Clear Sky Science · nl
Kennis-gegronde large language model voor het genereren van gepersonaliseerde sporttrainingsplannen
Slimmere trainingsschema's voor iedereen
De meeste fitnessapps beloven gepersonaliseerde training, maar veel vertrouwen nog steeds op generieke sjablonen die negeren hoe jouw lichaam er daadwerkelijk voor staat. Dit artikel introduceert LLM-SPTRec, een nieuw systeem dat gebruikmaakt van dezelfde soort large language models achter moderne chatbots, gecombineerd met gecontroleerde sportswetenschappelijke kennis en gegevens van wearables, om veiligere en effectievere trainingsschema's te bouwen. Voor iedereen die zich heeft afgevraagd waarom zijn app steeds de verkeerde oefeningen voorstelt — of zich zorgen maakte of door AI gemaakte gezondheidsadviezen wel veilig zijn — laat dit werk zien hoe digitale coaching zowel persoonlijker als wetenschappelijker kan worden gemaakt.
Waarom traditionele fitnessapps tekortschieten
Conventionele aanbevelingssystemen, zoals die films of producten aanraden, hebben moeite wanneer ze op lichaamsbeweging worden toegepast. Ze kopiëren vaak standaardtemplates, hebben problemen met beperkte data voor nieuwe gebruikers en kijken zelden naar hoe je lichaam van dag tot dag verandert. Erger nog, ze zijn niet ontworpen voor beslissingen waarbij veiligheid belangrijk is. Algemeen doeleinde taalmodellen zijn goed in het praten over workouts, maar omdat ze zijn getraind op brede internettekst, kunnen ze risicovolle adviezen "hallucineren" of belangrijke rustdagen overslaan. De auteurs betogen dat voor het plannen van trainingen — waar slecht advies kan leiden tot blessures of overtraining — AI geworteld moet zijn in geverifieerde sportswetenschap en de veranderende toestand van een persoon in de tijd moet volgen.
Een rijk beeld van het individu opbouwen
Centraal in LLM-SPTRec staat een module die een gedetailleerde momentopname van elke gebruiker maakt. In plaats van alleen leeftijd, geslacht of ervaringsniveau op te slaan, fuseert het systeem drie soorten informatie: statische kenmerken (zoals trainingsgeschiedenis), dynamische signalen (zoals hartslag, hartslagvariabiliteit, slaapscore en eerdere trainingen van wearables en logs) en vrije-tekstdoelen die door de gebruiker zijn geschreven. Een