Clear Sky Science · nl
End-to-end nooddienstprotocol voor tunnelongevallen uitgebreid met reinforcement learning
Waarom slimmer redden in tunnels ertoe doet
Wanneer een ramp toeslaat in een wegtunnel—of het nu door een botsing, brand of structurele instorting is—kunnen mensen vast komen te zitten in een lange, rokerige, doolhofachtige buis met heel weinig uitgangen. Menselijke redders moeten zich haasten juist op het moment dat de zichtbaarheid afneemt, de temperatuur stijgt en puin de doorgang blokkeert. Deze studie onderzoekt hoe kleine vliegende robots, of drones, aangedreven door een slimme leerstrategie, snelle en betrouwbare hulpverleners in zulke gevaarlijke situaties kunnen worden: het vinden van slachtoffers en het uitzetten van veilige paden terwijl menselijke teams uit de ergste gevaren worden gehouden.
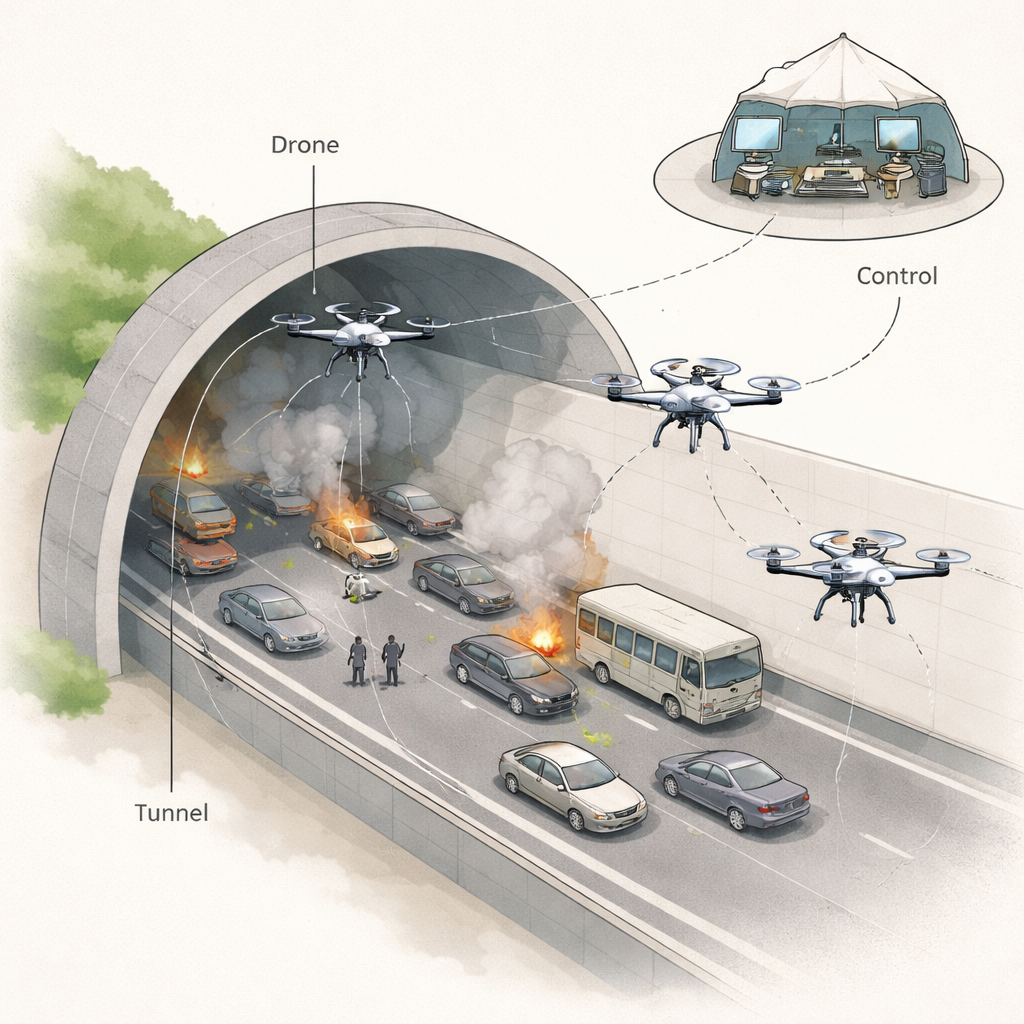
Gevaarlijke ondergrondse knelpunten
Moderne steden vertrouwen op tunnels voor snelwegen, treinen en nutsvoorzieningen, maar hetzelfde gesloten ontwerp dat efficiëntie brengt maakt ongevallen daarin ook uitzonderlijk dodelijk. Branden verspreiden snel rook, giftige gassen hopen zich op en smalle passages kunnen volraken met gecrashte voertuigen of gevallen beton. Traditionele reddingsteams gaan vaak naar binnen met beperkte informatie en moeten gissen waar ze heen moeten terwijl hun radio’s moeite hebben door dik gesteente en beton heen te werken. Eerdere rampen in China en Japan, onder andere, hebben laten zien hoe moeilijk het is slachtoffers op tijd te bereiken en benadrukken de behoefte aan middelen die op manieren kunnen zien en vooruitdenken waar mensen dat niet kunnen.
