Clear Sky Science · nl
Een nieuwe hybride aanpak voor droogtevoorspelling: gebruikmaken van feature-engineering en ensemblemethoden
Waarom het voorspellen van droge periodes ertoe doet
Droogtes sluipen langzaam binnen maar kunnen gewassen, drinkwatervoorraden en hele lokale economieën verwoesten. Nu klimaatverandering het weer onvoorspelbaarder maakt, hebben gemeenschappen vroegtijdige waarschuwingen nodig die verder gaan dan eenvoudige schattingen van neerslag. Dit artikel presenteert een nieuwe manier om te voorspellen hoe ernstig droogtes zullen worden, waarbij slimme combinaties van wiskunde en machine learning boeren en planners een helderder beeld geven van wat hen te wachten staat.
Van veranderende luchten naar bruikbare signalen
De studie begint bij een eenvoudige realiteit: het klimaat van vandaag is rommelig. Temperatuurschommelingen, veranderende winden en ongelijkmatige neerslag volgen niet langer nette statistische patronen. Traditionele voorspellingsinstrumenten hebben moeite met die complexiteit. De auteurs wenden zich daarom tot grote verzamelingen weer- en landschapsgegevens, waaronder neerslag, temperatuur, vochtigheid, wind, hoogte van de grond, helling, bodemkwaliteit en een score voor vegetatiegezondheid. Hun doel is deze ruwe cijfers te reduceren tot een kleinere set krachtige signalen die beschrijven hoe dicht een regio bij verschillende droogteniveaus staat, variërend van gezonde condities tot extreme waterschaarste.
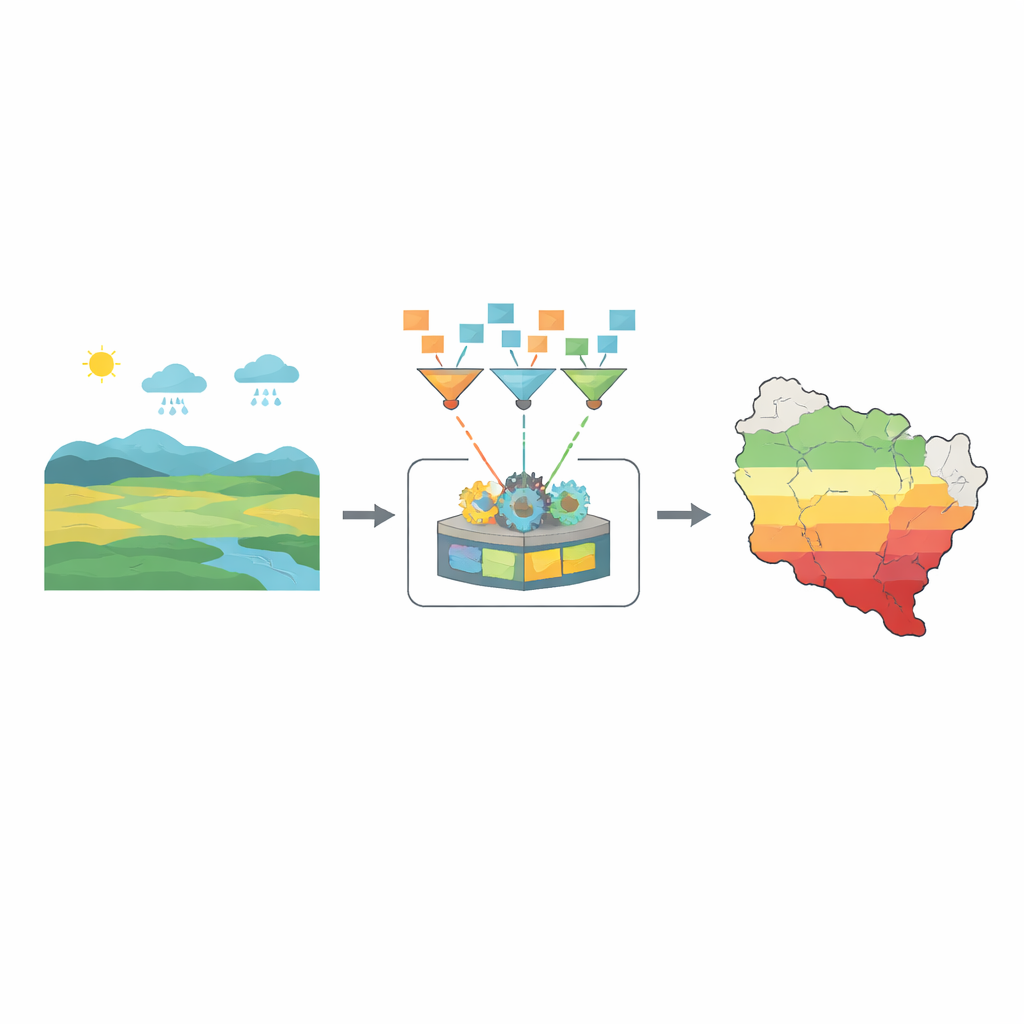
De paar cijfers kiezen die er het meest toe doen
