Clear Sky Science · nl
Objectdetectie op low-compute edge-SoC's: een reproduceerbare benchmark en implementatierichtlijnen
Waarom kleine chips belangrijk zijn voor slimme camera’s
Veel van de “slimme” apparaten om ons heen — beveiligingscamera’s, drones, sensors in fabrieken en deurbelcamera’s — moeten in realtime mensen en objecten herkennen, maar vertrouwen op zeer kleine, energiezuinige chips in plaats van op datacenterhardware met hoog vermogen. Bedrijven kiezen vaak bekende YOLO-objectdetectiemodellen, maar de geadverteerde snelheid van deze chips zegt weinig over hoe goed alles in de praktijk werkt. Dit artikel neemt een strikte experimentele blik op hoe negen moderne YOLO-varianten presteren op drie veelgebruikte, goedkope Rockchip-processors en laat zien wat echt bepaalt hoe snel, energie-efficiënt en betrouwbaar intelligentie naar de edge kan worden gebracht.
Drie alledaagse chips onder de loep
De auteurs richten zich op drie commerciële system-on-chips (SoC’s) die stilletjes veel embedded-vision-systemen aandrijven: de compacte RV1106, de middensegment RK3568 en de krachtigere RK3588. Elk combineert gangbare processorkernen met een speciale neural processing unit (NPU) en extern geheugen. Op deze platforms zetten ze negen YOLO-modellen in — drie generaties (YOLOv5, YOLOv8, YOLO11) in drie groottes (Nano, Small, Medium) — die allemaal op dezelfde benchmarkdataset zijn getraind. Ze zetten de modellen zorgvuldig om naar een gemeenschappelijk formaat, kwantiseren ze naar 8-bits rekenwaarden, compileren met Rockchip’s tools en voeren vervolgens honderden getimde tests uit om stabiele metingen van vertraging, vermogen en energie per verwerkte frame te verkrijgen.
Snelheid is niet wat het specificatieblad suggereert
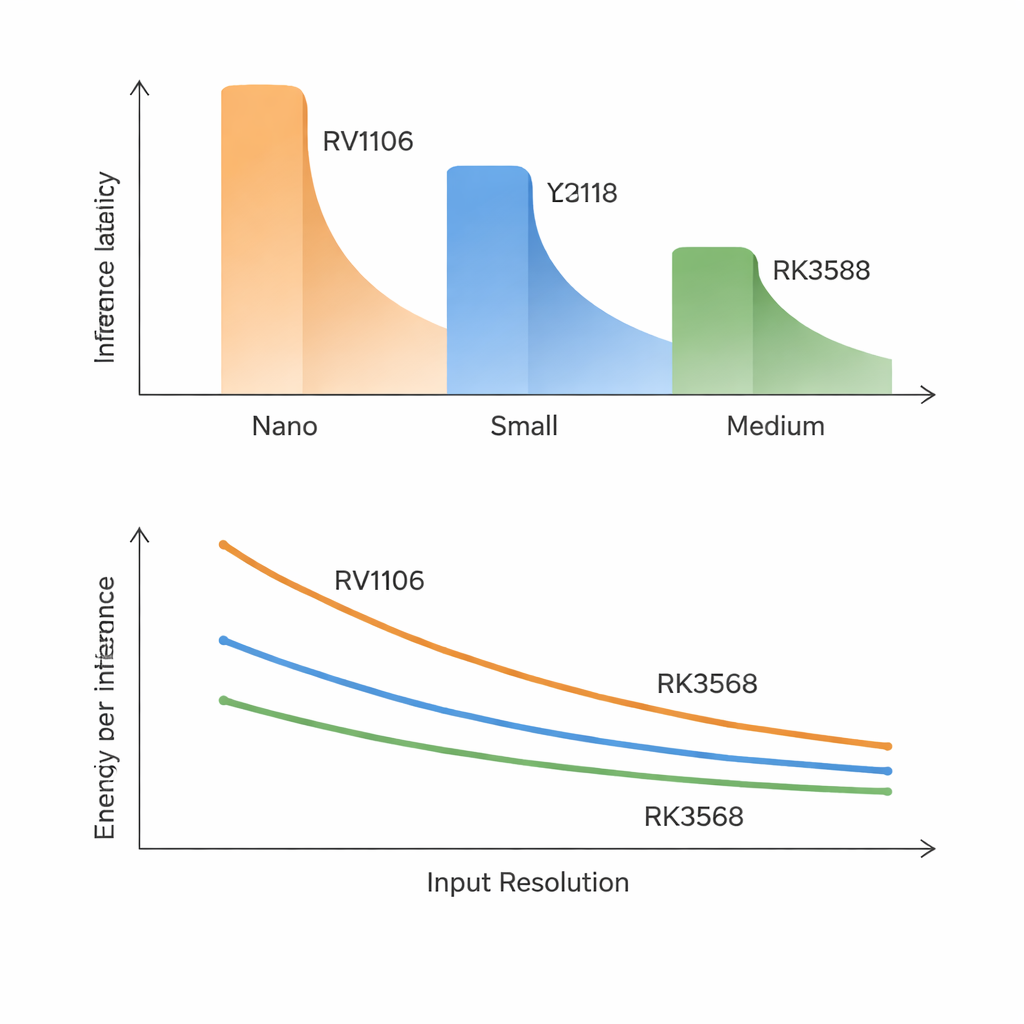
Een van de duidelijkste lessen is dat traditionele model- en chipcijfers slechte voorspellers zijn van de echte snelheid. Op de langzaamste chip duren zelfs de kleinste modellen ongeveer 70–100 milliseconden per frame en middelgrote modellen zijn veel te traag voor realtime gebruik. De snelste chip kan Nano- en veel Small-modellen in de buurt van de 30 frames per seconde draaien, maar grotere modellen halen nog steeds niet de zeer hoge framerates. Verrassend genoeg correleert vertraging sterker met hoe nauwkeurig een model is dan met het aantal wiskundige operaties of parameters. Nieuwere, nauwkeurigere YOLO-ontwerpen voegen interne blokken toe die gunstig zijn voor nauwkeurigheid maar onhandig voor deze NPU’s om uit te voeren, dus “slimmer” betekent op dit soort hardware vaak “merkbaar trager”.
