Clear Sky Science · nl
Experts toewijzingssysteem gebaseerd op natuurlijke taalverwerking voor Marie Sklodowska-Curie acties
Waarom het kiezen van de juiste expert echt belangrijk is
Wanneer duizenden onderzoeksvoorstellen concurreren om beperkte middelen, hangt alles af van wie ze beoordeelt. Als de toegewezen experts het onderwerp van een voorstel niet echt doorgronden, kunnen veelbelovende ideeën verkeerd worden geïnterpreteerd of over het hoofd worden gezien. Dit artikel onderzoekt hoe kunstmatige intelligentie, met name moderne taalverwerkende systemen, kan helpen voorstellen nauwkeuriger en eerlijker aan de best mogelijke experts te koppelen dan de huidige op trefwoorden gebaseerde tools.
Het probleem met trefwoordenlijstjes
Tot nu toe berustte de toewijzing van experts in grote Europese financieringsregelingen zoals de Marie Skłodowska-Curie postdocbeurzen sterk op trefwoorden. Het huidige platform doorzoekt voorstelomschrijvingen en beoordelaarsprofielen op overeenkomende termen en stelt vervolgens drie experts plus alternatieven voor. Maar Vice Chairs—senior wetenschappers die het proces overzien—wijzigen uiteindelijk ongeveer 40% van deze toewijzingen. Dat niveau van menselijke correctie maakt het systeem arbeidsintensief, traag en enigszins ondoorzichtig, vooral omdat elk jaar tot 10.000 voorstellen binnenkomen, vaak in opkomende gebieden waar vaste trefwoordenlijsten slecht presteren.
Onderzoek lezen als een mens, maar op schaal
De auteurs ontwikkelden een nieuw toewijzingssysteem dat probeert onderzoek te "lezen" zoals een menselijke expert dat zou doen. In plaats van te vertrouwen op labels verzamelt het de publicaties van elke expert via ORCID, een wereldwijd onderzoekers-ID-systeem, en bouwt het een database van meer dan 2.800 artikeloverzichten op. Zowel voorstelabstracts als publicatie-abstracts worden vervolgens verwerkt door GALACTICA, een groot taalmodel dat specifiek op wetenschappelijke teksten is getraind. GALACTICA zet elk abstract om in een numerieke vingerafdruk die de betekenis vastlegt, niet alleen de bewoording. Door deze vingerafdrukken te vergelijken kan het systeem inschatten hoe nauw de inhoud van een voorstel overeenkomt met het eerdere werk van elke expert.
Drie manieren om expertise op te tellen
Een uitdaging is dat experts tientallen publicaties kunnen hebben. Het systeem heeft een enkele score per expert en voorstel nodig, dus testten de auteurs drie eenvoudige manieren om gelijkenissen te combineren. De Sum-strategie telt alle gelijkenheidsscores op en beloont brede en herhaalde relevantie. De Product-strategie vermenigvuldigt ze, waardoor consequent hoge gelijkenis over veel publicaties wordt benadrukt maar elke zwakke match zwaar wordt bestraft. De Maximum-strategie houdt alleen de sterkste enkele match aan, uitgaande van het idee dat één zeer nauw verwant artikel voldoende kan zijn om een toewijzing te rechtvaardigen. Deze scores worden vervolgens gebruikt om 48 kandidaat-experts te rangschikken voor elk van 181 voorstellen, en de ranglijsten worden vergeleken met de uiteindelijke expertkeuzes van de Vice Chairs.
