Clear Sky Science · nl
De evolutie van objectdetectie: van CNN's naar transformers en multimodale fusie
Computers leren alledaagse objecten te zien
Elke keer dat je telefoon vrienden tagt op een foto, een auto een voetganger ontdekt, of een medisch hulpmiddel een tumor op een scan markeert, werkt er een stil krachtige technologie: objectdetectie. Dit overzichtsartikel legt uit hoe objectdetectie zich het afgelopen decennium snel heeft ontwikkeld, van vroege beeldverwerkingstrucs tot de huidige op transformers gebaseerde en multisensor-systemen, en waarom deze vooruitgang belangrijk is voor veiligere straten, slimmere robots en nauwkeurigere medische diagnoses.
Van pixels naar herkenbare dingen
Objectdetectie is de taak van het vinden en labelen van specifieke items in afbeeldingen of video—auto's, fietsers, dieren, medische structuren en meer. Het artikel begint met een overzicht van hoe breed deze capaciteit wordt toegepast: in autonoom rijden, bewaking, medische beeldvorming en robotica. Vroege systemen vertrouwden op handgemaakte regels om vormen en texturen te herkennen, maar moderne benaderingen leren rechtstreeks uit data met deep learning. Twee brede families domineren nu: convolutionele neurale netwerken (CNN's), die zeer goed zijn in het herkennen van lokale patronen zoals randen en hoeken, en transformers, die uitblinken in het begrijpen van de bredere scène en relaties tussen verre objecten. Samen bepalen zij hoe huidige machines de wereld "zien".
Hoe klassieke vision-engines werken
Op CNN gebaseerde methoden voeden nog steeds veel realtime-toepassingen. Ze scannen beelden met kleine filters om rijkere en rijkere featurkaarten op te bouwen, en voeden die vervolgens in detectiekoppen die begrenzingsvakken tekenen en labels toekennen. Het overzicht legt twee hoofdroutes uit. Tweefasige systemen zoals Faster R-CNN doen eerst voorstellen voor waarschijnlijke objectregio's en verfijnen die vervolgens, wat vaak hoge nauwkeurigheid oplevert tegen een rekenkundige prijs. Eenfasige systemen zoals de YOLO-familie slaan de voorstelstap over en voorspellen vakken en labels in één