Clear Sky Science · nl
Variantie‑schatting op basis van machine learning bij tweefasige bemonstering met gezondheids‑ en onderwijsdata
Waarom slimmer gemiddelde belangrijk is voor beslissingen in de praktijk
Of artsen nu bloeddruk bestuderen of docenten cijfers bijhouden: ze zijn niet alleen geïnteresseerd in het gemiddelde, maar moeten weten hoe sterk mensen rond dat gemiddelde uiteenlopen. Deze spreiding, variabiliteit genoemd, bepaalt hoeveel proefpersonen nodig zijn voor een studie, hoe omvangrijk een bijspraakkrachtprogramma moet zijn, of hoe zeker we kunnen zijn van beleidskeuzes. Het achterliggende artikel introduceert een nieuwe, statistisch onderbouwde manier om die variabiliteit nauwkeuriger te meten door klassieke bemonsteringsideeën te combineren met moderne machine learning, getest op gezondheids‑ en onderwijsdata.
Spreiding meten als informatie onvolledig is
In een ideale wereld zouden onderzoekers van iedereen in een populatie al veel achtergrondinformatie kennen voordat ze een steekproef doen: leeftijden, studiegewoonten, medische voorgeschiedenis enzovoort. In de praktijk is die informatie vaak onvolledig of kostbaar om te verzamelen. De auteurs werken binnen een ontwerp dat tweefasige bemonstering heet om hiermee om te gaan. In de eerste fase nemen ze een grote, relatief goedkope steekproef en registreren eenvoudige achtergrondgegevens, zoals leeftijd of of iemand internettoegang heeft. In de tweede fase trekken ze een kleinere subs steekproef en meten een duurdere of tijdrovendere uitkomst, zoals systolische bloeddruk of eindexamencijfers. De uitdaging is om die twee informatie‑lagen te gebruiken om te schatten hoe variabel de uitkomst werkelijk is in de gehele populatie.
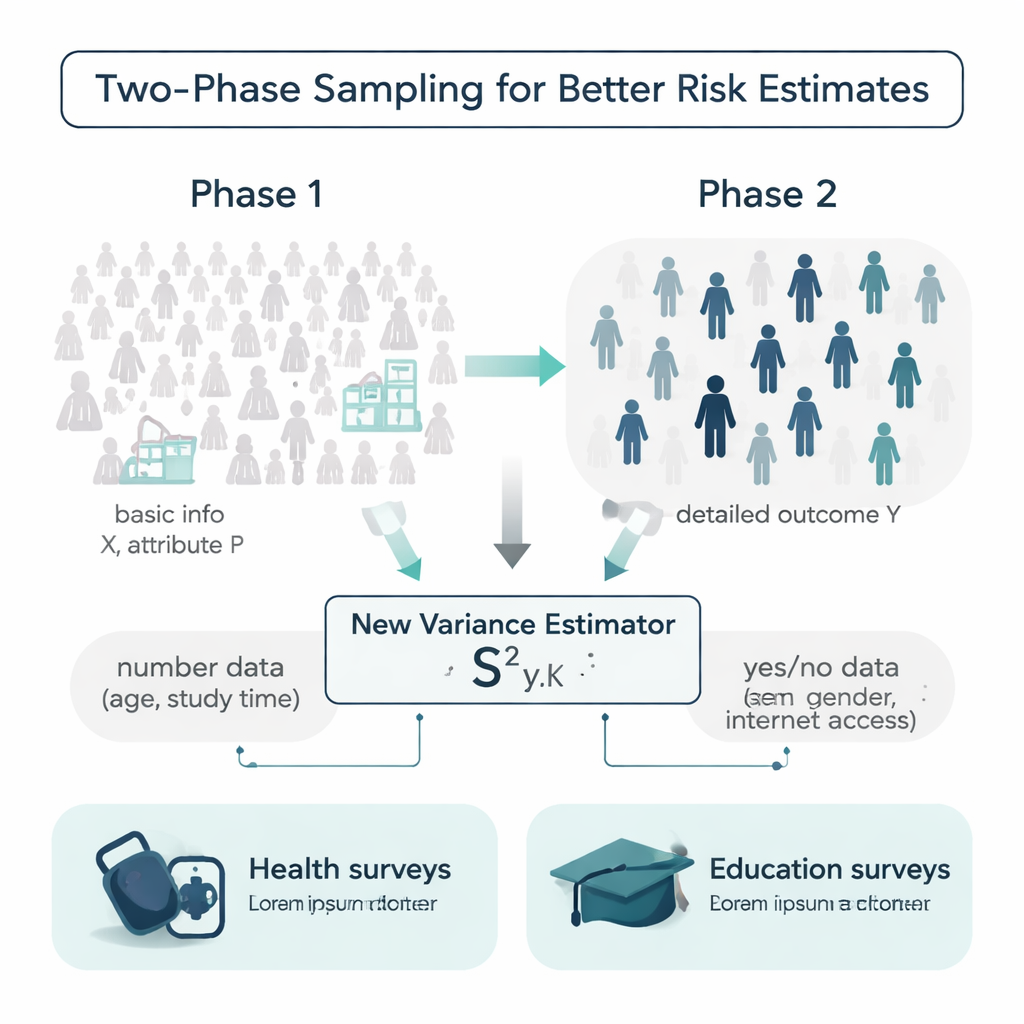
Een nieuwe schatter die zowel numerieke als binaire kenmerken gebruikt