Niet elke meting is even nuttig. Landsnamen of administratieve codes bijvoorbeeld verklaren weinig over waarom planten uitdrogen. Het team reinigt eerst de gegevens en gebruikt vervolgens een correlatieanalyse om te zien welke factoren samen bewegen en welke daadwerkelijk helpen om natte van droge perioden te onderscheiden. Ze ontdekken dat bepaalde kenmerken eruit springen: een vegetatiescore, de helling van het terrein in één richting, en drie vochtgerelateerde lucht-temperaturen dicht bij de grond. Deze zorgvuldig gekozen ingrediënten worden de ruggengraat van het voorspellingssysteem.
Ruwe data omzetten in droogtevingerafdrukken
In plaats van deze vijf ingrediënten simpelweg aan een algoritme te voeren, ontwerpen de auteurs nieuwe gecombineerde maten die weerspiegelen hoe droogte zich in de natuur gedraagt. Ze bouwen eenvoudige maar betekenisvolle formules — met alleen vertrouwde bewerkingen zoals optellen, vermenigvuldigen, vierkantswortels en logaritmen — om ideeën vast te leggen zoals algemene droogte, het gunstige effect van recente regen, hoe snel warmte condities richting droogte duwt, hoeveel water nog in de bodem zit, en de balans tussen gewonnen vocht en verloren evapotranspiratie. Elke formule levert een nieuwe index op die fungeert als een vingerafdruk van de huidige droogtedruk voor elke locatie en week in de dataset.
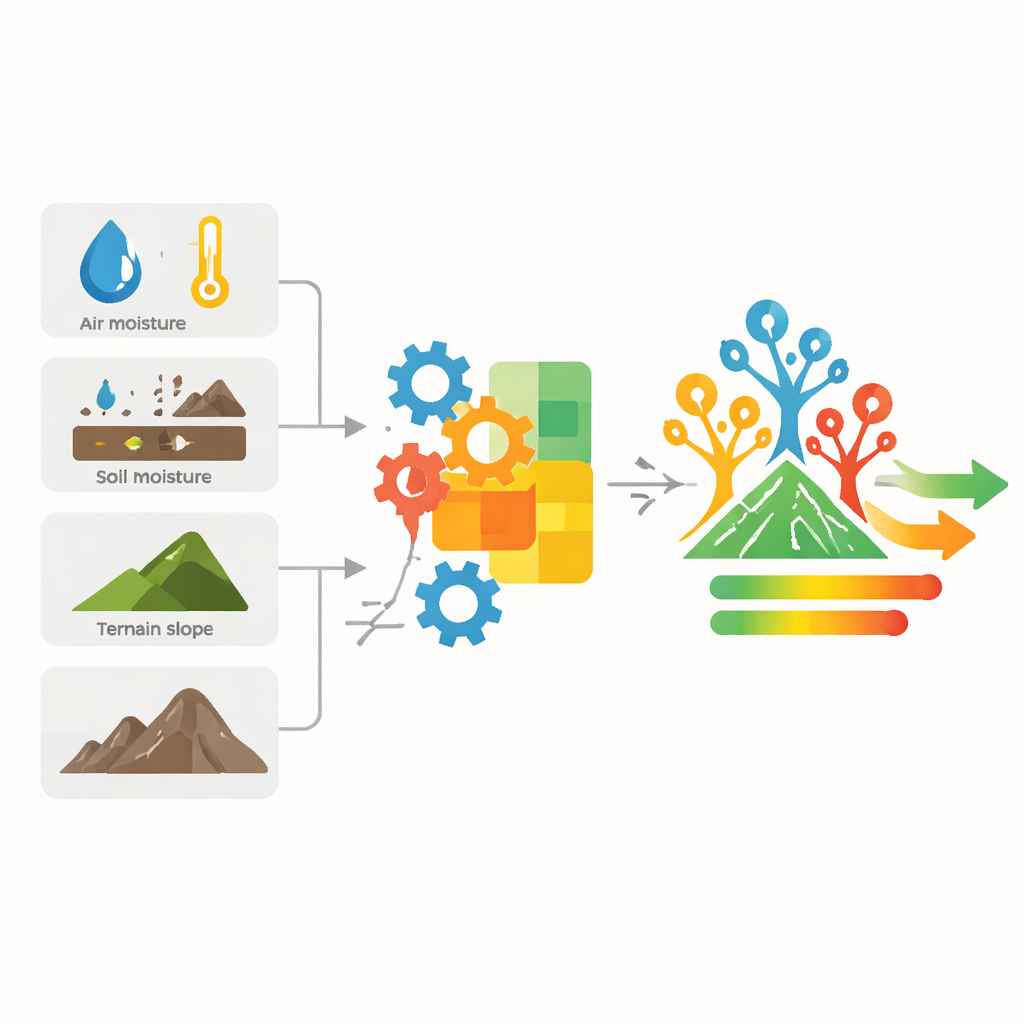
Een bos van beslissingen het resultaat laten bepalen
Deze geconstrueerde indexen worden vervolgens aan een machine learning-methode gegeven die een random forest heet. In plaats van één grote beslisregel groeit deze aanpak vele eenvoudige beslisbomen, waarbij elke boom een iets andere doorsnede van de data ziet. Elke boom geeft zijn eigen oordeel over bij welk droogteniveau een