Clear Sky Science · nl
Het benchmarken van action-recognition-modellen voor zelfbeschadigingsdetectie in studio- en real-world datasets
Patiënten in de gaten houden met digitale ogen
In psychiatrische ziekenhuizen werken verpleegkundigen onvermoeibaar om patiënten veilig te houden, vooral degenen met een risico op zelfbeschadiging. Toch kan zelfs het meest toegewijde personeel niet elke kamer voortdurend in de gaten houden. Deze studie onderzoekt of kunstmatige intelligentie (AI) kan helpen door automatisch videobeelden van afdelingscamera’s te scannen om vroege signalen van zelfbeschadiging te herkennen — een extra beschermingslaag zonder menselijke zorg te vervangen.
Waarom zelfbeschadiging zo moeilijk te detecteren is
Zelfbeschadiging — elke opzettelijke verwonding die mensen zichzelf toebrengen — gebeurt vaak in korte, verborgen momenten: een snelle kras onder een deken of een klein gereedschap dat buiten het zicht wordt gebruikt. Psychiatrische afdelingen vertrouwen op regelmatige controles en camerabewaking, maar blinde hoeken, personeelsvermoeidheid en beperkte bezetting ’s nachts of tijdens feestdagen maken constante waakzaamheid onmogelijk. Tegelijkertijd roept het opnemen en delen van echte patiëntbeelden ernstige privacy- en ethische vragen op. Daardoor hadden onderzoekers weinig realistische video beschikbaar om AI-systemen te trainen die gevaarlijk gedrag in realtime zouden kunnen detecteren.
Veiligere testomgevingen voor AI opbouwen
Om dit doodpunt te doorbreken, maakten de onderzoekers twee soorten videodatasets. Ten eerste, in een studio die eruitzag als een psychiatrische kamer met vier bedden, voerden zeven jonge acteurs in patiëntenjassen zorgvuldig geplande scènes uit. Ze zochten naar alledaagse voorwerpen zoals plastic dopjes, lippenbalsemtubes of kleine spijkers en speelden korte sequenties van zelfbeschadigend gebaar op de pols, onderarm of dij, terwijl bovenliggende camera’s vanuit alle hoeken opnamen. Experts labelden elk videosegment als normaal gedrag of zelfbeschadiging, waarmee een schone, gebalanceerde verzameling van 1120 clips ontstond. Ten tweede verzamelde het team echte bewakingsbeelden van beveiligde psychiatrische afdelingen over tien maanden. Clinici doorzochten medische dossiers naar aantekeningen over gedrag zoals krabben, pulken of snijden en achterhaalden vervolgens de bijbehorende video. Nadat gezichten waren vervaagd en identificerende details waren verwijderd, stelden ze 59 clips met daadwerkelijke zelfbeschadiging en 59 normale clips samen voor vergelijking.
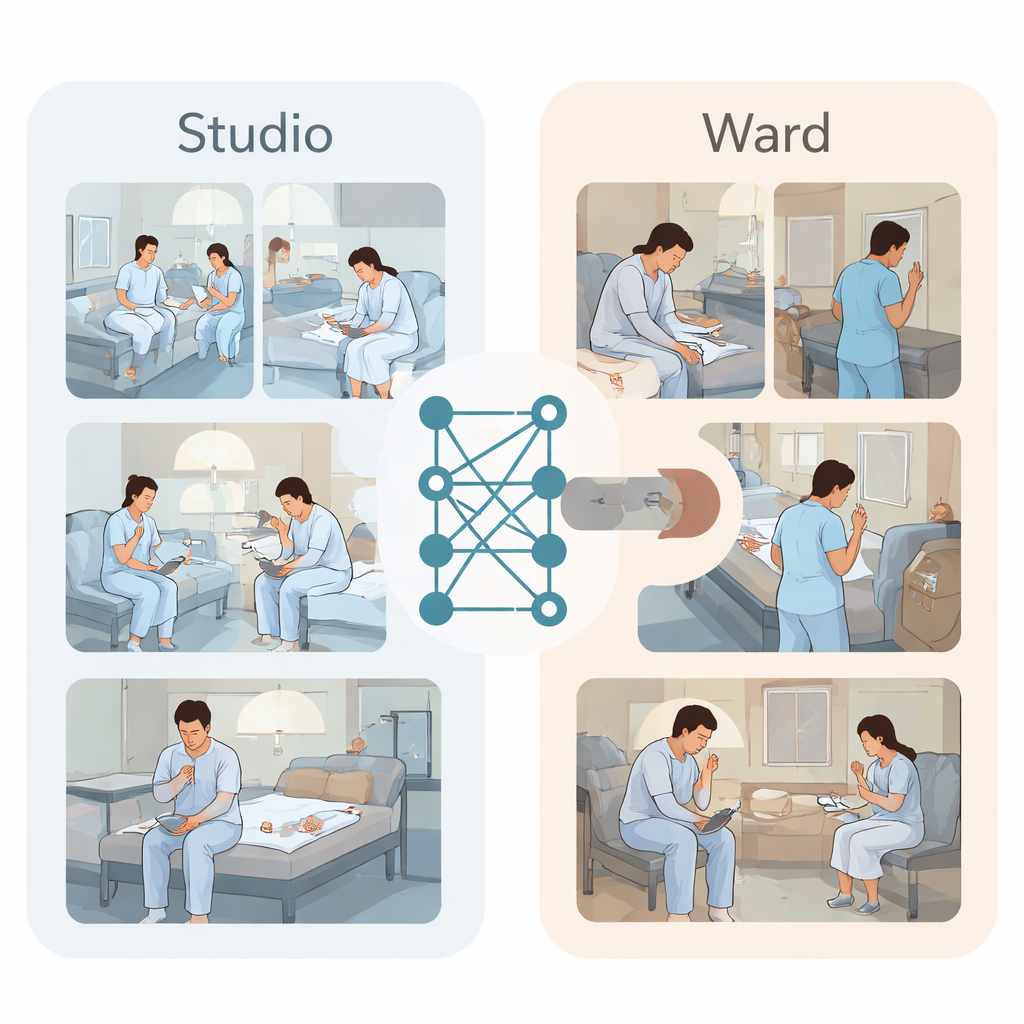
De beste video-AI van vandaag op de proef stellen
