Clear Sky Science · nl
Vaststellen van functionele mobiliteit in elektronische medische dossiers met behulp van grote taalmodellen
Waarom loopsnelheid een krachtig gezondheidssignaal is
Naarmate mensen ouder worden, letten artsen niet alleen meer op hoe lang we leven, maar ook op hoe goed we ons kunnen verplaatsen, lopen en voor onszelf kunnen zorgen. Moeite met opstaan uit een stoel, trappen lopen of je in de stad verplaatsen duidt vaak al lang voordat zich een medische crisis voordoet op achteruitgang. De meest gedetailleerde beschrijvingen van iemands dagelijkse vaardigheden staan echter meestal weggestopt in vrije‑tekstverslagen van artsen en therapeuten in elektronische medische dossiers, waar ze moeilijk door computers te vinden zijn. Deze studie onderzoekt of moderne grote taalmodellen—hetzelfde soort AI dat veel chatbots aandrijft—die notities betrouwbaar kunnen lezen en bewegingsbeschrijvingen kunnen omzetten in gestructureerde, doorzoekbare informatie.
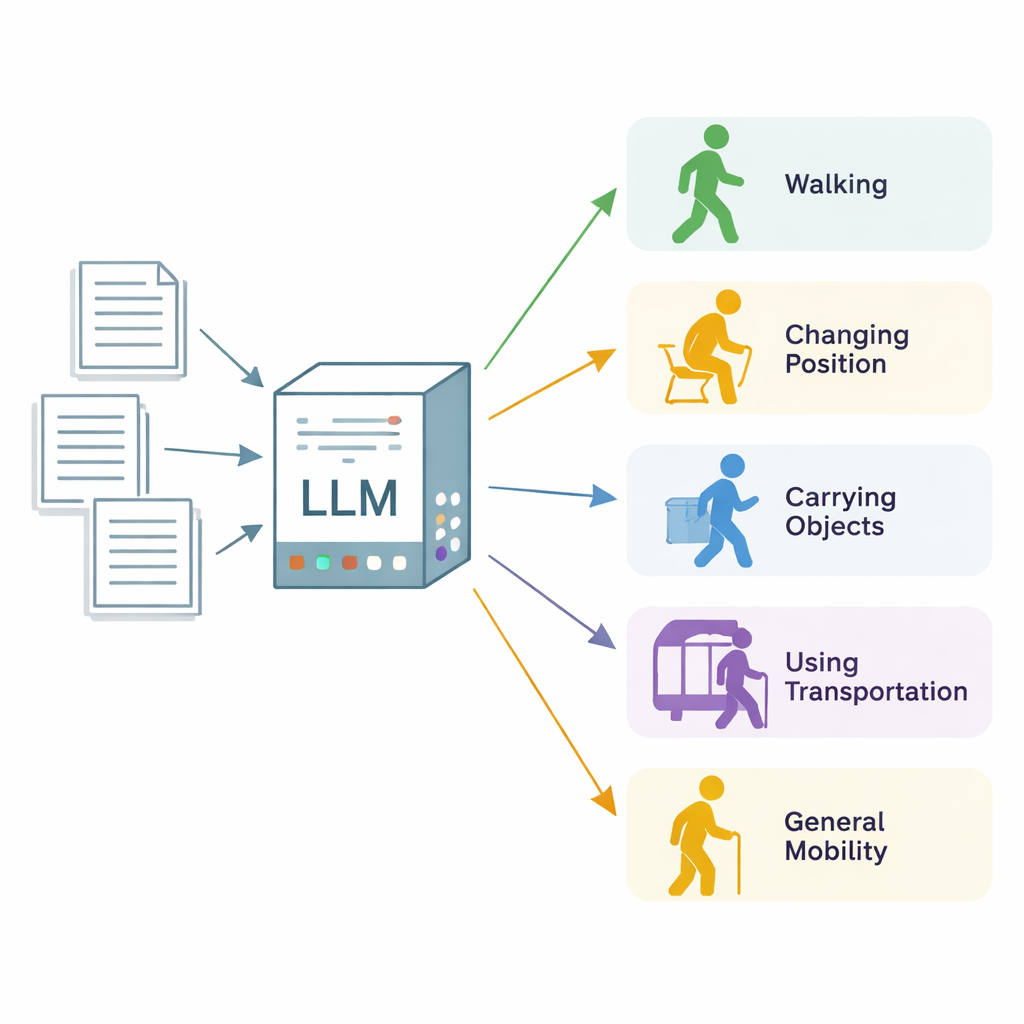
Rommelige notities omzetten in bruikbare mobiliteitsgegevens
De onderzoekers richtten zich op “functionele mobiliteitsstatus”, een brede term voor hoe goed iemand van lichaamshouding kan veranderen, kan lopen, voorwerpen kan dragen en hanteren, vervoer kan gebruiken en zich in het dagelijks leven kan verplaatsen. Ze gebruikten 600 echte klinische notities uit drie zorginstellingen in Minnesota en Wisconsin, grotendeels afkomstig van fysieke en ergotherapeuten, plus een set meer algemene poliklinische notities. Deskundige annotatoren gingen elke notitie sectie voor sectie na en labelden elk fragment dat een van de vijf mobiliteitscategorieën beschreef, waarbij ze aangaven of de patiënt duidelijk beperkt was (“gehandicapt”) of normaal functioneerde (“niet beperkt”). Deze deskundige labels dienden als gouden standaard voor de evaluatie van het AI‑systeem.
