Clear Sky Science · nl
Innovatieve temporele samenvatting voor complexe videoklassificatie
Waarom slimme videosamenvattingen ertoe doen
Van beveiligingscamera’s tot streamingplatforms: de wereld legt meer video vast dan mensen of computers gemakkelijk kunnen verwerken. Elke seconde beeld bevat tientallen frames, terwijl veel van die frames vrijwel identiek zijn. Dit artikel onderzoekt een manier om lange video’s terug te brengen tot alleen de meest veelzeggende momenten, zodat computers nog steeds acties kunnen herkennen—zoals koken, sporten of een hond uitlaten—terwijl ze veel minder tijd, geheugen en energie verbruiken. Zulke verbeteringen kunnen krachtige videoanalyse toegankelijk maken voor alledaagse apparaten, van huishoudrobots tot draagbare camera’s.

Van eindeloze frames naar sleutelmomenten
Traditionele systemen voor videoklassificatie proberen te herkennen wat er in een clip gebeurt—bijvoorbeeld groenten snijden of een basketbal schieten—door lange reeksen frames in zware deep-learningmodellen te voeden. Deze modellen moeten zowel verschijning (hoe iets eruitziet) als timing (hoe het zich in de tijd beweegt) verwerken. Het verwerken van alle frames leidt tot grote datasets, hoge opslagbehoeften en trage, energie-intensieve berekeningen. De auteurs stellen dat veel van deze frames redundant zijn: als er van het ene frame op het andere niets wezenlijks verandert, voegt het analyseren van beide weinig toe. De kern van het artikel is het selecteren van een veel kleinere set “sleutelframes” die toch de belangrijke veranderingen in de scène vastleggen.
Verandering tussen frames meten
Om die sleutelmomenten te vinden ontwerpen en vergelijken de onderzoekers meerdere manieren om te meten hoeveel het ene frame verschilt van het andere. In plaats van alleen te vertrouwen op de klassieke Euclidische afstand, die alle pixels gelijk behandelt, proberen ze alternatieven die gevoeliger zijn voor structurele veranderingen. Hun hoofdvoorstel, de “Norm of Rows”-afstand, richt zich op het grootste verschil per rij pixels en neemt vervolgens de meest uitgesproken rij als maat voor de verandering tussen twee frames. Ze verkennen ook afstanden gebaseerd op kolommen en methoden die gebruikmaken van eigenwaarden van matrixsamenvattingen van pixelverschillen. Al deze benaderingen hebben tot doel betekenisvolle bewegingen of scèneswitches beter te detecteren, zoals een hand die naar een keukengerei grijpt of een speler die springt.
Hoe de samenvattingspipeline werkt
Het samenvattingsproces begint met het allereerste frame van een video, dat wordt behandeld als het initiële sleutelframe. Het systeem vergelijkt dit sleutelframe vervolgens met elk volgend frame met behulp van een van de afstandsmetingen. Telkens wanneer de afstand boven een gekozen drempel uitstijgt, wordt het overeenkomstige frame aangemerkt als een nieuw sleutelframe, wat aangeeft dat er iets visueel belangrijks is veranderd. De procedure herhaalt zich dan met dit nieuwe sleutelframe als referentie, terwijl het door de video loopt en een keten van representatieve snapshots verzamelt. Door de drempel aan te passen kan de methode zo weinig als 20 procent of zoveel als 80 procent van de oorspronkelijke frames behouden, waarbij een afweging wordt gemaakt tussen compactheid en detail. Deze samengevatte reeksen worden vervolgens doorgegeven aan een standaard deep-learningclassificator die een krachtig beeldnetwerk (ResNet-50) combineert met een timinggevoelige LSTM-module.
