Clear Sky Science · nl
Diagnose en indeling van steatotische leverziekte via klinische en laboratoriumgegevens met machine learning
Waarom vetsleverziekte ertoe doet voor gewone mensen
Vetsleverziekte is geruisloos uitgegroeid tot een van de meest voorkomende chronische leveraandoeningen wereldwijd, en treft ongeveer een derde van de volwassenen, ook veel mensen die zich volkomen gezond voelen. Als er teveel vet in de lever ophoopt en dit niet vroeg wordt aangepakt, kan dat langzaam overgaan in littekenvorming, leverfalen en zelfs leverkanker. De beste tests die we nu hebben zijn vaak invasief, zoals een naaldbiopsie, of afhankelijk van dure scanners die veel klinieken niet hebben. Deze studie onderzoekt of eenvoudige, routinematige bloedwaarden en lichaamsmetingen, gecombineerd met moderne computermethoden, een makkelijkere manier kunnen bieden om te ontdekken wie vetslever heeft en hoe ver die gevorderd is.
Een stille ziekte die ernstig kan worden
Steatotische leverziekte, vaak vetslever genoemd, begint wanneer vet zich ophoopt in levercellen. In het begin veroorzaakt deze ophoping (eenvoudige steatose) vaak geen symptomen en wordt ze bij toeval ontdekt. Na verloop van tijd kan het vet echter ontsteking en schade in de lever veroorzaken, wat leidt tot littekenvorming (fibrose), verharding van het weefsel en in ernstige gevallen cirrose en leverfalen. Omdat de vroege stadia stil maar omkeerbaar zijn, is het cruciaal de ziekte te ontdekken voordat ernstige littekens ontstaan. Het probleem is dat veel gebruikte middelen om leverbeschadiging te beoordelen — zoals speciale echografieapparatuur en op bloed gebaseerde scores — vaak te duur, niet breed beschikbaar of minder betrouwbaar zijn bij mensen met obesitas, die juist tot de risicogroepen behoren.
Routinecontroles omvormen tot een test voor levergezondheid
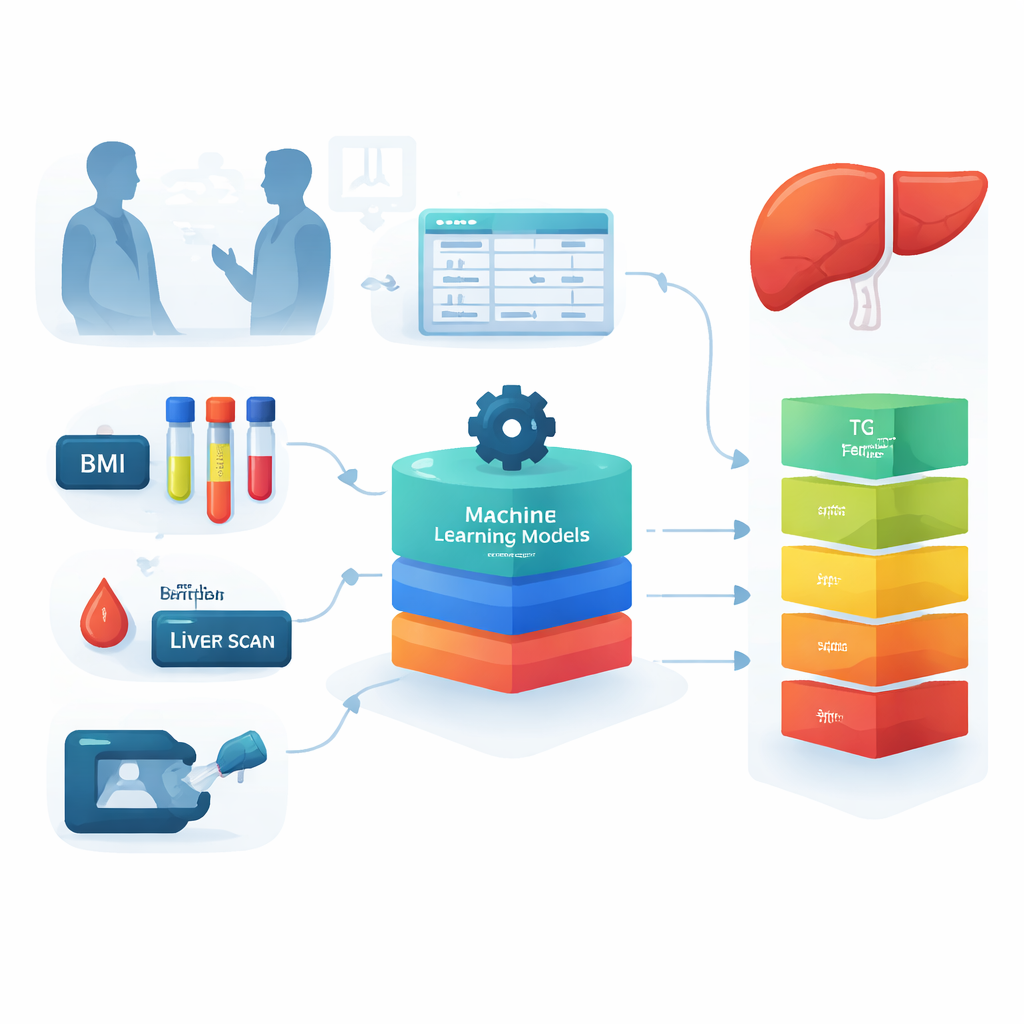
De onderzoekers stelden de vraag of alledaagse klinische gegevens kunnen worden omgezet in een krachtig screeningsinstrument. Ze gebruikten gegevens van 210 volwassenen die een maag-darmkliniek in Teheran, Iran bezochten. Voor elke persoon verzamelden ze basismetingen zoals lengte en gewicht, en standaard bloedtesten zoals cholesterol, triglyceriden, nuchtere bloedglucose, leverenzymen en ijzergerelateerde markers. De ernst van vetophoping en littekenvorming in de lever was al gemeten met een gespecialiseerd apparaat genaamd FibroScan, waarmee het team deelnemers in vijf groepen kon indelen: van gezonde lever, via milde, matige en ernstige vetophoping, tot degenen met gevorderde littekenvorming. Deze groepen dienden als de "grondwaarheid" voor het trainen en testen van de computermodellen.
