Clear Sky Science · nl
Class-attention pooling en token‑sparse vision transformers voor de interpretatie van thoraxfoto's
Slimmere röntgenfoto's voor een wereldwijde longziekte
Tuberculose blijft een van de dodelijkste infectieziekten ter wereld, en thoraxfoto’s zijn vaak de eerste en soms enige beeldvormingstest die beschikbaar is in drukke klinieken, vooral in landen met lage en middeninkomens. Het lezen van deze scans is echter moeilijk en tijdrovend, zelfs voor deskundigen. Deze studie beschrijft een kunstmatig‑intelligentiesysteem dat niet alleen met hoge nauwkeurigheid tekenen van tuberculose op thoraxfoto’s detecteert, maar artsen ook precies laat zien welke delen van de longen de beslissing beïnvloedden, met als doel vertrouwen te scheppen en snellere, consistentere diagnoses te ondersteunen.
Waarom het interpreteren van thoraxbeelden zo lastig is
Thoraxfoto’s zijn goedkoop, snel en ruim beschikbaar, waardoor ze aantrekkelijk zijn voor massale screening. Het probleem is dat tuberculose zich subtiel kan presenteren en gemakkelijk gemist wordt, vooral wanneer beelden ruis bevatten, onder‑ of overbelicht zijn, of gemaakt zijn met verouderde apparatuur. Lezers kunnen het onderling oneens zijn, en drukke klinieken kunnen radiologen overweldigen. Traditionele computermethoden probeerden dit op te lossen door handgemaakte kenmerken uit beelden te meten en die in standaard machine‑learningmodellen te voeren, maar deze vroege systemen hadden moeite wanneer scans uit nieuwe ziekenhuizen kwamen of onder andere technische omstandigheden waren genomen.
Van neurale netwerken naar aandachtgerichte vision‑modellen
Deep learning, met name convolutionele neurale netwerken, bracht verbetering doordat patronen direct uit pixels werden geleerd en sterke resultaten bereikte op tuberculosedatasets. Deze netwerken richten zich echter voornamelijk op lokale buurtgebieden in het beeld en kunnen bredere patronen die beide longen overspannen missen. Nieuwere modellen, vision transformers genoemd, zien een röntgenfoto als een raster van