelijk bleef het gedrag van bias minder uniform. Bij k‑Nearest Neighbours en Support Vector Machines had bias de neiging te stijgen naarmate k groter werd, wat betekent dat deze modellen tijdens cross‑validation vaak nauwkeuriger leken dan op de afgezonderde testset. Decision Trees toonden ongeveer gebalanceerde patronen, en Logistic Regression zat ertussenin, met wisselende maar meer gematigde biasveranderingen.
Waarom de "standaardinstellingen" misleidend kunnen zijn
De meeste praktische handleidingen adviseren simpelweg vijf of tien folds, ongeacht dataset of leeralgoritme. De analyse van de auteurs laat zien dat dergelijk one‑size‑fits‑all advies misleidend kan zijn. Voor sommige datasets en modellen versterkten hogere k‑waarden het te optimistische beeld van prestaties; in alle gevallen bracht een groter aantal folds meer variabiliteit in de schattingen. Dit is vooral zorgwekkend in sectoren met hoge inzet zoals gezondheidszorg, financiën of infrastructuur, waar valse zekerheid over de nauwkeurigheid van een model echte gevolgen kan hebben. De studie stelt dat de effecten van k afhangen van zowel de aard van de data (klein versus groot, ruisachtig versus schoner) als van hoe het specifieke algoritme leert van herhaalde, bijna identieke trainingssets.
Belangrijkste boodschap voor iedereen die machine learning gebruikt
De kernles is dat het aantal folds in cross‑validation geen onschuldig technisch detail is—het vormt rechtstreeks hoe betrouwbaar je nauwkeurigheidsmetingen zijn. In deze experimenten maakten meer folds de resultaten consequent wankeliger en lieten ze vaak sommige modellen beter lijken dan ze in werkelijkheid waren. In plaats van blindelings k=5 of k=10 te kiezen, raden de auteurs aan k als een afstemmingsknop te behandelen: bekijk hoe resultaten veranderen over een klein bereik van k‑waarden en, waar mogelijk, gebruik meer dan één prestatiemaatstaf. Voor zowel beoefenaars als geïnteresseerde lezers is de boodschap helder: bij het evalueren van machine‑learningmodellen kan de manier waarop je de data snijdt bijna net zo belangrijk zijn als het model zelf.
Bronvermelding: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
Trefwoorden: k-fold cross-validation, bias-variance trade-off, model evaluation, machine learning validation, supervised classification