Clear Sky Science · nl
Machine learning-modellen voor de voorspelling van ruw eiwit in Tamani-weiden
Waarom slimme weiden belangrijk zijn voor je bord
Rundvlees en melk beginnen bij gras. Wereldwijd voeden miljarden hectares weidegrond runderen, schapen en andere grazende dieren. Om goed te groeien en gezond te blijven, moet dat gras genoeg eiwit bevatten, een belangrijk bouwsteen van spieren, melk en vitale organen. Het meten van eiwit in gras betekent meestal monsters nemen en naar een laboratorium sturen—traag en kostbaar werk dat de meeste boeren niet vaak kunnen doen. Deze studie onderzoekt hoe eenvoudige veldmetingen, gecombineerd met moderne computertechnieken, eiwit snel en goedkoop kunnen schatten, zodat boeren hun begrazing en bemesting kunnen verfijnen terwijl ze minder middelen gebruiken.
Een nadere blik op een tropische werkpaardgras
De onderzoekers concentreerden zich op Tamani-gras, een productief tropisch gras dat veel wordt gebruikt in Brazilië voor intensief weiden. Gedurende 18 maanden volgden ze een perceel van 0,96 hectare dat was verdeeld in kleine percelen en blootgesteld aan twee niveaus van stikstofbemesting en twee begrazingsstrategieën op basis van de hoeveelheid licht die de planten onderschepten. Ze registreerden makkelijk verkrijgbare informatie: jaargetijden, temperatuur, neerslag, zonlicht, de rusttijd die elk perceel tussen begrazingen had, en de grassprietlengte voor en na het grazen. Tegelijk namen ze een beperkt aantal bladmmonsters en gebruikten een gespecialiseerde optische methode om ruw eiwit te meten, waarmee ze een kleine maar gedetailleerde dataset opbouwden die dag-tot-dag beheer koppelde aan graskwaliteit. 
Computers leren het weiland lezen
In plaats van te vertrouwen op satellietbeelden of drones, die speciale apparatuur en rekenkracht vereisen, gebruikte het team alleen "tabelgegevens"—het soort gegevens dat je in een spreadsheet ziet. Ze testten vijf verschillende machine-learningbenaderingen, computer methoden die patronen uit voorbeelden leren: een standaard lineair model, een eenvoudige beslisboom, een neuraal-netwerkachtig model en twee populaire op bomen gebaseerde methoden die veel eenvoudige modellen combineren tot een sterker geheel. Ze trainden deze modellen op 80 procent van de metingen en hielden de resterende 20 procent voor testen. Het doel was simpel maar praktisch: gegeven informatie die een boer gemakkelijk kan noteren—bemestingsniveau, rustperiode, grassprietlengte en basisweer—kon een computer voorspellen hoeveel eiwit er in de bladeren zit?
Hoe beheerkeuzes het eiwitgehalte vormen