kleine patches en leren hoe elke patch zich verhoudt tot alle andere, waardoor structurele relaties op lange afstand worden vastgelegd. Hoewel krachtig, kunnen standaard transformers aandacht besteden aan onbelangrijke regio’s en moeilijk te interpreteren zijn, wat vragen oproept of hun beslissingen overeenkomen met klinische redenering.
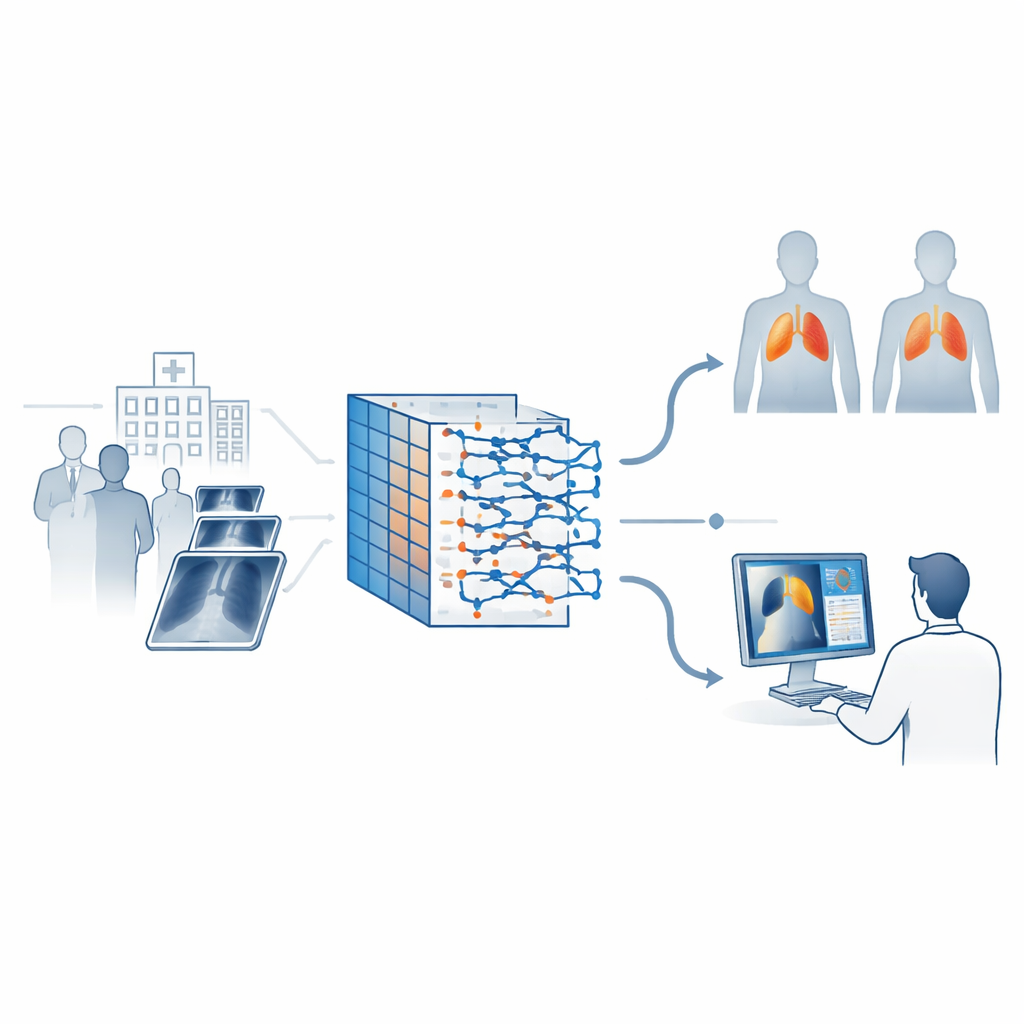
Een op maat gemaakte AI‑pipeline voor longscans
De auteurs ontwerpen een aangepaste vision transformer om deze zwaktes bij thoraxfoto’s aan te pakken. Eerst wordt elk beeld zorgvuldig voorbewerkt: het wordt geschaald, genormaliseerd en vaak door een contrastverbeteringstechniek gehaald die zwakke longlaesies laat opvallen zonder over‑verscherping. Een lichte convolutionele fase aan het begin van het model haalt fijne details zoals randen en texturen naar boven die van belang zijn in medische beelden. De scan wordt vervolgens in kleine patches verdeeld, waarvan elke patch wordt omgezet in een token dat de transformer kan verwerken.
Het model leren waar het moet kijken
Om het systeem te helpen de anatomie te volgen, gebruikt het model een position‑encoding‑mechanisme dat informatie injecteert over waar elke patch in de longen ligt, in plaats van alle locaties als verwisselbaar te behandelen. Het introduceert ook speciale "class"‑tokens, één per ziektecategorie, die leren het meest relevante bewijs uit alle patches te verzamelen. Een sparsity‑strategie stimuleert het netwerk om te vertrouwen op slechts een subset van de meest informatieve tokens, en zo achtergrondpatronen en ruis te negeren. Het trainingsrecept bevat technieken zoals willekeurig weggooien van tokens, zorgvuldige leer‑schaalschema’s en mixed‑precision berekeningen, allemaal gekozen om het leren op beperkte medische data te stabiliseren en overfitting aan eigenaardigheden van de trainingsbeelden te vermijden.
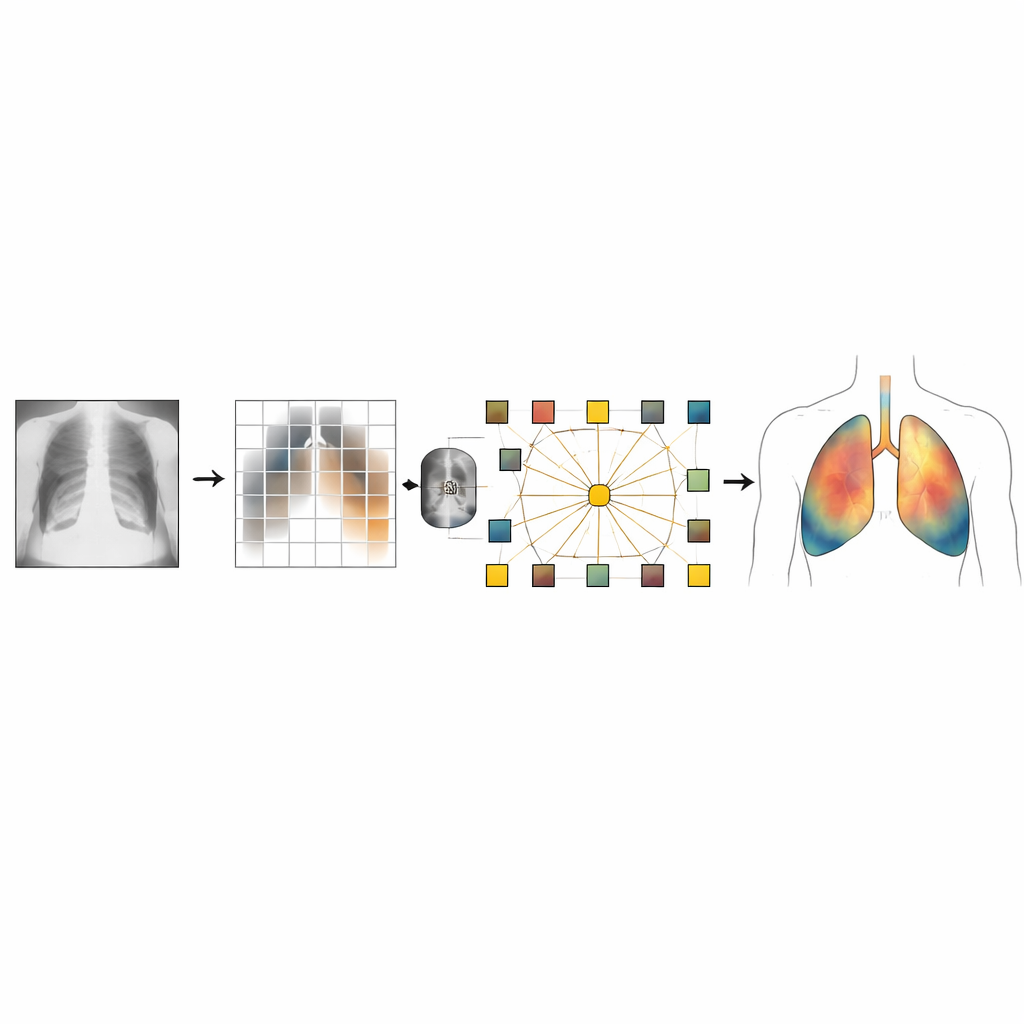
Zien wat de AI ziet
