Clear Sky Science · nl
Opbouw en toepassing van een kennisgrafiek voor documenten met zaadkwaliteitsnormen
Waarom zaadregels van belang zijn voor ieders voedsel
Achter iedere zak rijst of ieder pakje groentezaad schuilen technische normen die op de achtergrond oogsten en voedselzekerheid beschermen. Die regels voor zaadkwaliteit staan echter vaak verstopt in uitgebreide PDF-documenten die moeilijk te doorzoeken of te interpreteren zijn voor boeren, toezichthouders en bedrijven. Deze studie toont aan dat het omzetten van die statische documenten naar een levend “kaartbeeld” van onderling verbonden feiten — een kennisgrafiek — landbouwnormen transparanter, doorzoekbaarder en klaar voor het digitale tijdperk van de landbouw kan maken. 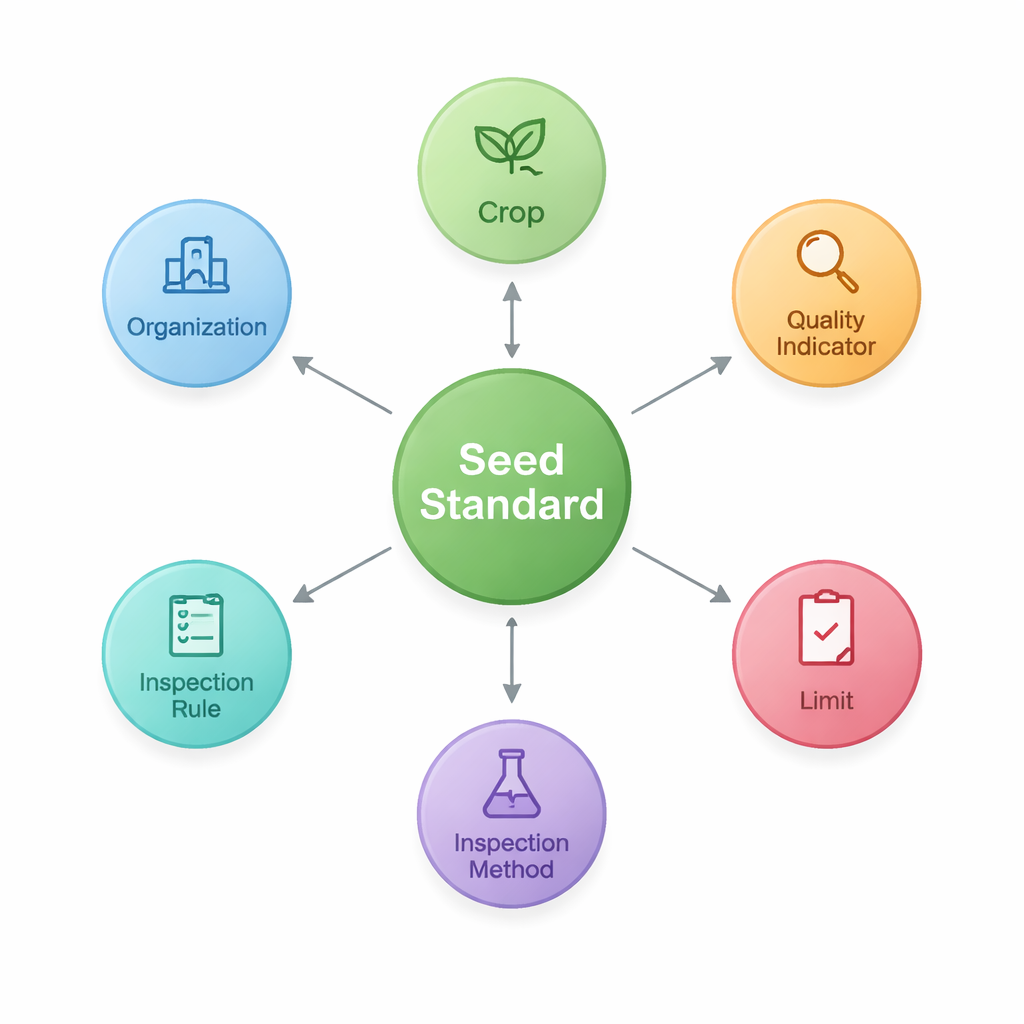
Van papieren normen naar slimme informatie
Zaadkwaliteitsnormen geven aan wat als acceptabel zaad geldt: hoe zuiver een partij moet zijn, hoeveel zaden moeten kiemen, hoeveel vocht is toegestaan en welke methoden gebruikt worden om deze eigenschappen te testen. In China is het aantal van dergelijke documenten sterk toegenomen en veel bestaan nog alleen als gescande bladen of ongestructureerde tekst. Eenvoudig trefwoordzoeken schiet tekort bij praktische vragen zoals “Wat zijn de zuiverheidsgrenzen voor dit gewas?” of “Welke regeling heeft een oudere vervangen?”. De auteurs betogen dat om het tempo van veranderingen in de landbouw bij te houden, deze normen moeten verschuiven van mensleesbare pagina’s naar machinebegrijpelijke kennis die snelle zoekopdrachten, vergelijkingen en geautomatiseerde controles mogelijk maakt.