Met deze datasets testte het team toonaangevende action-recognition-systemen — computerprogramma’s die ontworpen zijn om te begrijpen wat mensen in een video doen. Sommige waren gebaseerd op oudere convolutionele netwerken, die korte reeksen frames analyseren, terwijl nieuwere transformer-gebaseerde modellen aandachtmechanismen gebruiken om patronen over ruimte en tijd te verbinden. Alle modellen werden alleen op de studiobeelden getraind om te beslissen of een clip zelfbeschadiging of normaal gedrag toonde. Belangrijk is dat de onderzoekers een strikt testschema gebruikten: in elke ronde werden alle clips van één acteur volledig apart gehouden als nieuwe testdata, zodat de algoritmen niet simpelweg individuele personen konden uit het hoofd leren.
Wanneer schone labvideo’s de rommelige werkelijkheid ontmoeten
Op het ordelijke studiomateriaal stak het meest geavanceerde transformer-model, VideoMAEv2, met kop en schouders boven de rest uit. Het wist gemiste en onterechte alarmen beter in balans te houden dan de anderen en bereikte een F1-score (een gecombineerde maat voor precisie en recall) van ongeveer 0,65, terwijl eenvoudigere methoden rond willekeurige voorspelling schommelden. Visuele verklaringen toonden dat dit model zich sterk concentreerde op waar een voorwerp de huid raakte, in plaats van afgeleid te worden door achtergrondbeweging. Maar zodra dezelfde getrainde systemen zonder verdere bijscholing op de echte afdelingsopnames werden losgelaten, daalde hun prestatie. VideoMAEv2 deed het nog steeds beter dan toeval, met een F1-score rond 0,61, maar had vooral moeite met subtiele gedragingen zoals pulken en krabben die nooit in de gesimuleerde data voorkwamen, en met patiënten die klein waren, ver van de camera of gedeeltelijk verborgen.
Wat dit betekent voor patiëntveiligheid
Gezamenlijk tonen de resultaten een duidelijke kloof tussen simulatie en realiteit. AI-systemen die veelbelovend lijken op zorgvuldig geregisseerde video’s kunnen falen wanneer ze worden geconfronteerd met de rommel, vreemde hoeken en gevarieerde gedragingen van het echte ziekenhuisleven. De belangrijkste bijdrage van de studie is geen af product voor veiligheid, maar een beginpunt: een openbare, goed-geannoteerde studiodataset, een zorgvuldig verzamelde real-world testset en een transparante benchmark die laat zien waar huidige methoden tekortschieten. Voor niet-specialisten is de boodschap helder: AI kan al helpen verdachte momenten in afdelingsvideo’s te markeren, maar het kan nog niet worden vertrouwd als een zelfstandige beschermer. Het dichten van deze kloof vereist rijkere, meer diverse trainingsdata en slimere modellen, ontwikkeld met privacy, eerlijkheid en klinisch oordeel voorop.
Bronvermelding: Lee, K., Lee, D., Ham, HS. et al. Benchmarking action recognition models for self-harm detection in studio and real-world datasets. Sci Rep 16, 6850 (2026). https://doi.org/10.1038/s41598-026-36999-w
Trefwoorden: detectie van zelfbeschadiging, psychiatrische afdelingen, video-actieherkenning, kunstmatige intelligentie in de gezondheidszorg, patiëntveiligheid