transformer-gebaseerd model — verwant aan de technologie achter moderne taalmodellen — leert patronen in deze tijdreeksgegevens, bijvoorbeeld hoe een zware training gisteren de gereedheid van vandaag kan beïnvloeden. Een attentiemechanisme weegt vervolgens welke signalen op een gegeven moment het belangrijkst zijn en combineert ze tot een enkele numerieke representatie van de huidige toestand van de gebruiker.
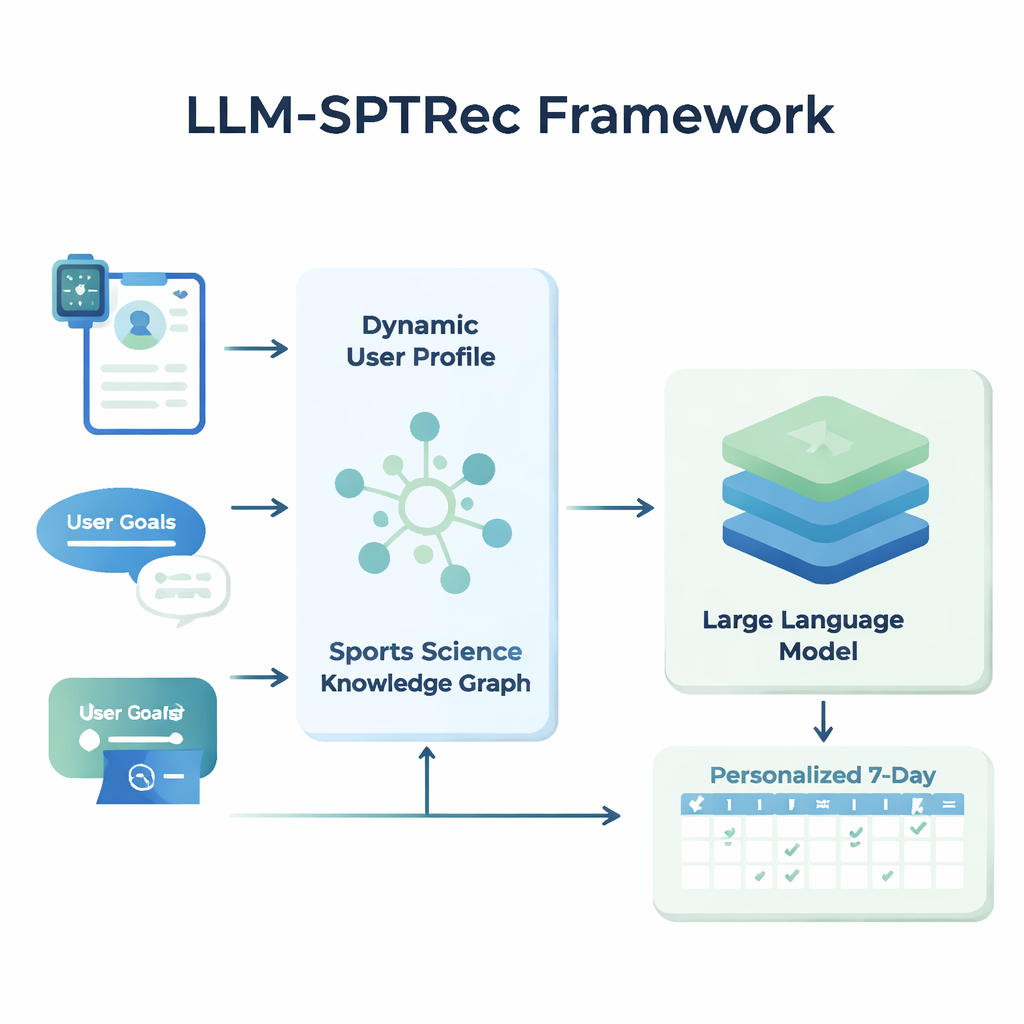
De AI echte sportswetenschap bijbrengen
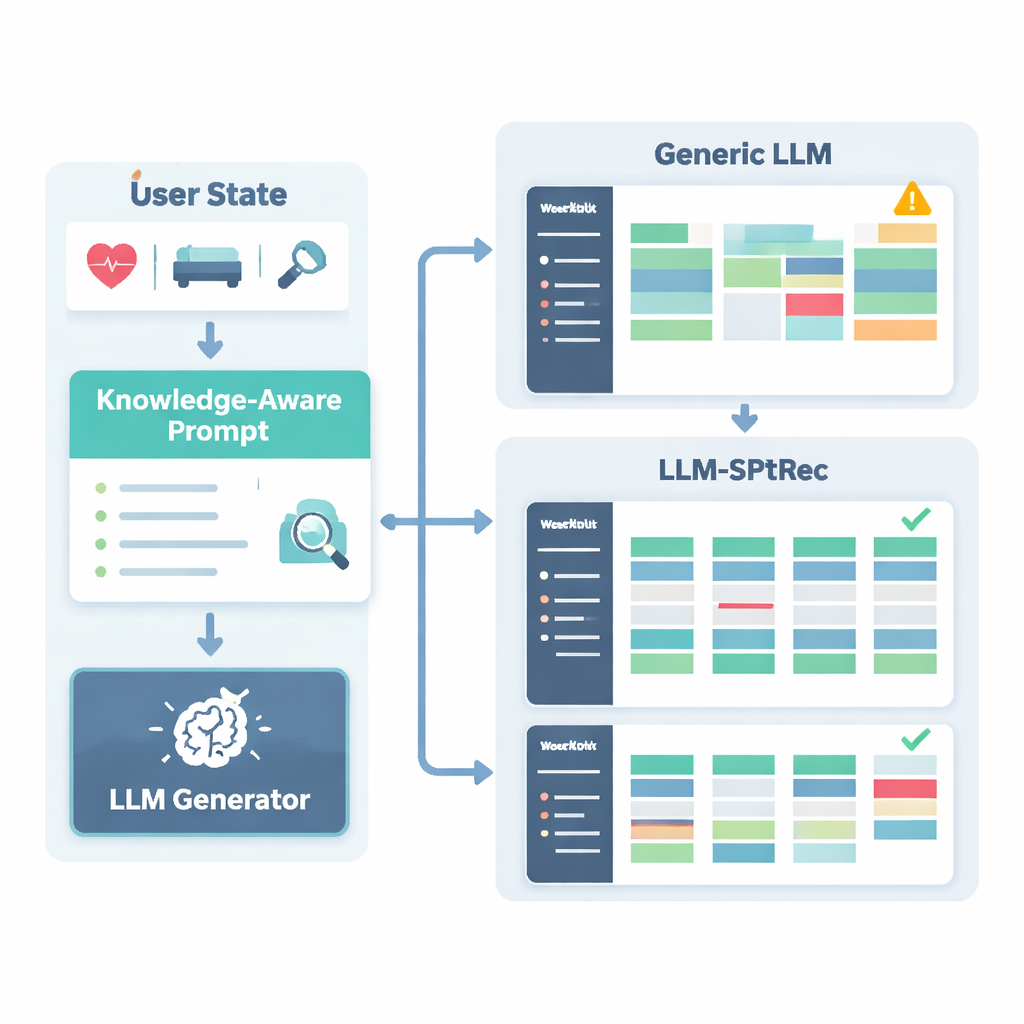
Om onveilige of onwetenschappelijke aanbevelingen te voorkomen, bouwden de onderzoekers een Sports Science Knowledge Graph, in wezen een gestructureerde kaart van door experts goedgekeurde feiten. Deze bevat duizenden items die oefeningen koppelen aan spieren, bewegingssoorten, apparatuur, veelvoorkomende blessures en trainingsprincipes zoals progressieve overbelasting en specificiteit. Voor elke gebruiker haalt het systeem de meest relevante delen van deze grafiek naar boven — bijvoorbeeld welke spieren bij de bankdrukken worden aangesproken en welke bewegingen slecht zijn bij schouderproblemen — en zet die om in leesbare tekst die samen met het gebruikersprofiel in het taalmodel wordt gevoed. Het taalmodel krijgt vervolgens, via een zorgvuldig ontworpen prompt, de opdracht om een meerdaags trainingsplan in een gestructureerd formaat te genereren, met inachtneming van regels zoals het rouleren van spiergroepen tussen dagen en het vermijden van bekende contra-indicaties.
Plannen gestructureerd, veilig en steeds beter houden
LLM-SPTRec doet meer dan alleen tekst genereren. Een validatiemodule controleert elk plan aan de hand van harde regels, zoals het niet overbelasten van dezelfde primaire spiergroepen op opeenvolgende dagen, en markeert conflicten met blessurerisico's die in de kennisgrafiek zijn opgeslagen. Als een plan deze controles niet doorstaat, vraagt het systeem het model opnieuw en wijst expliciet op wat er misging, totdat er een veilig plan is geproduceerd. Het trainen van het systeem gebeurt ook in twee fasen. Eerst leert het van een grote verzameling door experts ontworpen schema's. Daarna wordt het verder verfijnd met behulp van feedback, waarbij gesimuleerde of echte gebruikersbeoordelingen plannen belonen die coherent, afgestemd op doelen en prettig om te volgen zijn, terwijl onveilige suggesties zwaar worden bestraft. Deze feedbacklus stuurt het model richting aanbevelingen die in de praktijk beter werken.