Hoe het AI‑model werd getraind om als een clinicus te lezen
Het team gebruikte Llama 3, een open‑source groot taalmodel, en voerde het uit op beveiligde lokale servers zodat patiëntgegevens het zorgsysteem nooit verlieten. In plaats van het model vanaf nul te hertrainen, ontwierpen ze zorgvuldig prompts—sets van schriftelijke instructies en definities—om het model te leren waar het op moest letten. Ze probeerden “zero‑shot” prompts, die alleen instructies geven, en “few‑shot” prompts, die ook een handvol voorbeeldnotities bevatten. Vervolgens analyseerden ze waar het model fouten maakte en ontwikkelden ze een “fout‑geïnformeerde” prompt die precies aangaf wat te includeren, wat te negeren (zoals toekomstige behandelplannen) en hoe om te gaan met lastige gevallen zoals valpartijen, duizeligheid of rolstoelgebruik. De AI kreeg voor elke notitiesectie en elke mobiliteitscategorie de vraag of mobiliteit überhaupt werd genoemd en, zo ja, of de patiënt beperkt was.
Sterke prestaties verbeteren op patiëntniveau
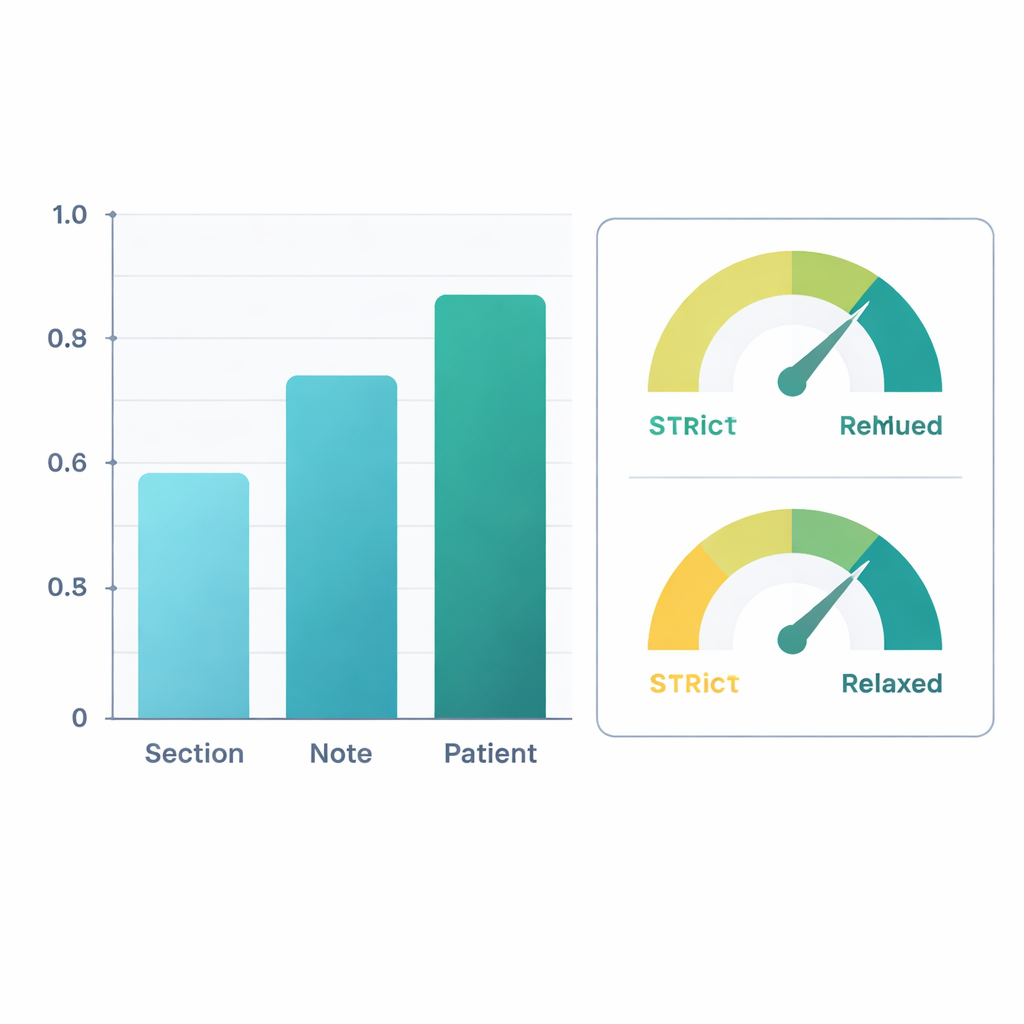
Gematst aan de deskundige labels presteerde het verfijnde systeem goed. Op het niveau van volledige patiënten—door informatie uit al hun notities te combineren—bereikte de AI een F1‑score (een gangbare nauwkeurigheidsmaat) van ongeveer 0,88 voor het eenvoudig vinden van mobiliteitsinformatie en 0,90 voor het bepalen of de persoon beperkt was. Dat betekent dat de oordelen sterk overeenkwamen met die van menselijke beoordelaars. De prestaties waren wat lager op het niveau van afzonderlijke notitiesecties, waar de bewoording schaars of dubbelzinnig kan zijn, maar de nauwkeurigheid nam toe naarmate informatie werd samengevoegd over hele notities en vervolgens over alle notities van een patiënt. In een tweede analyse telden de onderzoekers “klinisch redelijke inferenties” als correct—bijvoorbeeld aannemen dat hevige kniepijn bij lopen waarschijnlijk het lopen beperkt, zelfs als dat niet expliciet staat. Onder deze ruimere beoordeling stegen de F1‑scores op patiëntniveau boven 0,96 voor extractie en 0,95 voor classificatie van beperking.
Wat de AI verkeerd deed—en waarom dat toch relevant is