De meeste traditionele middelen voor het meten van variabiliteit vertrouwen alleen op de uitkomst zelf of op één hulpsvariabele, en nemen vaak aan dat de data mooie klokvormige verdelingen volgen. De auteurs stellen een nieuwe variantieschatter voor die twee soorten aanvullende informatie tegelijk benut: een numerieke hulpvariabele (bijv. leeftijd of wekelijkse studietijd) en een ja/nee‑kenmerk (zoals geslacht of internettoegang). Ze tonen wiskundig hoe deze gecombineerde “meng‑”schatter zich gedraagt en leiden formules af voor bias en de gemiddelde gekwadrateerde fout—twee cruciale nauwkeurigheidsmaten. Onder redelijke voorwaarden is de schatter in feite ongebiasd en is de verwachte fout kleiner dan bij veelgebruikte concurrerende formules, wat betekent dat hij scherpere onzekerheidsschattingen geeft met dezelfde hoeveelheid data.
Prestaties testen over diverse datascenario’s
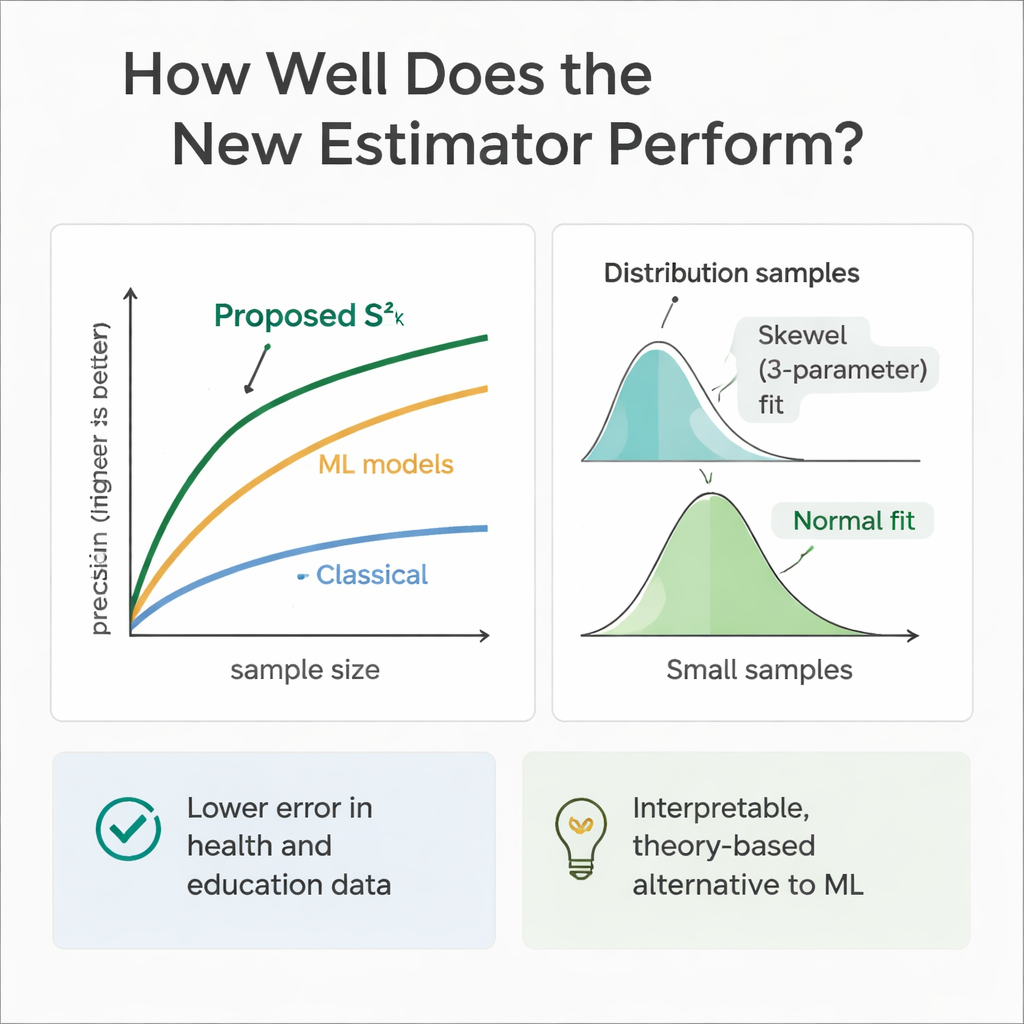
Om te controleren of de theorie in de praktijk klopt, voerde het team uitgebreide computersimulaties uit. Ze simulateerden populaties waarbij de hulpvariabelen en de uitkomst uiteenlopende verdelingen volgden, van symmetrische (Normaal en Uniform) tot scheve (Gamma en Weibull). Met herhaalde bemonstering vergeleken ze de fout van de nieuwe schatter met die van meerdere gevestigde methoden over verschillende steekproefgroottes. In bijna elke setting, en vooral bij grotere steekproeven, toonde de nieuwe aanpak een veel hogere relatieve efficiëntie—vaak een foutreductie van 30 tot 70 procent vergeleken met de klassieke variantieschatter. De auteurs onderzochten ook hoe de steekproefverdeling van de schatter zelf eruitziet en vonden dat een flexibele Weibull‑curve met drie parameters deze het beste beschrijft bij bescheiden steekproeven, terwijl de verdeling naar een normale vorm neigt bij grote steekproefgroottes.
Reële data uit klinieken en klaslokalen
De methode werd toegepast op twee casestudies uit de praktijk. In een gezondheidsdataset was de uitkomst de systolische bloeddruk, met leeftijd als numerieke hulp en geslacht als ja/nee‑kenmerk. In een onderwijsdataset was de uitkomst het eindcijfer van een cursus, de hulpvariabele de wekelijkse studietijd en het kenmerk of de student internettoegang had. In beide gevallen leverde de voorgestelde schatter de kleinste gemiddelde gekwadrateerde fout op van alle geteste statistische concurrenten, waardoor de geschatte variabiliteit rond de gemiddelde bloeddruk en rond de gemiddelde studentprestaties aanzienlijk werd aangescherpt. Deze verbetering vertaalt zich in nauwkeurigere betrouwbaarheidsintervallen en betrouwbaardere vergelijkingen tussen groepen of interventies.