situatie hoort, en het uiteindelijke antwoord van het bos is gebaseerd op meerderheidstemming. Door te tunen hoeveel bomen er worden gegroeid en hoe diep elke boom de data kan splitsen, vinden de auteurs een tussenweg waarin het model zowel nauwkeurig als bestand tegen overfitting is. Op apart gehouden testdata classificeert hun hybride systeem het droogteniveau bijna in elk geval correct en vertoont het veel minder fouten dan meer gangbare instrumenten zoals k-nearest neighbors, support vector machines of eenvoudige logistische regressie.
Wat dit betekent voor de praktijk
Voor niet-specialisten is de kernboodschap dat een kleine set goed ontworpen indicatoren, gegrond in hoe warmte en vochtigheid zich daadwerkelijk gedragen, een zeer betrouwbaar waarschuwingssysteem kan aandrijven. Door eenvoudige vergelijkingen te mengen met een op stemming gebaseerde leermethode bereikt het model zeer hoge nauwkeurigheid terwijl het relatief licht blijft om uit te voeren en makkelijker te interpreteren is dan veel deep learning-blackboxes. Als deze hybride aanpak wordt overgenomen en aangepast aan lokale data, kan het boeren helpen bij het aanpassen van planttijden, waterbeheerders bij het plannen van opslag en lozingen, en hulpdiensten bij het voorbereiden op escalerende droge periodes voordat die uitgroeien tot ernstige crises.
Bronvermelding: Charjan, O., Gajbhiye, K., Warhade, J. et al. A Novel Hybrid Approach To Drought Forecasting: Leveraging Feature Engineering And Ensemble Methods. Sci Rep 16, 7972 (2026). https://doi.org/10.1038/s41598-026-37206-6
Trefwoorden: droogtevoorspelling, klimaatrisico, machine learning, landbouw, waarschuwingssystemen