Clear Sky Science · nl
Toepassing van machine learning bij de voorspelling van behandeluitkomsten bij dikkedarmkanker
Waarom het voorspellen van uitkomsten bij dikkedarmkanker ertoe doet
Dikkedarmkanker is een van de meest voorkomende vormen van kanker wereldwijd, en veel patiënten en families willen één eenvoudige, dringende vraag beantwoord zien: “Wat zijn mijn kansen, en wat kan gedaan worden om ze te verbeteren?” Deze studie uit Iran onderzoekt hoe moderne computertechnieken, bekend als machine learning, gedetailleerde medische dossiers kunnen doorzoeken om beter te voorspellen welke patiënten na een operatie een hoger risico lopen. Door deze voorspellingen te verscherpen, kunnen artsen behandeling en nazorg nauwkeuriger afstemmen, waardoor kwetsbare patiënten een betere kans krijgen op langetermijnoverleving.
Het omzetten van ziekenhuisgegevens in bruikbare patronen
De onderzoekers gebruikten tien jaar aan gegevens van 764 mensen die een operatie voor dikkedarmkanker ondergingen in een groot centrum in Shiraz, Iran. Van elke patiënt verzamelden ze 44 gegevenspunten, waaronder leeftijd, bloedonderzoeken, tumorgrootte, kankerstadium, symptomen en details over de operatie en behandelingen zoals chemotherapie. Deze gegevens werden zorgvuldig opgeschoond en gecontroleerd: onmogelijke laboratoriumwaarden werden gecorrigeerd, patiënten die niet konden worden gevolgd werden verwijderd, en ontbrekende antwoorden werden aangevuld met redelijke schattingen. Het team splitste de data vervolgens zo dat het grootste deel de computermodellen trainde, terwijl een apart deel werd achtergehouden om te testen hoe goed die modellen konden voorspellen wie bij follow-up in leven zou zijn of overleden.
Hoe slimme algoritmen van patiënten leren
In plaats van alleen te vertrouwen op traditionele statistiek vergeleek de studie meerdere moderne computerbenaderingen naast elkaar. Hiertoe behoorden verschillende “forest”- en “boosting”-methoden, die veel eenvoudige beslisregels combineren, evenals neurale netwerken, die losjes nabootsen hoe hersencellen met elkaar verbinden. Het doel voor elke methode was hetzelfde: gebruikmaken van de patiëntinformatie om te raden of elke persoon zou overleven, en die voorspellingen vergelijken met wat er daadwerkelijk gebeurde. De modellen werden beoordeeld op hoe vaak ze in totaal gelijk hadden, hoe goed ze patiënten die overleden opspoorden, en hoe goed ze valse alarmen vermeden voor degenen die in leven bleven. De best presterende methoden bereikten ongeveer 80% totale nauwkeurigheid, een sterk resultaat gezien de complexiteit van kankeruitkomsten.
Welke modellen en factoren het meest van belang waren
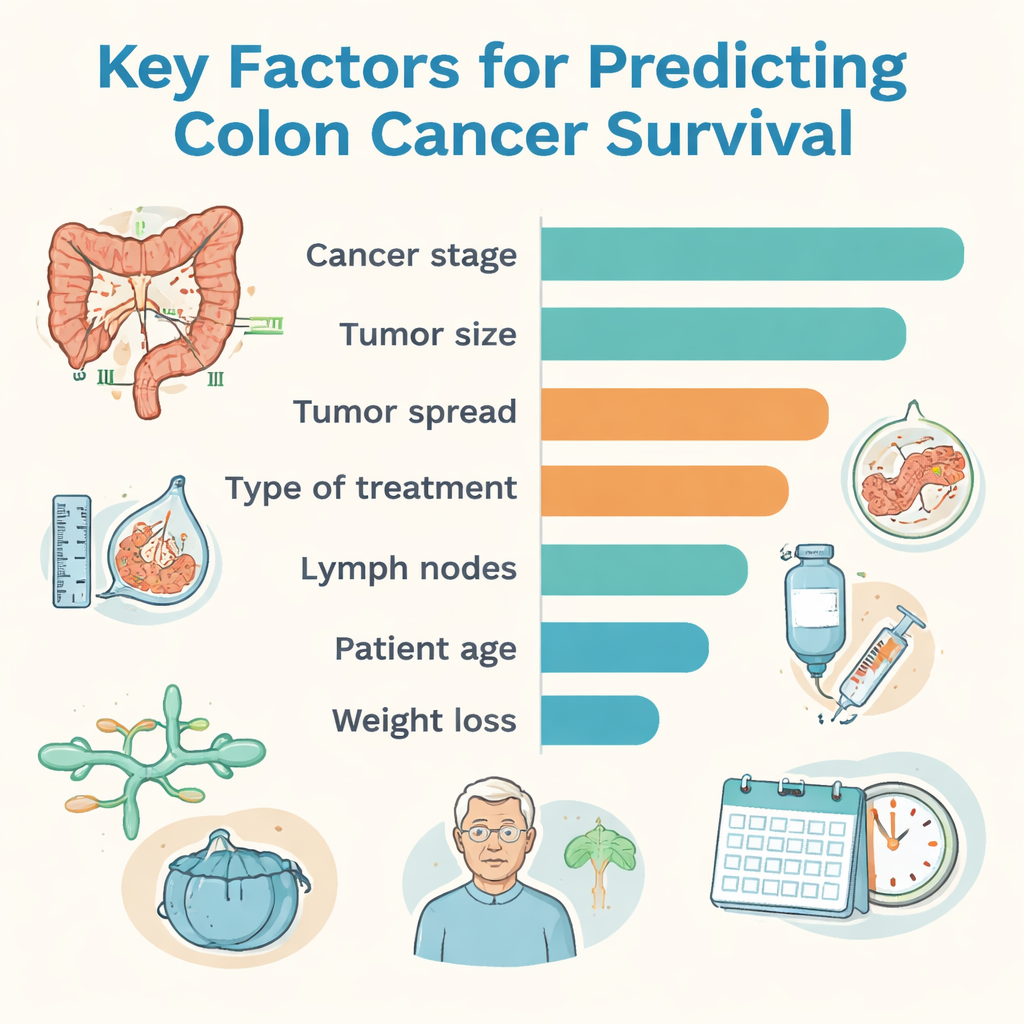
