Clear Sky Science · nl
Vergelijkende analyse van gesuperviseerde en ensemblemodellen met ongecontroleerde verkenning voor de voorspelling van de ziekte van Alzheimer
Waarom vroege waarschuwing ertoe doet
De ziekte van Alzheimer berooft mensen geleidelijk van geheugen en zelfstandigheid, vaak lang voordat een duidelijke diagnose wordt gesteld. Families, artsen en zorgsystemen hebben allemaal baat bij een vroege signalering, omdat behandeling, planning en ondersteuning dan het meeste verschil kunnen maken. Deze studie stelt een praktische vraag: kunnen zorgvuldig ontworpen computerprogramma’s, getraind op routineklinische data en hersenscans, dementie betrouwbaarder opsporen dan de huidige standaardinstrumenten — en tegelijk verborgen patronen onthullen in hoe de ziekte zich ontwikkelt?
Patiëntendossiers omzetten in bruikbare signalen
De onderzoekers maakten gebruik van een bekende dataset, OASIS-2, die 150 oudere volwassenen van 60 tot 96 jaar gedurende meerdere jaren volgt. Voor elk bezoek bevat de dataset basisgegevens zoals leeftijd, opleidingsjaren en sociaaleconomische status, evenals cognitieve testscores en metingen afgeleid van MRI-hersenscans, zoals het totale hersenvolume. Voordat enige voorspelling mogelijk was, schonk het team de data, verwijderde identificerende gegevens en onduidelijke gevallen, vulde een klein aantal ontbrekende waarden in en bracht alle numerieke metingen op een gemeenschappelijke schaal. Ze pakten ook een belangrijk praktisch probleem aan: veel meer mensen in de dataset waren gezond dan gedementeerd. Om te voorkomen dat de modellen meestal simpelweg “geen dementie” zouden raden, gebruikten de onderzoekers wegingsschema’s waardoor fouten op de kleinere, gedementeerde groep zwaarder meewegen tijdens het trainen.
Vergelijken van klassieke tools met modelteams
Met deze voorbereide dataset vergeleken de auteurs vertrouwde machine-learningmethoden met meer geavanceerde “ensembles”, die meerdere modellen combineren tot één sterker voorspellend model. De klassieke groep bestond uit logistische regressie, beslissingsbomen, support vector machines en random forests. De ensemblegroep bevatte AdaBoost, XGBoost en een meerderheidsstemmodel dat drie getunede classifiers combineerde. Alle modellen werden getraind op een deel van de data en getest op achtergehouden gevallen, met prestatiebeoordeling aan de hand van accuratesse, het vermogen om gedementeerde personen correct te signaleren (recall) en de oppervlakte onder de ROC-curve, een samenvatting van hoe goed het model gezonde van zieke gevallen scheidt. 
Wanneer vele geesten één overtreffen