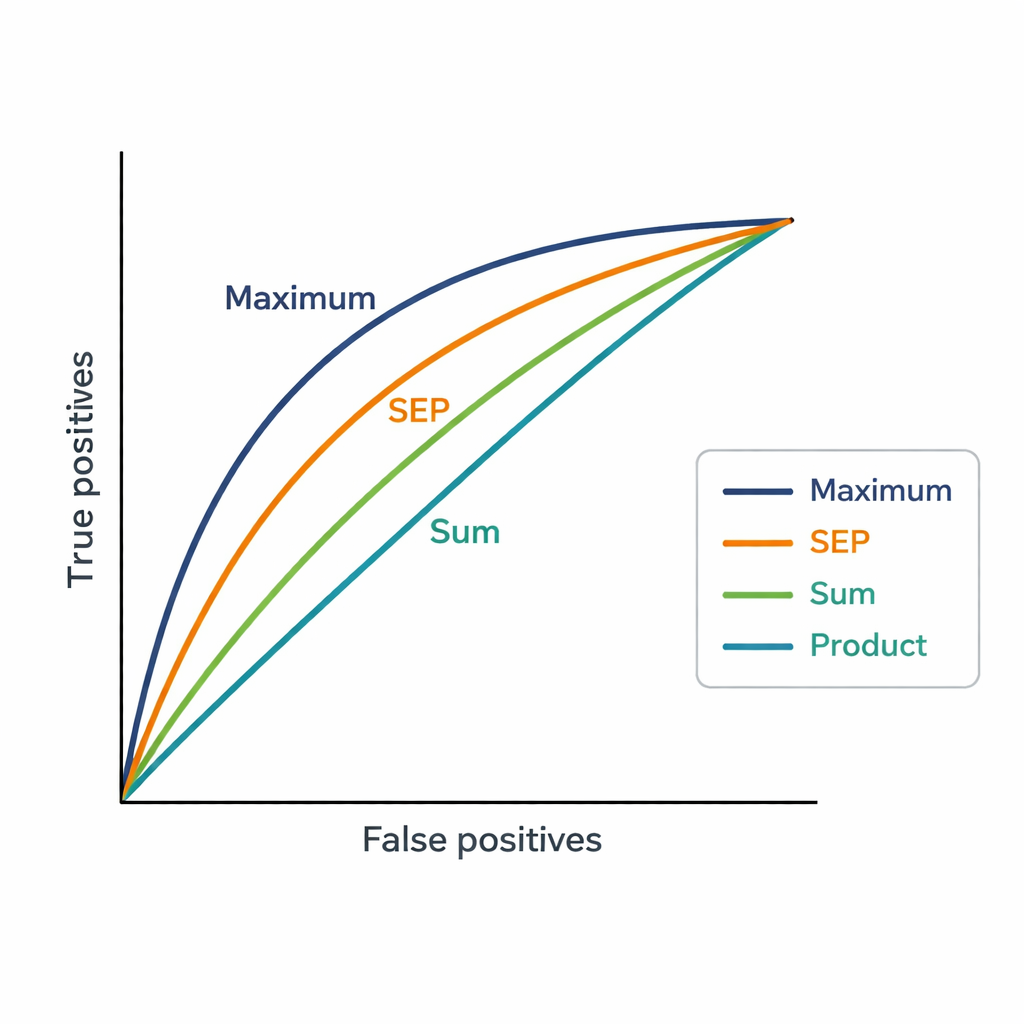
Wat de cijfers over menselijke keuzes onthullen
De Maximum-strategie kwam het meest overeen met de beslissingen van Vice Chairs en behaalde een AUC van 0,82, beter dan zowel het bestaande trefwoordgebaseerde systeem (AUC 0,75) als de andere aggregatiemethoden. In de praktijk verscheen de door Vice Chairs gekozen expert meestal onder de vier best voorgestelde suggesties van Maximum. Dit suggereert dat mensen bij het toewijzen van beoordelaars de neiging hebben te letten op de aanwezigheid van ten minste één zeer sterke verbinding tussen het eerdere werk van een expert en een voorstel, in plaats van te eisen dat alle publicaties van de expert aansluiten. De nieuwe methode genereert ook veel fijnmazigere scores dan de grove "affiniteits"-niveaus van het platform, waardoor een duidelijkere onderscheiding tussen nauw gerangschikte experts mogelijk wordt.
Wat dit betekent voor toekomstige subsidiebeoordelingen
Voor de niet-specialistische lezer is de conclusie eenvoudig: door AI te gebruiken die wetenschappelijke taal begrijpt, kunnen financieringsinstanties voorstellen beter koppelen aan de juiste experts, handmatige correcties verminderen en het proces consistenter en transparanter maken. Hoewel verschillende manieren om bewijs uit publicaties te combineren verschillende aspecten van expertise benadrukken, lijkt de eenvoudige regel van de "beste enkele match" te weerspiegelen hoe mensen daadwerkelijk beslissen. Naarmate dergelijke systemen breder worden getest en met nieuwere taalmodellen, zouden ze een sleutelrol kunnen spelen in eerlijkere en efficiëntere onderzoeksbeoordeling wereldwijd.
Bronvermelding: Álvarez-García, E., García-Costa, D., De Waele, I. et al. Expert assignment system based on natural language processing for Marie Sklodowska-Curie actions. Sci Rep 16, 6396 (2026). https://doi.org/10.1038/s41598-026-37115-8
Trefwoorden: peer review, expertmatching, onderzoeksfinanciering, natuurlijke taalverwerking, grote taalmodellen