Clear Sky Science · nl
MQADet: een plug-and-play-paradigma voor het verbeteren van open-vocabulary objectdetectie via multimodale vraag‑en‑antwoord
Waarom slimmer objectvinden ertoe doet
Telefoons, auto’s, huishoudrobots en zoekmachines vertrouwen steeds meer op software die objecten in beelden kan vinden: een kind dat de straat oversteekt, je verloren sleutels op een tafel of een specifiek product op een schap. Maar de meeste systemen van nu begrijpen alleen korte, eenvoudige labels zoals “hond” of “auto.” Als je vraagt naar “de kleine hond met een rode halsband liggend achter het kussen van de bank,” raken ze vaak in de war. Dit artikel introduceert MQADet, een manier om bestaande objectvindsystemen te upgraden zodat ze zulke rijke, gedetailleerde beschrijvingen kunnen begrijpen zonder de onderliggende modellen opnieuw te trainen.
Van vaste lijsten naar open-eindig begrip
Traditionele objectdetectors worden getraind op vaste lijsten met categorieën, zoals de 80 alledaagse items in het veelgebruikte COCO-dataset. Ze werken goed zolang het object tot een van die categorieën behoort en de vraag kort en duidelijk is. De echte wereld is echter rommelig. Mensen verwijzen naar dingen met lange zinnen, subtiele eigenschappen en relaties zoals “de man in het gele hesje die achter de vrachtwagen staat.” Nieuwere “open-vocabulary” detectors proberen los te breken van vaste lijsten door beelden aan tekst te koppelen, maar ze worstelen nog steeds met complexe formuleringen en met zeldzame, langst-tailende categorieën die weinig in trainingsdata voorkomen. Ze vergen ook veel rekenkracht en data om te verbeteren.
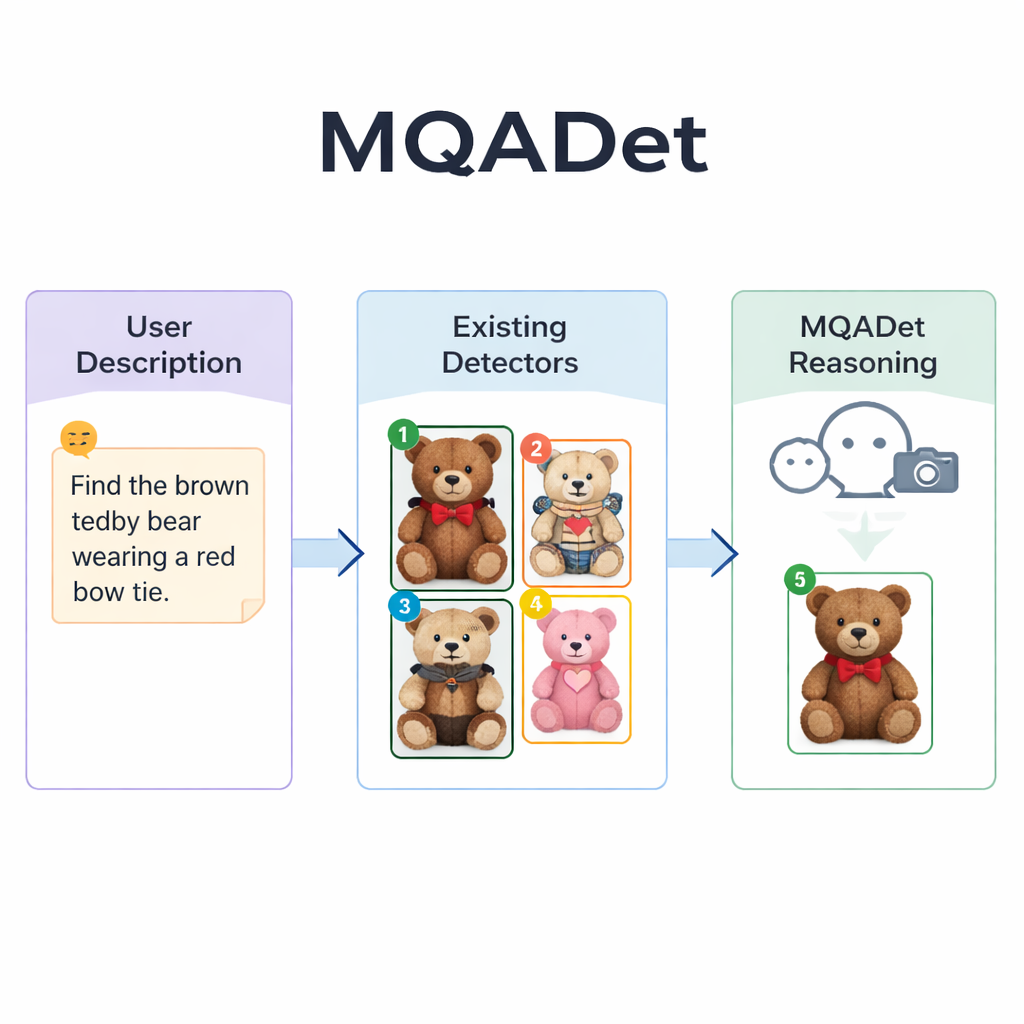
De zoekfunctie laten sturen door taalmodellen
MQADet pakt deze problemen aan door een multimodaal groot taalmodel — een systeem dat beelden kan bekijken en tekst kan lezen — bovenop bestaande detectors te plaatsen in een driefasig vraag‑en‑antwoordproces. Eerst leest een fase genaamd Text‑Aware Subject Extraction de volledige zin van de gebruiker en haalt de werkelijke doelobjecten eruit, zoals “paraplu” en “voetganger” uit een lange beschrijving. Dit weerspiegelt hoe een mens snel de belangrijkste zelfstandige naamwoorden in een zin zou identificeren voordat hij een scène scant. Cruciaal is dat deze fase gebruikmaakt van het sterke taalbegrip van het model, waardoor het met lange, beschrijvende zinnen om kan gaan in plaats van slechts met losse woorden.
Kandidaten in het beeld markeren