Hoe het zich verhoudt tot machine learning
Aangezien machine learning‑modellen uitblinken in voorspelling, trainden de auteurs ook regressiebomen, random forests en support vector regression op dezelfde gesimuleerde gezondheids‑ en onderwijsscenario’s. Deze modellen, gevoed met dezelfde hulpvariabelen, haalden vaak vergelijkbare of licht betere zuivere voorspellingsnauwkeurigheid dan de nieuwe schatter. Ze werken echter als black boxes: het is moeilijk precies na te gaan hoe ze informatie combineren en ze missen de heldere formules die nodig zijn voor traditionele enquête‑inferenz. De voorgestelde schatter daarentegen is transparant en geworteld in bemonsteringstheorie, wat het makkelijker maakt hem te verantwoorden in regelgevende, klinische of beleidsmatige omgevingen waar uitlegbaarheid even belangrijk is als ruwe prestaties.
Wat dit in de praktijk betekent voor enquêtes
Simpel gezegd laat dit werk zien dat onderzoekers betrouwbaardere maten van spreiding kunnen krijgen zonder de steekproefomvang sterk te vergroten, uitsluitend door gedisciplineerd gebruik te maken van zelfs minimale aanvullende informatie die ze al verzamelen. Door een numerieke factor (zoals leeftijd of studietijd) te combineren met een eenvoudig ja/nee‑kenmerk (zoals geslacht of internettoegang) in een tweefasig bemonsteringsplan, geeft de nieuwe schatter scherpere, stabielere variantieschattingen dan langgebruikte methoden. Terwijl geavanceerde machine learning‑tools nuttige referenties blijven, biedt deze aanpak een praktisch en interpreteerbaar middenweg die gezondheids‑ en onderwijsanalisten helpt sterkere conclusies te trekken uit beperkte data.
Bronvermelding: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
Trefwoorden: enquêtebemonstering, variantie schatting, machine learning, gezondheidsdata, onderwijsonderzoek