Drones leren verkennen en zoeken
De auteurs stellen een systeem voor waarin meerdere autonome drones samenwerken om een beschadigde tunnel te verkennen, een live-kaart op te bouwen en vastzittende mensen te lokaliseren. In plaats van een vaste, vooraf geprogrammeerde route te volgen leert elke drone uit ervaring met een methode die reinforcement learning heet: hij probeert acties, ziet wat er gebeurt en ontdekt geleidelijk welke keuzes doorgaans leiden tot snellere reddingen en minder fouten. De tunnel wordt weergegeven als een rooster van cellen, en de drones richten zich op "frontiers" waar bekende ruimte onbekende ruimte ontmoet, en stuwen die grens gestaag naar buiten. Bij elke stap kiezen ze uit een kleine set roosterbewegingen en werken ze hun interne tabellen bij met welke bewegingen in vergelijkbare situaties eerder het beste bleken.
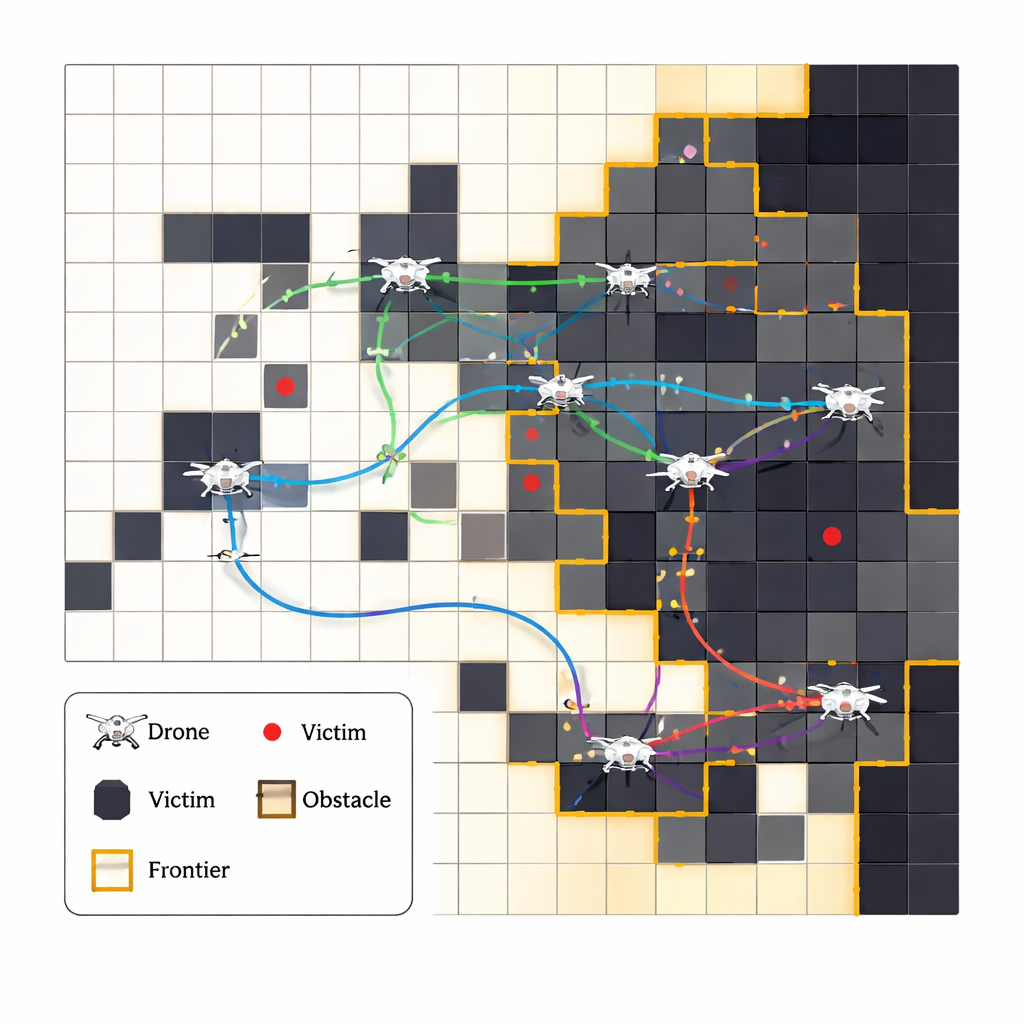
Veel robots laten samenwerken zonder veel communicatie
Meerdere drones tegelijkertijd in dezelfde tunnel laten zoeken brengt een nieuwe uitdaging met zich mee: hoe voorkomen ze dat ze tegen elkaar aanvliegen of steeds hetzelfde gebied scannen, vooral wanneer communicatie onbetrouwbaar kan zijn? In plaats van ze een centrale baas te geven of voortdurend radioverkeer te laten hebben, ontwerpen de onderzoekers een eenvoudig scoresysteem dat stilletjes goed groepsgedrag stimuleert. Een drone krijgt een grote beloning wanneer hij een nieuw slachtoffer ontdekt, maar wordt bestraft als hij tijd verspilt door een plek opnieuw te bezoeken, botst met een andere drone of "faalt" door zijn batterij te laten leeglopen. In de loop van de tijd duwt dit elke drone ertoe onontgonnen gebieden te verkiezen en zijn teamgenoten te mijden, zodat een soort samenwerking vanzelf ontstaat uit de gedeelde consequenties, ook al leert elke drone technisch gezien zelfstandig.
Trucs lenen van wolven om vastlopen te vermijden
Zuiver trial-and-error leren kan soms vastlopen in veilige maar tweederangs gewoonten—zoals altijd kiezen voor een vertrouwde gang in plaats van een risicovolle kortere route te proberen. Om de drones nieuwsgierig te houden lenen de onderzoekers ideeën uit een wiskundig model van hoe grijze wolven in roedels jagen. Deze "Grey Wolf Optimization"-component zet de drones ertoe aan af en toe de best presterende zoekpatronen die tot nu toe zijn gezien te imiteren, terwijl er toch ruimte blijft voor verkenning. In de praktijk beïnvloedt het welke nieuwe acties worden geprobeerd en helpt het het leerproces uit doodlopende wegen te springen en zich aan te passen wanneer de tunnel verandert—bijvoorbeeld als een deel van de route plotseling geblokkeerd wordt door vuur of puin.
