Clear Sky Science · nl
Vergelijkende studie naar het voorspellen van postoperatieve verre metastasen bij longkanker op basis van machine-learningmodellen
Waarom het voorspellen van kankeruitzaaiing ertoe doet
Longkanker blijft een van de dodelijkste vormen van kanker, zelfs wanneer chirurgen alle zichtbare tumoren verwijderen. Veel patiënten ontwikkelen later verstopt liggende kankercellen die zich manifesteren in de hersenen, botten, lever of andere organen. Artsen willen bij voorkeur kort na de operatie weten welke patiënten een grotere kans hebben op dit soort verre uitzaaiingen, zodat ze vervolgbezoeken en behandelingen kunnen afstemmen. Deze studie onderzoekt of moderne computerprogramma’s, bekend als machine-learningmodellen, kunnen helpen voorspellen wie een hoger risico heeft, aan de hand van informatie die ziekenhuizen al routinematig verzamelen.
Nauwkeurig kijken naar veel patiënten
De onderzoekers bestudeerden dossiers van 3.120 mensen met longkanker in stadium I tot III die hun tumor laten verwijderen bij één kankercentrum in China. Allen hadden minimaal twee jaar follow-up. Per patiënt verzamelde het team 52 soorten gegevens, waaronder leeftijd, geslacht, lichaamsgewicht, rookgeschiedenis, scanbevindingen, operatiegegevens, laboratoriumuitslagen en of ze na de operatie aanvullende behandelingen zoals chemotherapie of radiotherapie kregen. In de loop van de tijd ontwikkelden 596 van deze patiënten verre metastasen, terwijl 2.524 dat niet deden. Deze real-world mix stelde het team in staat vast te stellen welke kenmerken samenhingen met toekomstige uitzaaiing.
Computers ‘opleiden’ om risicopatronen te herkennen
In plaats van te vertrouwen op één enkele formule, vergeleken de wetenschappers negen verschillende machine-learningmethoden, van eenvoudige beslisbomen tot geavanceerdere technieken die veel kleine modellen combineren. Ze gebruikten eerst een wiskundige selectie om de oorspronkelijke 52 factoren terug te brengen tot een kleinere, informatievere set. Vervolgens trainden en testten ze elk model herhaaldelijk: het model leerde van een deel van de data en werd getest op patiënten die het nog nooit had “gezien”. Omdat slechts ongeveer één op de vijf patiënten metastasen ontwikkelde, pasten ze de trainingsprocedure aan zodat het model niet simpelweg voor iedereen “laag risico” zou voorspellen. De prestaties beoordeelden ze met verschillende maatstaven, waaronder hoe goed de modellen hoge en lage risico’s konden scheiden en hoe nauw de voorspelde risico’s overeenkwamen met de werkelijkheid.
Het meest betrouwbare model vinden
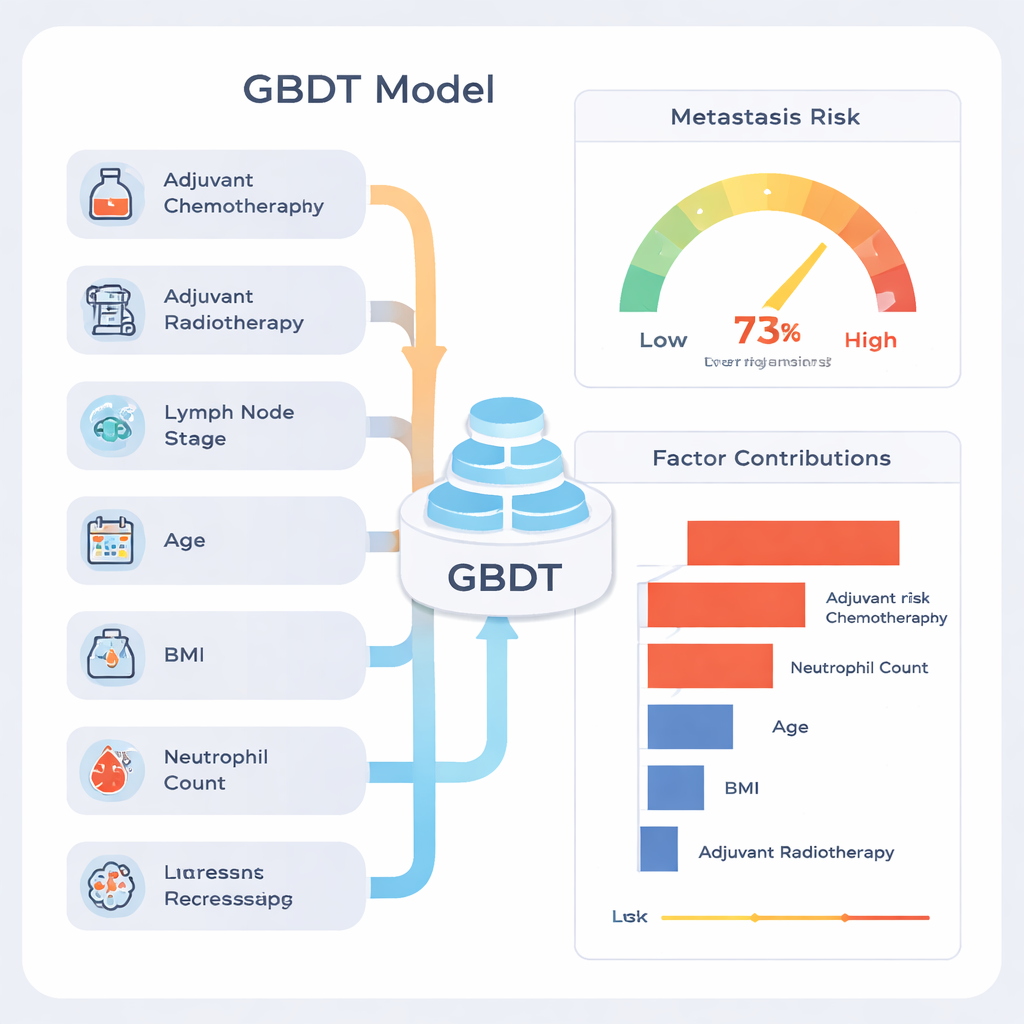