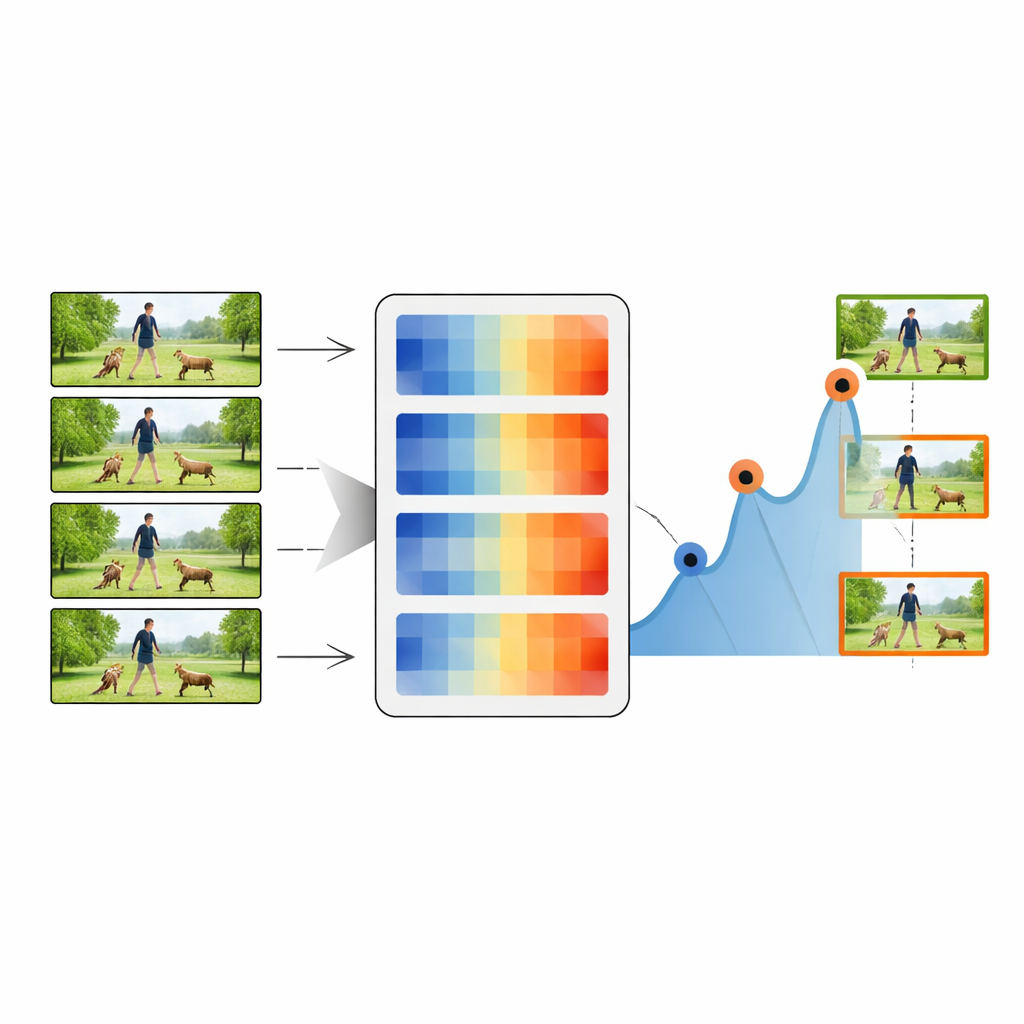
De methode op de proef stellen
De auteurs evalueren hun aanpak grondig op vier bekende videocorpora: alledaagse keukentaken (MMAC), sport- en algemene acties (UCF101 en UCF11), en meer gevarieerde, uitdagende clips (HMDB51). Over deze benchmarks heen levert de Norm of Rows-afstand consequent de beste balans tussen snelheid en nauwkeurigheid. Met slechts ongeveer de helft van de frames behouden bereikt hun systeem classificatienauwkeurigheden van meer dan 90 procent op meerdere datasets—vaak gelijk aan of beter dan complexere methoden die volledige, niet-samengevatte video’s gebruiken. Ze meten ook hoe goed de samenvattingen de originele inhoud dekken, hoe redundant de geselecteerde frames zijn en hoe divers de vastgelegde momenten worden. De voorgestelde metriek behaalt hoge dekking met lage redundantie, wat betekent dat het de verhaallijn van de video behoudt zonder vergelijkbare frames te herhalen.
Snelere beslissingen voor video in de praktijk
Door het aantal frames ruwweg te halveren reduceert de methode de verwerkingstijd op standaardcomputerhardware vrijwel evenveel en levert nog steeds merkbare snelheidswinst op moderne grafische kaarten. Voor real-world systemen die in realtime moeten reageren—zoals bewaking, autonome robots of mobiele apps—is deze werklastreductie cruciaal. De studie laat zien dat een zorgvuldig ontworpen afstandsmaat kan fungeren als een slimme poortwachter, die kiest welke frames aandacht verdienen en welke veilig kunnen worden overgeslagen.
Conclusie voor dagelijks gebruik
In eenvoudige bewoordingen toont dit werk aan dat computers niet elk afzonderlijk frame hoeven te bekijken om te begrijpen wat er in een video gebeurt. Door zich te concentreren op de momenten waarop het beeld echt verandert en bijna-identieke frames te negeren, behoudt de voorgestelde techniek de essentie van een handeling terwijl de hoeveelheid data drastisch wordt teruggebracht. Dit maakt hoogwaardige videoanalyse praktischer op beperkte hardware en opent de deur naar snellere, efficiëntere tools om de groeiende vloed van visuele informatie in ons dagelijks leven te analyseren.
Bronvermelding: Khan, A., Rahnama, A., Islam, A. et al. Innovative temporal summarization for complex video classification. Sci Rep 16, 7970 (2026). https://doi.org/10.1038/s41598-026-37111-y
Trefwoorden: videoklassificatie, videosamenvatting, selectie van sleutelbeelden, actieherkenning, efficiëntie in computerzicht