In de tweede fase, Text‑Guided Multimodal Object Positioning, geeft MQADet die geëxtraheerde onderwerpen plus het beeld aan een bestaande open‑vocabulary detector — zoals Grounding DINO, YOLO‑World of OmDet‑Turbo. De detector stelt meerdere mogelijke locaties in het beeld voor waar elk onderwerp zich zou kunnen bevinden, tekent rond elk kandidaatobject een vak en plaatst een eenvoudig nummer in het vak. Het resultaat is een “gemarkeerd beeld” dat alle plausibele opties toont. Belangrijk is dat MQADet deze detectors niet opnieuw traint; het gebruikt ze gewoon zoals ze zijn. Dit maakt de aanpak plug‑and‑play: wanneer er een betere detector verschijnt, kan die zonder extra data of afstemming in de pijplijn worden ingezet.

Redeneren naar de beste match
De derde fase, MLLMs‑Driven Optimal Object Selection, maakt van de uiteindelijke keuze een meerkeuzevraag voor het taalmodel: gegeven de oorspronkelijke beschrijving en het gemarkeerde beeld met genummerde vakken, welk nummer komt het beste overeen met de tekst? Omdat het model zowel de gedetailleerde formulering als de visuele opmaak ziet, kan het fijnmazige aanwijzingen wegen — patronen, kleuren, ruimtelijke relaties zoals “links” en interacties tussen objecten. De auteurs tonen aan dat het weglaten van deze redeneringsfase de nauwkeurigheid sterk vermindert, wat het belang ervan benadrukt. Met dit driefasige ontwerp verbeterde MQADet de nauwkeurigheid over vier veeleisende benchmarks met lange, natuurlijke zinnen, en verhoogde het vaak de prestaties van bestaande detectors met 10–40 procentpunten zonder hun interne gewichten te veranderen.
Wat dit betekent voor alledaagse technologie
Voor niet‑specialisten is de kernboodschap dat we detectoren niet meer helemaal hoeven opnieuw op te bouwen om ze slimmer te maken. MQADet fungeert als een intelligente assistent bovenop huidige systemen, helpt hen rijke menselijke beschrijvingen te interpreteren en het juiste object in complexe scènes te kiezen. Dit kan visuele zoekfuncties, hulpmiddelen voor assistentie en autonome machines betrouwbaarder maken bij het omgaan met de manier waarop mensen natuurlijk spreken — vol detail, nuance en context — en zo de weg vrijmaken voor meer intuïtieve, taalgesteunde interactie met de visuele wereld.
Bronvermelding: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
Trefwoorden: open-vocabulary objectdetectie, multimodale grote taalmodellen, visuele vraagbeantwoording, computervisie, beeldbegrip