Clear Sky Science · nl
Een benchmark voor het beoordelen van de efficiëntie van diagnostische vraagstelling van LLM's in patiëntengesprekken
Waarom slimmer medisch vragen stellen ertoe doet
Wanneer je een arts bezoekt, komt de eerste diagnose zelden voort uit één symptoom dat je noemt. Artsen stellen meestal een reeks vervolgvragen—over timing, ernst, gerelateerde problemen—om geleidelijk te verfijnen wat er mis kan zijn. Hoe krachtig de huidige AI‑systemen ook zijn, de meeste worden nog steeds getest alsof ze meerkeuze‑examens afleggen, niet alsof ze met echte mensen praten. Dit artikel introduceert Q4Dx, een nieuwe manier om te beoordelen hoe goed grote taalmodellen (LLM's) de rol van de “nieuwsgierige arts” kunnen vervullen: het kiezen van de juiste vragen, in de juiste volgorde, om efficiënt tot de juiste diagnose te komen.
Van examenvragen naar echte gesprekken
De meeste bestaande tests voor medische AI geven modellen keurig afgebakende, volledig gespecificeerde casussen—zoals een tekstboekvraag—en vragen hen een diagnose te kiezen. Dat laat zien wat het systeem “weet”, maar niet hoe het zich zou gedragen in een rommelig, realistisch gesprek met een patiënt die details vergeet of symptomen in alledaagse bewoordingen beschrijft. De auteurs stellen dat dit een serieus blinde vlek is. In de kliniek komt informatie langzaam en vaak onnauwkeurig naar voren; de vaardigheid van een goede clinicus ligt evenveel in wat hij stelt als in wat hij al weet. Q4Dx is ontworpen om deze kloof te dichten door de focus te verschuiven van statisch vragen beantwoorden naar de strategie van het stellen van vragen in de tijd.
Het opbouwen van levensechte patiëntverhalen
Om deze nieuwe testomgeving te creëren, beginnen de onderzoekers met een zorgvuldig geselecteerde medische bron die specifieke ziekten koppelt aan kenmerkende symptoomsets. Ze selecteren willekeurig 100 van zulke ziekte‑symptoomparen en gebruiken vervolgens een AI‑model om steriele symptoomlijsten om te zetten in natuurlijk klinkende patiëntbeschrijvingen—verhalen zoals iemand ze in een spreekkamer zou vertellen. Van elk volledige geval genereren ze kortere versies waarin slechts ongeveer 80 procent of 50 procent van de sleutelverschijnselen wordt genoemd. Deze gecontroleerde “verberging” van informatie stelt hen in staat te onderzoeken hoe goed verschillende modellen zich aanpassen wanneer belangrijke aanwijzingen ontbreken of slechts worden gesuggereerd. Controles op symptoomoverlap bevestigen dat de kortere versies echt minder bruikbare informatie bevatten, niet alleen minder woorden.
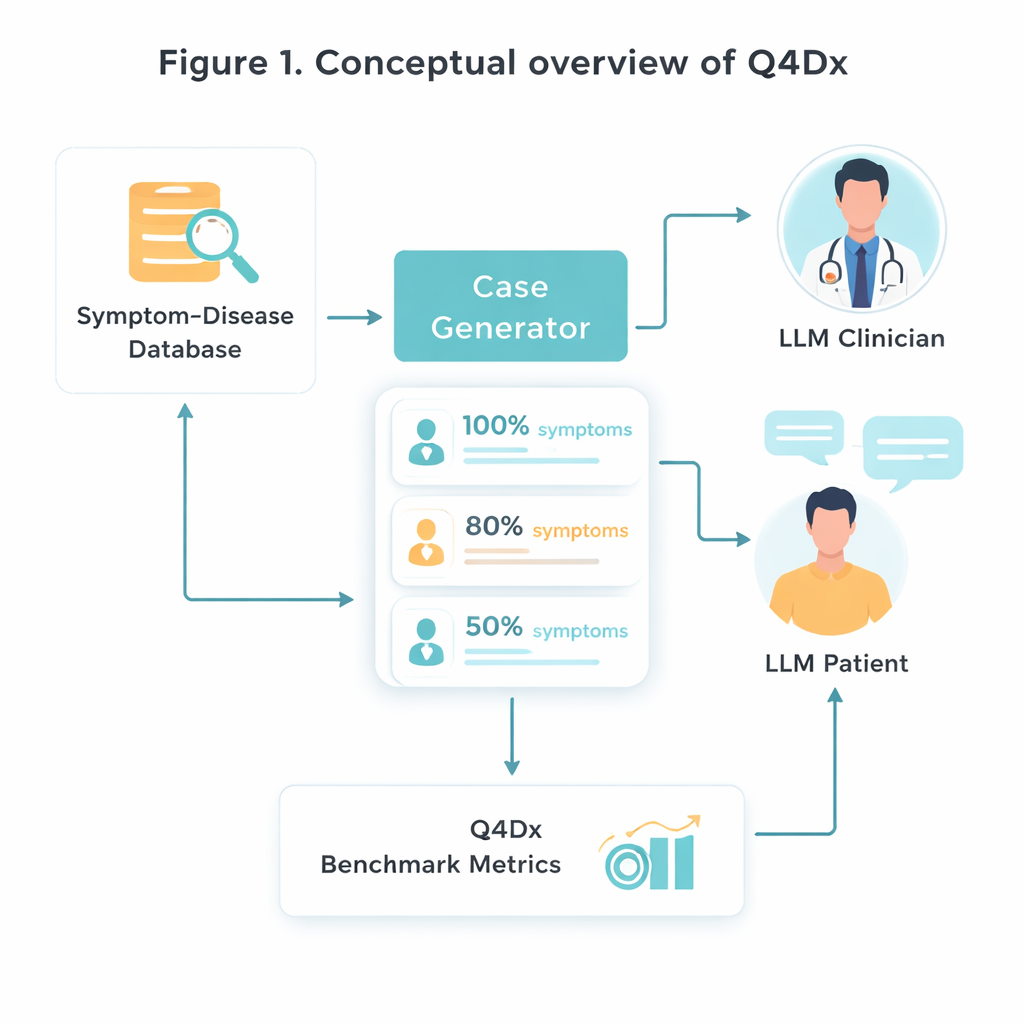
Gesimuleerde arts‑patiëntdialogen