Van alle benaderingen behaalde een methode genaamd CatBoost de hoogste totale nauwkeurigheid, terwijl een random forest-model de beste balans liet zien tussen het correct signaleren van hoogrisicopatiënten en het niet te veel aangeven van risico bij patiënten die het goed deden. Om de resultaten begrijpelijker te maken voor artsen gebruikte het team een uitlegartool die rangschikt welke informatie het meest invloed had op de beslissingen van de computer. Het kankerstadium — een samenvatting van hoe groot de tumor is, of deze lymfeklieren heeft bereikt en of deze is uitgezaaid — was de sterkste enkele factor. Tumorgrootte, hoe diep de tumor in de darmwand ingroeide, de aanwezigheid van uitzaaiingen naar andere organen, type behandeling, tumorgraad (hoe abnormaal de cellen leken), betrokkenheid van lymfe- en bloedvaten, leeftijd van de patiënt en gewichtsverlies speelden ook belangrijke rollen bij het vormen van overlevingsvoorspellingen.
Van cijfers naar beslissingen aan het bed
Deze bevindingen suggereren dat een zorgvuldig getraind computermodel, gevoed met routinematige klinische informatie, artsen kan helpen patiënten te identificeren die stilletjes een hoog risico lopen na een operatie voor dikkedarmkanker. In de dagelijkse praktijk zou zo’n hulpmiddel in een elektronisch patiëntendossier kunnen zitten en direct details over de tumor en de algemene gezondheid van een patiënt combineren tot een eenvoudige risicoschatting. Dat getal vervangt de oordeelsvorming van een arts niet, maar kan keuzes sturen zoals hoe vaak een patiënt gecontroleerd moet worden, of aanvullende behandelingen de bijwerkingen waard zijn, of wanneer een second opinion wenselijk is. Omdat de belangrijkste factoren die door de computer werden geïdentificeerd overeenkomen met wat kankerspecialisten al als cruciaal beschouwen, is het systeem makkelijker te vertrouwen en aan patiënten uit te leggen.
Wat dit betekent voor patiënten en de toekomst
Voor patiënten en families is de kernboodschap dat computers nu gewone medische gegevens kunnen gebruiken om meer gepersonaliseerde zorg bij dikkedarmkanker te ondersteunen. Hoewel de studie in één centrum in Iran is uitgevoerd en nog getest moet worden in andere ziekenhuizen en met rijkere gegevens, zoals genetische en beeldvormingsinformatie, laat het zien dat machine learning kan aangeven wie extra aandacht nodig heeft en waarom. Naarmate er meer gegevens worden toegevoegd en modellen worden verfijnd, zouden deze tools artsen wereldwijd kunnen helpen behandelingen te leveren die niet alleen evidence-based zijn, maar ook fijn afgestemd op ieders specifieke kanker en omstandigheden.
Bronvermelding: Ghasemi, H., Hosseini, S.V., Rezaianzadeh, A. et al. Machine learning application in colon cancer treatment outcome prediction. Sci Rep 16, 6159 (2026). https://doi.org/10.1038/s41598-026-36917-0
Trefwoorden: dikkedarmkanker, machine learning, behandeluitkomsten, risicovoorspelling, klinische gegevens