Hoe het systeem in de praktijk presteert
De auteurs testten LLM-SPTRec op een grote, real-world dataset genaamd SportFit-1M, die geanonimiseerde gegevens van fitnessapps en wearables combineert en tienduizenden gebruikers en miljoenen trainingslogs en fysiologische registraties omvat. Ze vergeleken hun systeem met sterke baselines: klassieke collaborative filtering, een sequentiemodel dat alleen naar eerdere keuzes kijkt, een geavanceerde knowledge-graph recommender en een algemeen taalmodelgebaseerd framework. LLM-SPTRec versloeg ze allemaal, niet alleen bij het kiezen van geschikte oefeningen, maar — belangrijker nog — bij het produceren van complete plannen die experts als coherenter en beter afgestemd op gebruikersdoelen beoordeelden. Voorspelde gebruikerstevredenheidsscores waren ook hoger, en een kleine menselijke studie met gecertificeerde trainers beoordeelde de veiligheid veel beter dan bij een algemeen taalmodel zonder sportspecifieke grounding.
Wat dit betekent voor toekomstige digitale coaching
Voor een leek is de boodschap dat slimmer, veiliger AI-coaching mogelijk is wanneer drie ingrediënten samenkomen: rijke gegevens van je apparaten, deskundige sportswetenschap gecodeerd als gestructureerde kennis en krachtige taalmodellen waarvan de creativiteit zorgvuldig wordt geleid en gecontroleerd. LLM-SPTRec toont aan dat een dergelijke combinatie adaptieve, dag-tot-dag trainingsschema's kan genereren die de veranderende staat van je lichaam en je persoonlijke doelen respecteren, terwijl het risico op schadelijk of onsamenhangend advies wordt verminderd. Vooruitkijkend zou hetzelfde recept kunnen uitbreiden naar voeding, revalidatie bij blessures of zelfs mentale gezondheid, en wijzen op een toekomst waarin AI-assistenten minder als generieke chatbots en meer als kundige, veiligheid-bewuste digitale coaches optreden.
Bronvermelding: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
Trefwoorden: gepersonaliseerde training, sportscience AI, fitnessaanbeveling, wearable-gegevens, kennisgrafiek