De modellen toonden aan dat de manier waarop weiden worden beheerd belangrijker is voor het eiwitgehalte dan de weervoorwaarden die in deze studie zijn vastgelegd. Van alle factoren kwam de tijd tussen begrazingen als belangrijkste naar voren: langere rustperiodes leidden tot oudere, vezeligere planten met minder eiwit, terwijl kortere tussenpozen hielpen jonger, bladrijk gras te behouden dat rijker is aan eiwit. Stikstofbemesting speelde ook een grote rol, omdat stikstof een kernbestanddeel is van plantaardige eiwitten en chlorofyl. De grassprietlengte voor en na het grazen stond op de volgende plaats in belang en koppelde het eiwitgehalte aan hoe nauwgezet dieren mogen grazen. Neerslag, temperatuur, zonlicht en seizoensaanduidingen hadden nog steeds enig effect, maar ze waren minder bepalend dan deze alledaagse beheersbeslissingen. 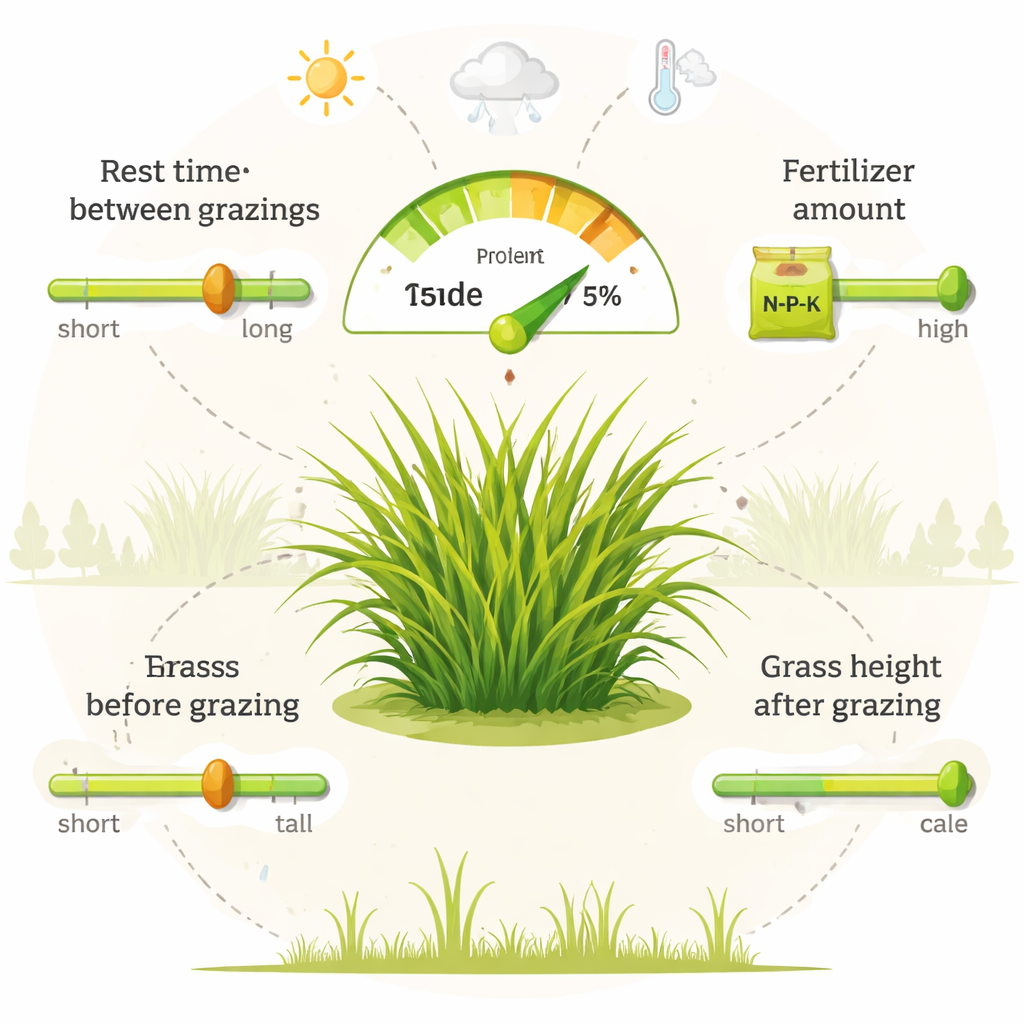
Hoe accuraat waren de computervoorspellingen?
De best presterende methoden waren twee geavanceerde op bomen gebaseerde modellen. Eén genaamd Random Forest en een andere bekend als XGBoost leverden vergelijkbare correlaties tussen voorspelde en waargenomen eiwitwaarden, wat betekent dat hun schattingen de neiging hadden samen met de werkelijke waarden te stijgen en te dalen. XGBoost presteerde iets beter in het algemeen, verklaarde iets meer dan de helft van de variatie in eiwitgehalte en hield de gemiddelde voorspellingsfouten rond anderhalf procentpunt. Hoewel dit niet perfect is, is het nauwkeurig genoeg om nuttig te zijn voor veel beheersbeslissingen, vooral gezien het feit dat het alleen steunt op informatie die de meeste bedrijven al met eenvoudige hulpmiddelen en een schrift of eenvoudige app kunnen vastleggen.
Wat dit betekent voor boeren en voedselconsumenten
Voor een niet-specialistische lezer is de boodschap helder: door goed te letten op hoe lang weiden rusten, hoe hoog het gras is wanneer dieren het perceel betreden en verlaten, en hoeveel stikstofbemesting wordt toegepast, kunnen boeren het eiwitgehalte van hun gras in de gewenste richting sturen. Deze studie toont aan dat betaalbare, gemakkelijk te verzamelen metingen, gecombineerd met slimme algoritmen, snelle schattingen van gras-eiwit kunnen geven zonder voortdurend laboratoriumwerk of dure sensortechniek. Als vervolgonderzoek met grotere en meer gevarieerde datasets deze resultaten bevestigt, zouden dergelijke hulpmiddelen boeren kunnen helpen meer vlees en melk te produceren met minder input, lagere kosten en betere milieu-uitkomsten—voordelen die uiteindelijk bij consumenten terechtkomen via efficiëntere en duurzamere veehouderij.
Bronvermelding: Oliveira de Aquino Monteiro, G., dos Santos Difante, G., Baptaglin Montagner, D. et al. Machine learning models for crude protein prediction in Tamani grass pastures. Sci Rep 16, 5805 (2026). https://doi.org/10.1038/s41598-026-36949-6
Trefwoorden: weidebeheer, voederkwaliteit, machine learning, ruw eiwit, precisie veehouderij