De kern van Q4Dx is een grote verzameling gesimuleerde gesprekken tussen twee AI‑agenten. De ene speelt de rol van de patiënt en heeft volledige toegang tot de onderliggende ziekte en de volledige set symptomen. De andere fungeert als arts: die ziet aanvankelijk alleen een gedeeltelijke, mogelijk vage casusbeschrijving en moet beslissen wat hij vervolgens vraagt. Na elk antwoord van de patiënt doet de artsagent een voorlopige diagnose, waarmee een stapsgewijze weergave ontstaat van hoe zijn denken evolueert. Door alle vragen, antwoorden en tussentijdse gokjes vast te leggen, legt de benchmark niet alleen vast of het model gelijk heeft, maar ook hoe het daartoe komt. Deze door AI‑gegenereerde vraagsequenties worden gebruikt als referentiestrategieën—niet als perfecte medische waarheid, maar als een consistente maatstaf waarmee toekomstige modellen en zelfs menselijke trainees vergeleken kunnen worden.
Goede vragen meten, niet alleen juiste antwoorden
Om prestaties te beoordelen, ontwerpen de auteurs drie eenvoudige maar aanvullende maatregelen. Zero‑Shot Diagnostic Accuracy (ZDA) vraagt: als je het model meteen de volledige casus geeft, kan het dan meteen de juiste ziekte noemen? Mean Questions to Correct Diagnosis (MQD) weerspiegelt efficiëntie: gemiddeld, hoeveel patiëntvragen heeft het model nodig voordat het voor het eerst bij de juiste diagnose uitkomt, met een limiet van vijf? Ten slotte kijkt Interrogation Sequence Efficiency (ISE) naar de kwaliteit van het vraagpad zelf—hoe gelijkwaardig de door het model gekozen vragen qua betekenis zijn aan de referentie‑sequentie. Met deze metriek toont het team aan dat een krachtig algemeen model (GPT‑4.1) met volledige informatie ongeveer de helft van de tijd correct diagnosticeert, maar dat de nauwkeurigheid afneemt naarmate symptomen worden weggelaten. Tegelijkertijd slagen interactieve sessies doorgaans al na een paar zorgvuldig gekozen vragen, en stemmen de vragen na opeenvolgende beurten steeds beter overeen met strategieën van experts.

Wat dit betekent voor toekomstige medische AI
Voor niet‑specialisten is de boodschap van dit werk eenvoudig: in de geneeskunde is het stellen van slimme vragen net zo belangrijk als het hebben van de juiste antwoorden, en AI moet op beide worden beoordeeld. Q4Dx biedt een herbruikbaar, publiek beschikbaar kader om precies dat te doen. Door realistische patiëntverhalen met variërende hoeveelheden ontbrekende informatie, gedetailleerde gesprektraces en duidelijke maatstaven voor zowel nauwkeurigheid als efficiëntie te leveren, stelt de benchmark onderzoekers in staat verschillende AI‑systemen te vergelijken en ze zelfs in gecontroleerde omstandigheden tegen menselijke clinici te laten meten. In de loop der tijd kunnen instrumenten zoals Q4Dx helpen bij het trainen van veiligere, betrouwbaardere klinische assistenten en het verbeteren van hoe artsen en studenten diagnostisch interviewen leren—uiteindelijk ter ondersteuning van betere zorg voor echte patiënten.
Bronvermelding: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
Trefwoorden: medische AI, diagnostisch redeneren, klinische dialoog, grote taalmodellen, vraagstrategie