De meeste fouten kwamen voort uit het model dat tussen de regels door las. Het trok vaak conclusies over mobiliteitsproblemen op basis van pijn, duizeligheid of toekomstige therapieplannen, ook wanneer de notitie nooit duidelijk vermeldde dat de patiënt beperkt was. Andere fouten weerspiegelden grijze gebieden in de definities, zoals of herhaalde valpartijen als een loopprobleem of als een probleem met balans bij houdingsverandering moeten worden beschouwd. De klasse “mobiliteit, ongespecificeerd”, bedoeld om dagelijkse activiteiten en oefening vast te leggen, bleek bijzonder moeilijk af te bakenen. Ondanks deze problemen waren de fouten meestal klinisch gezien redelijk in plaats van willekeurig of bizar. Door het model deterministisch uit te voeren (zonder ingebouwde willekeur) op vergrendelde lokale servers, zorgde het team er ook voor dat de resultaten reproduceerbaar waren en dat de privacy van patiënten gewaarborgd bleef.
Hoe dit de zorg voor ouderen kan veranderen
Voor de leek is de conclusie dat een AI‑systeem nu routinematige notities van artsen en therapeuten goed genoeg kan lezen om samen te vatten hoe goed patiënten zich verplaatsen en waar ze moeite mee hebben. Dat betekent dat zorgsystemen veranderingen in lopen, balans en dagelijkse activiteiten in de tijd kunnen volgen zonder nieuwe vragenlijsten of tests toe te voegen, mensen met een hoog risico op vallen of ziekenhuisopnames kunnen signaleren en kunnen aangeven wie baat kan hebben bij fysiotherapie of huisveiligheidsbeoordelingen. Door miljoenen vrije‑tekstnotities om te zetten in gestructureerde mobiliteitsgegevens helpt deze aanpak artsen een beter overzicht te krijgen van hoe veroudering en ziekte het dagelijks leven beïnvloeden—en brengt de gezondheidszorg een stap dichter bij werkelijk gepersonaliseerde, op functioneren gerichte geneeskunde.
Bronvermelding: Liu, X., Garg, M., Jia, H. et al. Mobility functional status ascertainment in electronic health records using large language models. Sci Rep 16, 6045 (2026). https://doi.org/10.1038/s41598-026-37025-9
Trefwoorden: mobiliteit, elektronische medische dossiers, grote taalmodellen, functionele status, klinische AI