De aanpak testen in virtuele rampen
Omdat het niet veilig is ongeteste strategieën in echte nooddiensten in tunnels te proberen, bouwen de onderzoekers gedetailleerde computersimulaties die nauwe gangen, doodlopende zijstraten, obstakels en verspreide slachtoffers nabootsen. Ze vergelijken hun op leren gebaseerde systeem met meerdere andere methoden, waaronder puur willekeurig dwalen en op zichzelf staande optimalisatie zonder leren. Zowel bij tests met één drone als met meerdere drones vindt hun aanpak slachtoffers sneller, verkent meer van de tunnel met minder verspilde stappen en voorkomt botsingen betrouwbaarder. Belangrijk is dat dit wordt bereikt met lichte, tabelgebaseerde berekeningen in plaats van energieverslindende deep-learningnetwerken, wat betekent dat het realistisch op kleine boordcomputers tijdens een daadwerkelijke noodsituatie zou kunnen draaien.
Wat dit kan betekenen voor toekomstige reddingen
De studie laat zien dat zwermen relatief eenvoudige drones, gestuurd door zorgvuldig ontworpen leerregels en enkele ideeën ontleend aan de natuur, waardevolle partners voor brandweerlieden en reddingsteams bij tunnelrampen kunnen worden. Door snel rokerige, veranderende omgevingen in kaart te brengen en zich te richten op waarschijnlijke slachtoffervondsten zonder voortdurende menselijke controle, kunnen dergelijke systemen kostbare minuten van de responstijd afsnoepen en tegelijkertijd de risico’s voor hulpverleners verminderen. Hoewel het werk tot nu toe gebaseerd is op simulaties en ideale sensoren, vormt het een praktische basis voor toekomstige systemen in de echte wereld die onder strikte tijd-, energie- en rekenbeperkingen moeten werken in enkele van de meest veeleisende reddingsomstandigheden op aarde.
Bronvermelding: ur Rehman, H.M.R., Gul, M.J., Younas, R. et al. End-to-end emergency response protocol for tunnel accidents augmentation with reinforcement learning. Sci Rep 16, 6226 (2026). https://doi.org/10.1038/s41598-026-37191-w
Trefwoorden: tunnelnooddienst, zoek- en reddingsdrones, multi-agent reinforcement learning, robotisch rampenbeheer, autonome verkenning