Cruciaal is dat het systeem is opgebouwd om zichzelf uit te leggen. Na het doen van een voorspelling van "tuberculose" of "normaal" genereert het model heatmaps met een methode die bekendstaat als Grad‑CAM. Deze gekleurde overlays benadrukken welke longregio’s de beslissing het meest beïnvloedden. De auteurs ontwerpen hun uitleg‑pipeline om evenwichtige voorbeelden van zowel zieke als gezonde gevallen te tonen, zodat radiologen kunnen verifiëren dat het hulpmiddel naar klinisch relevante structuren kijkt in plaats van naar irrelevante artefacten. Op twee open tuberculosedatasets bereikte de aanpak validatienauwkeurigheid rond 98 procent en een area‑under‑curve dicht bij perfecte discriminatie, hoewel de auteurs waarschuwen dat hun beeldniveau‑datasplit de prestaties in de echte wereld iets kan overschatten en dat extern testen nog nodig is.
Wat dit betekent voor toekomstige zorg
In eenvoudige bewoordingen toont dit werk een AI‑systeem dat snel en nauwkeurig waarschijnlijk tuberculosegevallen op thoraxfoto’s kan signaleren en tegelijkertijd een duidelijke visuele "kaart" van zijn redenering kan geven. Een dergelijk hulpmiddel kan helpen bij triage in klinieken met beperkte middelen, het aantal gemiste gevallen verminderen en een consistente second opinion voor radiologen bieden. Tegelijk benadrukken de auteurs dat hun model alleen op twee openbare datasets is getest, zich richt op één ziekte‑label en nog niet volledig klinisch gevalideerd is. Toekomstige stappen omvatten het uitbreiden van de methode naar meerdere long‑aandoeningen, het aanpassen aan 3D‑scans zoals CT, het valideren van de verklaringen met radiologen en het testen in verschillende ziekenhuizen. Desondanks markeert de studie een veelbelovende stap naar AI die niet slechts nauwkeurig is, maar ook transparant en betrouwbaar in de strijd tegen tuberculose.
Bronvermelding: Lokunde, V., Sundar, K., Khokhar, A. et al. Class-attention pooling and token sparsity based vision transformers for chest X-ray interpretation. Sci Rep 16, 8035 (2026). https://doi.org/10.1038/s41598-026-37109-6
Trefwoorden: tuberculose, thoraxfoto, vision transformer, verklaarbare AI, medische beeldvorming