Een kaart van zaadkennis bouwen
Om dit te bereiken ontwerpen de onderzoekers eerst een ‘ontologie’ — een gedeeld bouwplan dat de belangrijkste bouwstenen van zaadnormen en hun onderlinge verbindingen definieert. Ze identificeren zeven kernsoorten entiteiten, waaronder de norm zelf, het gewas waarop die betrekking heeft, kwaliteitsindicatoren zoals zuiverheid of kiemkracht, de numerieke grenzen voor die indicatoren, de inspectiemethoden en -regels, en de organisaties die de documenten opstellen of publiceren. Deze structuur legt patronen vast zoals “Gewas–Kwaliteitsindicator–Grens”, die in de landbouw bijzonder belangrijk zijn. Met dit bouwplan slaan ze vervolgens de geëxtraheerde feiten op als knopen en links in een grafendatabase (Neo4j), en creëren zo een netwerk van 2.436 entiteiten verbonden door 3.011 relaties.
Regels combineren met machine learning
De echte uitdaging is het zuiver en betrouwbaar halen van feiten uit rommelige brondocumenten. Zaadnormen combineren netjes geformatteerde tabellen, strikte metadata op de voorpagina en lange, vrij lopende tekstclausules. Geen enkele techniek dekt dit allemaal goed af. Het team bouwt daarom een hybride extractiesysteem. Ze gebruiken nauwkeurige regelpatronen (regular expressions) om gestructureerde tabellen en basale documentinformatie te lezen, die meestal vaste formaten volgen. Voor de complexere narratieve tekst — zoals gedetailleerde inspectieregels — trainen ze een moderne taalmodelpijplijn genaamd BERT–BiLSTM–CRF om sleuteltermen, codes en technische uitdrukkingen te herkennen. Dit model leert van zorgvuldig gelabelde voorbeelden en kan entiteiten signaleren, zelfs wanneer die in gevarieerde bewoordingen en lange zinnen voorkomen. 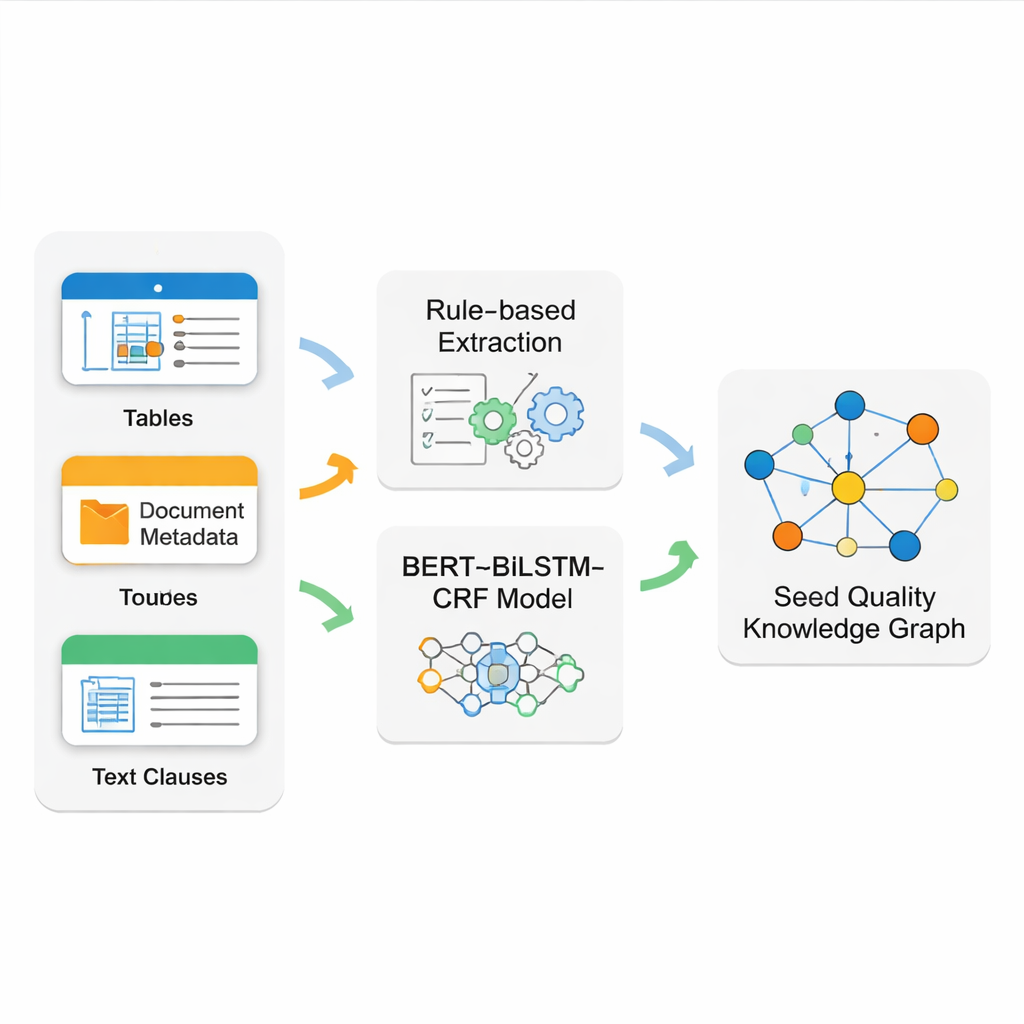
Hoe goed het systeem in de praktijk werkt