Van de negen benaderingen stak één methode eruit: Gradient Boosting Decision Tree (GBDT). Op testdata rangschikte dit model patiënten correct met een algehele nauwkeurigheid van ongeveer 77%, en de samenvattende discriminatiescore (het oppervlak onder de ROC-curve) was 0,81, wat als sterk wordt gezien voor medische voorspellingsinstrumenten. Het model was met name goed in het identificeren van patiënten die metastasevrij zouden blijven (hoge “negatieve predictieve waarde”), wat betekent dat een laag-risico-uitkomst meestal geruststellend was. Toen het team keek naar het gedrag van het model over vele willekeurige verdelingen van de data, bleef de prestatie stabiel, wat erop wijst dat het model niet slechts de eigenaardigheden van één specifieke subset uit het hoofd leerde.
Wat de beslissingen van het model stuurt
Een veelgehoorde kritiek op machine learning is dat het een “black box” kan zijn. Om dit tegen te gaan, gebruikten de auteurs een verklaringsmethode genaamd SHAP, die elke factor een bijdrage toekent aan de uiteindelijke risicoschatting voor elke patiënt. Deze analyse toonde aan dat de sterkste signalen waren of de patiënt na de operatie chemotherapie of radiotherapie had gekregen, hoeveel lymfeklieren kankercellen bevatten, leeftijd, bodymassindex (BMI) en het preoperatieve neutrofiele aantal, een type witte bloedcel. Patiënten met meer gevorderde lymfeklierbetrokkenheid en tekenen van systemische ontsteking hadden doorgaans een hoger voorspeld risico. De auteurs benadrukken dat hoge bijdragen van chemotherapie en radiotherapie niet betekenen dat deze behandelingen metastasen veroorzaken; het zijn eerder signalen dat artsen de ziekte al als agressiever hadden ingeschat, waardoor deze patiënten bij aanvang een hoger risico hadden.
Hoe dit in de praktijk patiënten kan helpen
Aangezien het model gebruikmaakt van informatie die de meeste kankercentra al vastleggen, zou het, na verdere validatie, in ziekenhuissoftware kunnen worden ingebouwd. Voor een nieuwe patiënt die net een longoperatie heeft ondergaan, zou het systeem hun gegevens kunnen ophalen en een gepersonaliseerde kans op verre metastasen uitlopen, samen met een eenvoudige verklaring welke factoren het risico verhogen of verlagen. Klinische teams kunnen dit vervolgens gebruiken om te beslissen wie mogelijk intensievere beeldvorming, extra begeleiding of inschrijving in klinische onderzoeken nodig heeft, en wie veilig intensieve opvolging kan vermijden. De studie vond plaats in één ziekenhuis, dus het hulpmiddel moet nog worden gecontroleerd en verfijnd in andere regio’s en zorgsystemen. Maar het biedt een veelbelovend model om routinematige klinische gegevens te combineren met transparante machine learning om de lange-termijnzorg voor mensen met longkanker te verbeteren.
Bronvermelding: Guo, X., Xu, T., Luo, Y. et al. Comparative study on predicting postoperative distant metastasis of lung cancer based on machine learning models. Sci Rep 16, 6468 (2026). https://doi.org/10.1038/s41598-026-37113-w
Trefwoorden: longkanker, verre metastasen, machine learning, risicovoorspelling, postoperatieve opvolging