Clear Sky Science · nl
De kloof dichten in prestaties: systematische optimalisatie van lokale LLM’s voor het verwijderen van medische PHI in het Japans
Waarom dit belangrijk is voor patiëntprivacy
Ziekenhuizen beschikken over omvangrijke verzamelingen medische notities die zorg en onderzoek kunnen verbeteren, maar deze dossiers bevatten veel gevoelige details zoals namen, adressen en data. Krachtige cloudgebaseerde AI-systemen zijn zeer goed in het verbergen van zulke informatie, maar veel ziekenhuizen mogen ruwe patiëntgegevens niet naar externe servers sturen. Deze studie laat zien dat met zorgvuldige afstemming kleinere AI‑modellen die volledig binnen het ziekenhuis draaien verrassend dicht bij de prestaties van toonaangevende cloudsystemen kunnen komen — en zo een manier bieden om AI te gebruiken terwijl patiëntgegevens veilig ter plaatse blijven.
Het dilemma: privacy versus vooruitgang
Moderne grote taalmodellen kunnen beschermd gezondheidsinformatie (PHI) in medische tekst betrouwbaar opsporen en verwijderen, vaak met een nauwkeurigheid van meer dan 90 procent. Het versturen van onbewerkte patiëntnotities naar clouddiensten roept echter juridische en ethische vragen op onder regelgeving zoals HIPAA, GDPR en Japan’s APPI. Veel instellingen staan op volledige “data‑soevereiniteit”, wat betekent dat informatie hun eigen systemen nooit verlaat. Tot nu toe misten lokale modellen die op interne hardware draaien doorgaans veel meer identificatoren, waardoor ziekenhuizen een afweging moesten maken: sterke analyse in de cloud of strengere privacy met minder krachtige tools. De auteurs wilden nagaan of deze kloof voldoende kon worden verkleind voor gebruik in de klinische praktijk.
Een gefaseerd plan voor slimmer lokale AI