doorgang, waarbij ze wat nauwkeurigheid inruilen voor snelheid. Recente versies van YOLOv5 en YOLOv8 zijn zwaar getuned—met slimmere feature-piramides voor kleine objecten, lichte bouwblokken voor randapparaten en verbeterde verliesfuncties—om honderden frames per seconde te bereiken terwijl ze competitief blijven op zware benchmarks.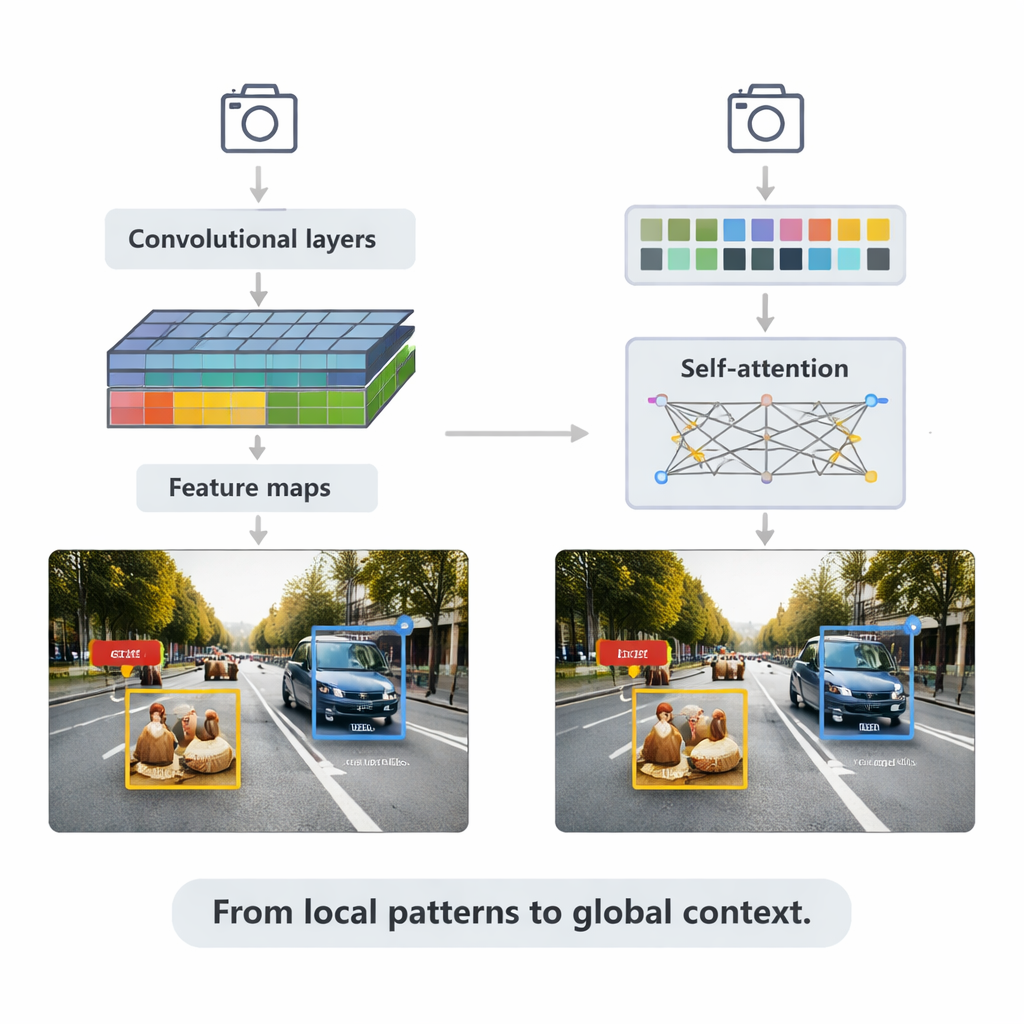
Transformers en de kracht van context
Het artikel richt zich vervolgens op transformers, een nieuwere architectuur ontleend aan taalmodellen. In plaats van zich alleen te richten op lokale buurten gebruiken transformers "self-attention" om elk beeldpatch met elk ander patch te vergelijken en te leren welke regio's het meest relevant zijn voor een beslissing. Detection Transformer (DETR) en zijn opvolgers doen veel handmatige trucs af en streven naar schonere, end-to-end pijplijnen. Varianten zoals Deformable DETR en RT-DETR verminderen de rekenbelasting en verbeteren de trainingssnelheid, waardoor transformers realtime kunnen draaien en sommige van de hoogste nauwkeurigheidsscores behalen op de veelgebruikte COCO-benchmark. Deze modellen blinken vooral uit in complexe scènes met overlappende objecten en verwarrende achtergronden, waar globale context helpt om bijvoorbeeld een voetganger die gedeeltelijk verborgen is achter een auto te onderscheiden.
Camera's, lasers en taal mengen
Reële omstandigheden—nevel, duisternis, schittering, rommel—overweldigen vaak enkelvoudige sensoren. Een belangrijk aandachtspunt van het overzicht is multimodale fusie: het combineren van data van gewone camera's (RGB), dieptesensoren zoals LiDAR, thermische camera's en zelfs tekstbeschrijvingen. De auteurs introduceren een heldere taxonomie voor hoe deze menging kan plaatsvinden: early fusion vermengt rauwe data aan het begin, middle fusion mengt geleerde features binnen het netwerk, en late fusion combineert de outputs van afzonderlijke detectoren aan het eind. Moderne "fusion transformers" gebruiken attentie-mechanismen om deze stromen op één lijn te brengen, zodat nauwkeurige afstandsmetingen van LiDAR, rijke verschijning uit RGB-beelden en semantische aanwijzingen uit taal elkaar versterken. Deze aanpak verbetert detectie in autonoom rijden, medische beeldvorming, videoanalyse en tekstrijke scènes.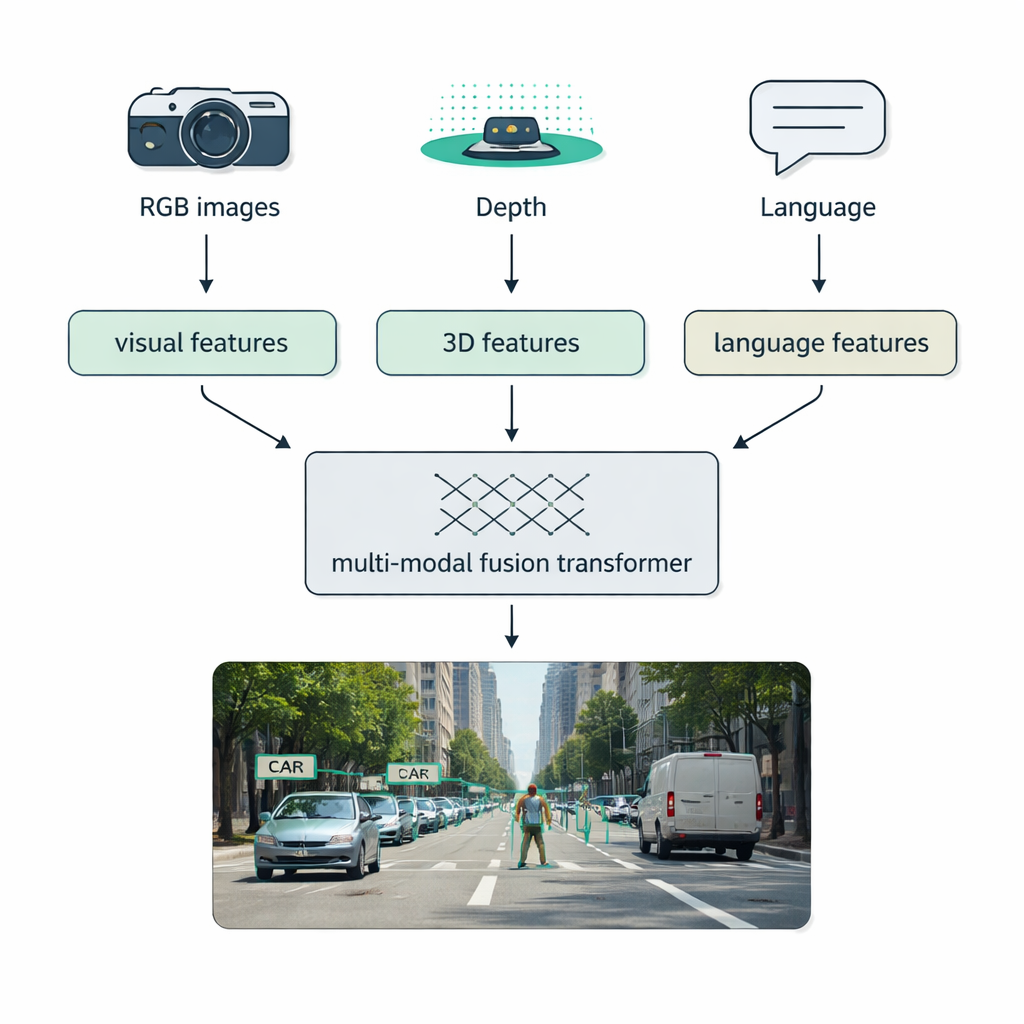