De kop-aan-kop resultaten waren duidelijk. Terwijl de beste traditionele methoden redelijk goed presteerden, bereikten ze een plateau rond het niveau dat in eerdere onderzoeken werd gerapporteerd, met testaccuratesse in het laag- tot midden 80-procentgebied. Daarentegen bereikte het meerderheidsstem-ensemble ongeveer 95 procent accuratesse en een vergelijkbaar hoge ROC-score, waarmee het de vaak geciteerde 92 procent drempel overschreed. AdaBoost en andere ensemblestromen deden het ook beter dan elk afzonderlijk traditioneel model. Dit voordeel ontstaat omdat verschillende algoritmen verschillende aspecten van de data oppikken; door ze te laten “stemmen” egaliseert het ensemble individuele eigenaardigheden en overfitting, wat leidt tot stabielere voorspellingen. De prijs voor deze winst is verminderde transparantie: het is moeilijker in één oogopslag te zien waarom een ensemble een bepaalde beslissing nam vergeleken met een eenvoudige regressie of enkele boom. 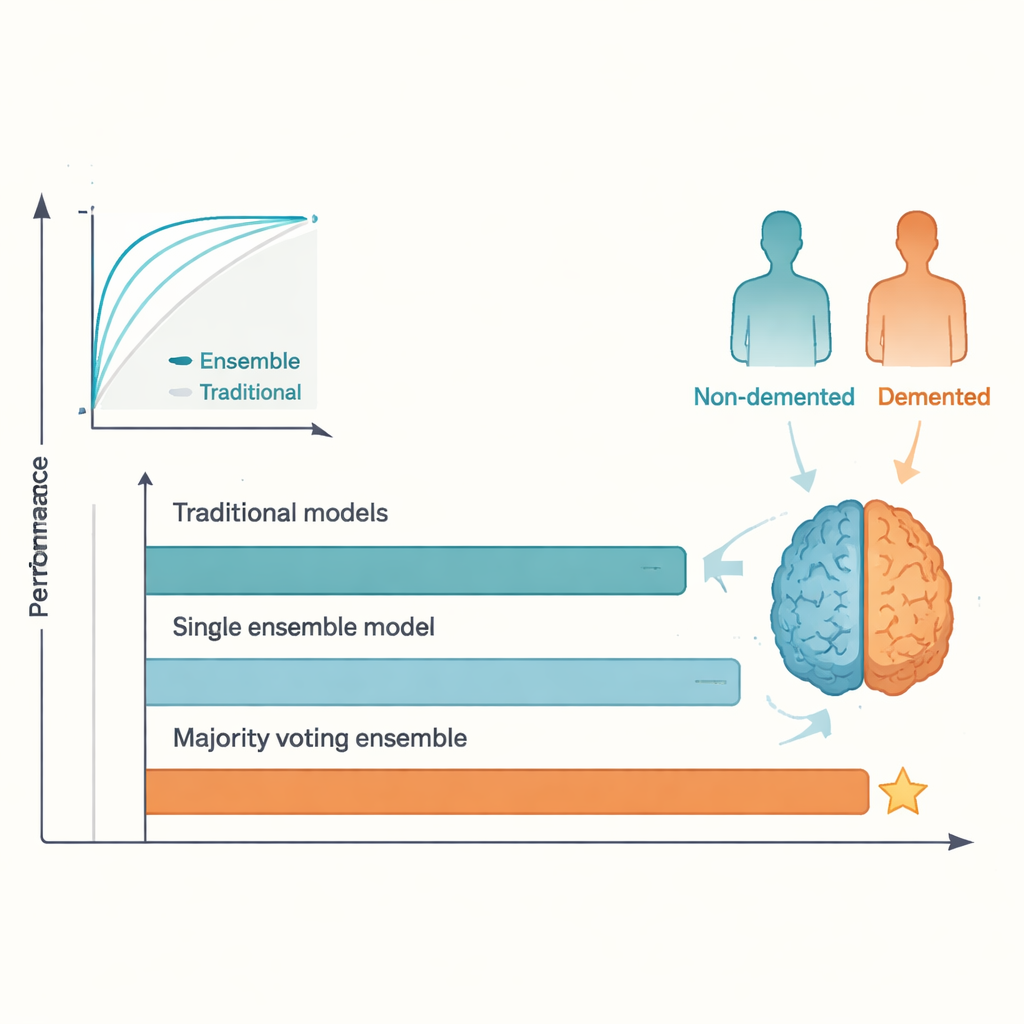
Zoeken naar natuurlijke groeperingen in de data
Naast de vraag wie dementie heeft, onderzochten de onderzoekers ook hoe patiënten natuurlijk in groepen samenkomen, onafhankelijk van diagnoselabels. Hiervoor transformeerden ze alle continue variabelen naar geordende categorieën — zoals leeftijds- of hersenvolumebereiken — en pasten een techniek toe genaamd multiple correspondence analysis om deze rijke informatie samen te persen tot een paar onderliggende dimensies. Vervolgens gebruikten ze k-means clustering om deze punten in een klein aantal coherente groepen te verdelen. Sommige clusters werden gedomineerd door mensen met behouden hersenvolume en normale cognitieve scores, terwijl andere clusters individuen bevatte met laag hersenvolume, slechte testresultaten en ernstiger dementieclassificaties. Het feit dat deze ongecontroleerde clusters goed samenvielen met de klinische status suggereert dat de data een sterk, consistent signaal over ziekte-risico en progressie dragen.
Wat dit betekent voor patiënten en clinici
Voor een leek is de conclusie helder: wanneer ze doordacht zijn ontworpen, kunnen teams van machine-learningmodellen Alzheimergerelateerde dementie in gestructureerde klinische data nauwkeuriger opsporen dan oudere methoden, en ze kunnen dat doen met informatie die veel klinieken al verzamelen. Tegelijkertijd laten verkennende technieken zien dat mensen in onderscheidende profielen van hersengezondheid en cognitieve functie vallen, wat wijst op verschillende trajecten die de ziekte kan volgen. Hoewel de studie wordt beperkt door de bescheiden steekproefgrootte en door de complexiteit van het interpreteren van ensemblestromen, laat ze zien dat het combineren van krachtige voorspelling met zorgvuldige verkennende analyse zowel vroege detectie kan verbeteren als ons begrip van hoe Alzheimer zich ontwikkelt kan verdiepen.
Bronvermelding: Amr, Y., Gad, W., Leiva, V. et al. Comparative analysis of supervised and ensemble models with unsupervised exploration for alzheimer’s disease prediction. Sci Rep 16, 7322 (2026). https://doi.org/10.1038/s41598-026-37122-9
Trefwoorden: Ziekte van Alzheimer, dementievoorspelling, machine learning, ensemblemethoden, hersenbeeldvorming