Wanneer grotere beelden en gedeeld geheugen terugbijten
De studie toont aan dat het vergroten van invoerbeelden de werklast niet gewoon vloeiend doet toenemen. In theorie zou het verdubbelen van breedte en hoogte de kosten vier keer zo groot maken, maar op chips met lage bandbreedte kan dat nog sneller stijgen. Naarmate beelden groter worden, passen tussenresultaten niet meer goed en moeten ze herhaaldelijk naar extern geheugen worden verplaatst. Op de kleine en middensegment-SoC’s verandert dat in een verkeersopstopping: middelgrote modellen worden veel langzamer dan verwacht en intensief achtergrondgebruik van geheugen door andere taken kan vertragingen met 50–270% vergroten. Ter vergelijking, de RK3588 met veel hogere geheugendoorvoer verwerkt resolutietoenames soepel en merkt nauwelijks extra CPU- of geheugenbelasting, wat benadrukt dat geheugensnelheid — niet ruwe rekenkracht — vaak de ware bottleneck is.
Meer kernen en meer vermogen garanderen geen efficiëntie
Rockchip’s snelste chip bevat een NPU met drie kernen, maar het verdelen van YOLO over meerdere kernen levert slechts bescheiden winst op. Voor de meeste modellen verkort het splitsen van werk over twee of drie kernen de vertraging met minder dan 10%, en soms degradeert de prestatie zelfs. De overhead van het coördineren van kernen en het delen van dezelfde geheugenpool heft een groot deel van de theoretische winst op. Vermogensemetingen voegen nog een twist toe: alle drie SoC’s gebruiken tijdens uitvoering slechts een paar watt, maar hun energie per verwerkte frame kan een factor drie verschillen. De duurdere RK3588 verbruikt op elk moment meer vermogen maar rondt het werk zo snel af dat hij vaak de meest energie-efficiënte keuze is, vooral voor middelgrote modellen en hogere resoluties.
Praktische conclusies voor echte apparaten
Voor lezers die nadenken over slimme camera’s, robots of IoT-apparaten is de boodschap duidelijk. Op de kleinste chips zijn alleen de allerkleinste YOLO-modellen bij matige beeldformaten praktisch, en zelfs dan is realtime video vaak lastig. Middensegment-chips kunnen comfortabel kleine modellen en af en toe middelgrote modellen ondersteunen als framerates of batterijduur wat kunnen worden losgelaten. De high-end RK3588 maakt het uiteindelijk realistisch om nauwkeurigere, middelgrote YOLO-varianten te draaien terwijl de energie per frame binnen de perken blijft. In het algemeen pleit het artikel ervoor dat ontwerpers modellen kiezen met de hardware duidelijk in gedachten, scherp letten op geheugendoorvoer en geheugenbesparende technieken verkiezen boven het najagen van steeds grotere netwerken. Wat uiteindelijk telt is niet de geadverteerde tera-operations per seconde, maar of het hele systeem snelle, stabiele en energiebewuste objectdetectie kan leveren onder de rommelige omstandigheden van de echte wereld.
Bronvermelding: Kong, C., Li, F., Yan, X. et al. Object detection on low-compute edge SoCs: a reproducible benchmark and deployment guidelines. Sci Rep 16, 5875 (2026). https://doi.org/10.1038/s41598-026-36862-y
Trefwoorden: edge AI, objectdetectie, embedded vision, YOLO-modellen, laagvermogen SoC