Benchmarks, grenzen en wat komt
Over standaardtests zoals MS COCO vergelijkt het overzicht CNN- en transformerdetectoren op zowel nauwkeurigheid als snelheid. Klassieke tweefasige CNN's blijven sterk maar zijn trager, YOLO-achtige modellen domineren op lichte hardware, en transformergebaseerde systemen lopen nu voorop in nauwkeurigheid terwijl ze de snelheidskloof dichten. Gespecialiseerde infraroodmethoden behalen zeer hoge scores onder slechte zichtomstandigheden. Toch blijven er lastige problemen: zeer kleine of extreem grote objecten, zware occlusie, veranderend weer en licht, en de noodzaak om betrouwbaar te draaien op kleine apparaten. Vooruitkijkend benadrukken de auteurs trends richting verenigde perceptiemodellen die detectie, segmentatie en captioning samen afhandelen, en "foundation models" die visie en taal samenvoegen om objecten te herkennen die in platte tekst worden beschreven, zelfs als ze nooit in de trainingsdata gelabeld zijn geweest.
Waarom dit ertoe doet in het dagelijks leven
Voor niet-specialisten is de kernboodschap dat objectdetectie verschuift van smalle, handgetunede systemen naar flexibele, algemeen inzetbare visie-engines die zich kunnen aanpassen aan nieuwe taken, nieuwe omgevingen en nieuwe sensoren. CNN's leveren snelle, efficiënte patroonherkenning; transformers voegen een meer globale, contextbewuste begrip toe; en multimodale fusie betrekt extra aanwijzingen uit diepte, temperatuur en taal. Samen beloven deze vorderingen auto's die gevaren beter anticiperen, hulpmiddelen die artsen met meer vertrouwen ondersteunen, en huishoudelijke apparaten die veiliger en intelligenter met hun omgeving omgaan—en brengen ze machinale waarneming dichter bij de rijkdom van menselijk zicht.
Bronvermelding: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
Trefwoorden: objectdetectie, computer vision, deep learning, transformermodellen, multimodale fusie