Bij tests presteert de hybride benadering sterk. Het taalmodel behaalt een totale F1-score (een balans tussen nauwkeurigheid en volledigheid) van ongeveer 91,6%, en overtreft twee veelgebruikte basismodellen. Het is bijzonder goed in het vinden van gestructureerde elementen zoals normcodes en blijft robuust bij moeilijkere taken zoals lange inspectieregels. Zodra al deze informatie in de kennisgrafiek is geladen, kunnen gebruikers visueel verkennen hoe een bepaalde norm zich verhoudt tot eerdere versies, welke organisaties eraan hebben gewerkt, welke gewassen en indicatoren hij dekt en welke testmethoden hij voorschrijft. In plaats van lange pdf’s door te bladeren kunnen toezichthouders en zaadbedrijven gerichte zoekopdrachten uitvoeren en binnen enkele seconden verbonden resultaten zien.
Wat dit betekent voor boeren en voedselsystemen
Voor niet-specialisten biedt dit een slimmere manier om de regels te beheren die zaden betrouwbaar en gewassen productief houden. De studie laat zien dat door een helder conceptueel ontwerp te combineren met zowel regelgebaseerde als leergebaseerde extractie het mogelijk is verspreide zaadnormen om te zetten in een samenhangende, doorzoekbare kennisbasis. Dit legt de technische basis voor “SLIMME” normen die computers kunnen lezen, kruischecken en bijwerken naarmate regelgeving verandert. Op de lange termijn kunnen zulke hulpmiddelen boeren en agribedrijven helpen snel te bevestigen of zaden aan de actuele kwaliteitseisen voldoen, toezichthouders ondersteunen bij het volgen van herzieningen en lacunes, en bijdragen aan stabielere oogsten en voedselzekerheid.
Bronvermelding: Yang, Z., He, Q. & Zhang, J. Construction and application of knowledge graph for seed quality standard documents. Sci Rep 16, 5997 (2026). https://doi.org/10.1038/s41598-026-37084-y
Trefwoorden: zaadkwaliteitsnormen, kennisgrafiek, digitale landbouw, named entity recognition, slimme normen