Het team ontwierp een stappenplan met vijf fasen om de prestaties van lokale taalmodellen bij het verwijderen van PHI uit Japanse radiologierapporten stapsgewijs te verbeteren. Ze begonnen met 14 verschillende modellen van uiteenlopende grootte, allemaal draaiend op een geïsoleerde, internetvrije computer die ziekenhuisbeveiliging moest nabootsen. Met 160 zorgvuldig samengestelde synthetische rapporten — realistisch maar volledig fictief — maten ze hoe goed elk model acht typen identificatoren vond en afsplitste, van namen en ID‑nummers tot data en afdelingen. Na een eerste basistest creëerden ze meer behulpzame algemene prompts, waarna ze instructies afstemden op de eigenaardigheden van elk model, een geautomatiseerde “zelfcontrole en correctie”-lus toevoegden en tenslotte de beste kandidaten testten op een gereserveerde set rapporten. 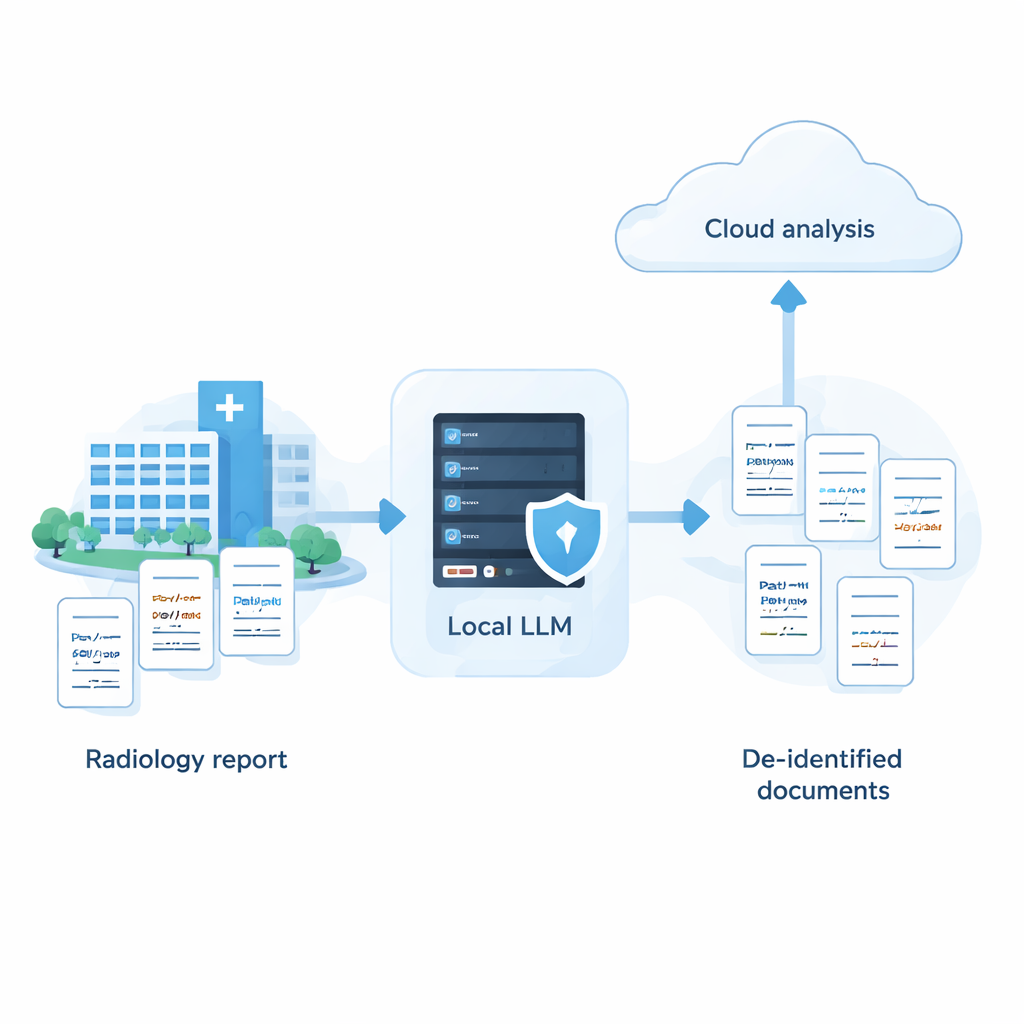
Naderen van cloud‑niveau prestaties
Door dit gefaseerde proces ontdekten de onderzoekers dat ruwe modelgrootte niet de doorslaggevende factor was; sommige zeer grote systemen presteerden nog steeds slecht. In plaats daarvan waren de meest veelbelovende modellen degenen die goed reageerden op zorgvuldige instructieontwerpen en foutenanalyse. Eén middelgroot systeem, Mistral‑Small‑3.2, werd de duidelijke winnaar na aangepaste prompts en een zelfverfijningsstap waarbij het model zijn eigen uitvoer bekeek en selectief corrigeerde. Bij de laatste 60 testgevallen scoorde deze geoptimaliseerde lokale opstelling 91,54 van de 100 punten — ongeveer 97,8 procent van de 93,56 punten van het toonaangevende cloudmodel — en hield ze zich daarbij perfect aan opmaakregels. In praktische termen werd het resterende tekort als klinisch onbeduidend beoordeeld. De belangrijkste concessie was snelheid: lokale verwerking kostte ongeveer 25 seconden per typisch rapport, vergeleken met minder dan 2 seconden in de cloud, maar dit werd als acceptabel beschouwd voor routinematig, niet‑spoedeisend batchwerk. 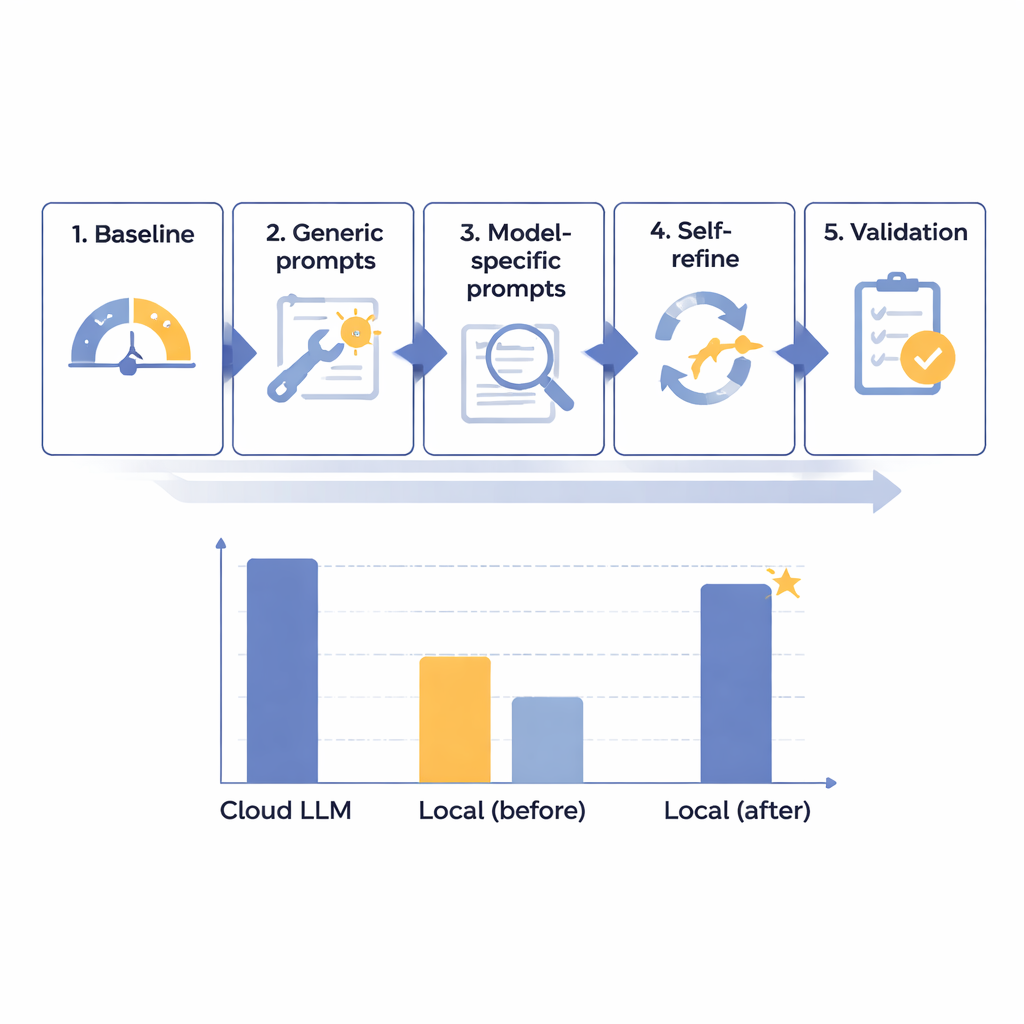
Een verrassende drempel voor zelfcorrectie
Een van de meest intrigerende bevindingen was een soort kantelpunt rond 87–88 punten op de 100‑puntsschaal van de auteurs. Modellen die bij de baseline onder dit niveau scoorden — zoals Mistral‑Small‑3.2 — profiteerden sterk van de zelfverfijningslus en wonnen bijna zeven punten doordat ze een klein deel van hun eigen fouten corrigeerden. Modellen die al boven deze drempel begonnen, lieten vrijwel geen verbetering zien en verspeelden soms moeite door correcte antwoorden te “verbeteren”. Dit suggereert dat geavanceerde optimalisatietools gereserveerd moeten worden voor modellen die goed maar niet uitmuntend zijn, zodat ziekenhuizen rekenkracht en personeel kunnen richten waar dit het meest oplevert. De auteurs waarschuwen dat deze drempel is gebaseerd op slechts twee modellen en bevestiging behoeft, maar dat het een vroege vuistregel biedt voor uitrolplanning.
Wat dit betekent voor ziekenhuizen en patiënten
De studie betoogt dat ziekenhuizen niet hoeven te kiezen tussen sterke privacy en krachtige AI. Met een systematische aanpak — het screenen van veel modellen, het afstemmen van prompts op hun sterke en zwakke punten en het toevoegen van een intelligente zelfreviewstap — is het mogelijk dat een volledig lokaal systeem de nauwkeurigheid van toonaangevende clouddiensten benadert bij het verwijderen van gevoelige informatie uit medische tekst. In de praktijk opent dit de deur naar een hybride strategie: PHI wordt veilig verwijderd op ziekenhuis‑eigendom machines en alleen geanonimiseerde rapporten, met namen en andere identificatoren verwijderd, worden naar de cloud gestuurd voor meer geavanceerde analyse. Hoewel het werk tot nu toe gebaseerd is op synthetische Japanse radiologierapporten en nog getest moet worden op echte data en andere talen, biedt het een uitvoerbare routekaart voor instellingen die AI willen benutten zonder het vertrouwen en de privacy van patiënten te schaden.
Bronvermelding: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
Trefwoorden: medische de-identificatie, patiëntprivacy, lokale taalmodellen, AI in de gezondheidszorg, radiologierapporten