De data vergroten en de machines trainen
Aangezien 210 patiënten relatief weinig is voor machine learning, creëerde het team aanvullende "synthetische" patiëntgegevens door gecontroleerde willekeurige variatie aan de echte data toe te voegen. Ze controleerden of deze gesimuleerde gegevens nog steeds hetzelfde algemene patroon volgden als de oorspronkelijke set en breidden de dataset uit tot 1.500 monsters. Vervolgens testten ze acht verschillende machine-learningbenaderingen, waaronder beslisbomen, random forests, support vector machines en neurale netwerken, evenals combinaties van deze methoden. Elk model moest voorspellen tot welke van de vijf levergezondheidsgroepen een persoon behoorde, uitsluitend op basis van de klinische en laboratoriumgegevens. De prestaties werden beoordeeld niet alleen op algemene nauwkeurigheid, maar ook op hoe zelden het model per ongeluk een zieke persoon als gezond labelde, een cruciale zorg voor elk screeningsinstrument.
De paar getallen vinden die het meest ertoe doen
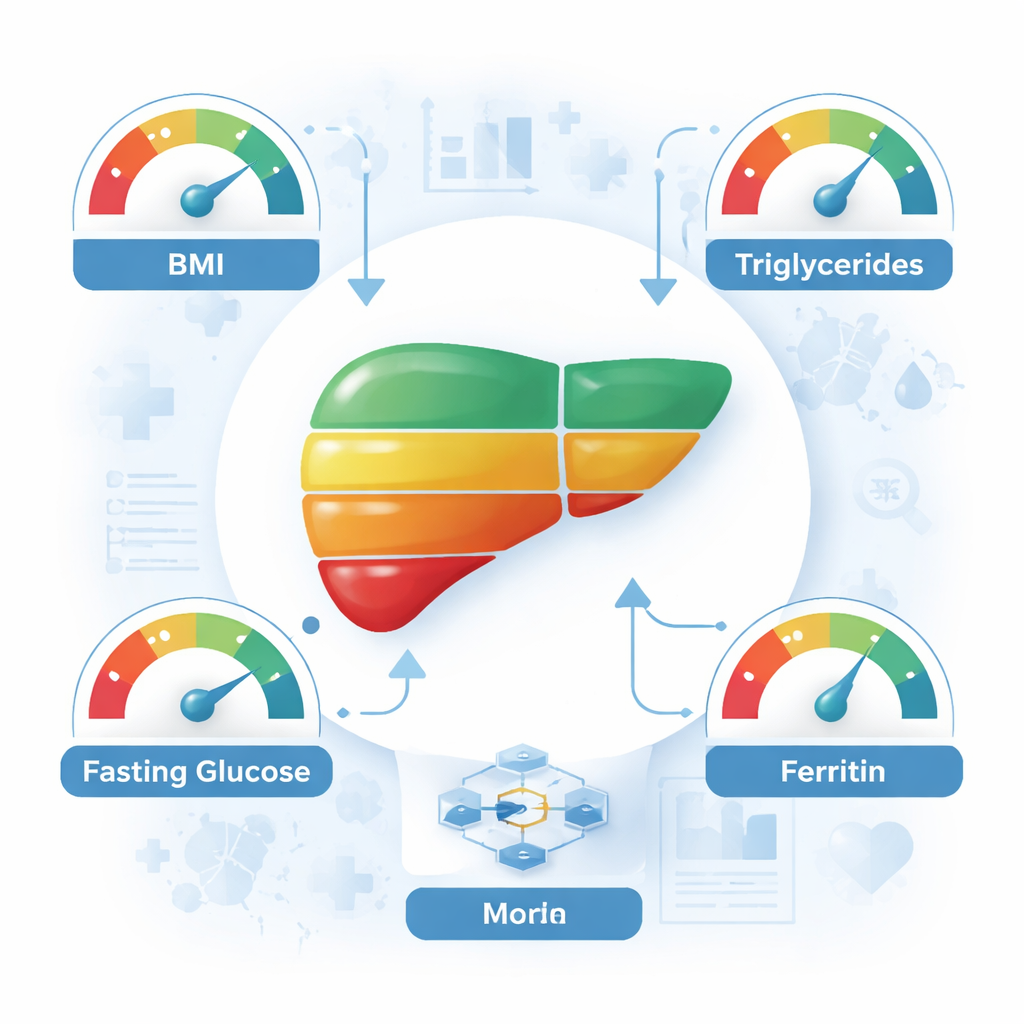
Sommige modellen, met name een hybride die support vector machines combineert met een boosting-methode (SVM–XGBoost), bereikten ongeveer 93% nauwkeurigheid bij gebruik van alle 26 beschikbare kenmerken. Om het hulpmiddel eenvoudiger en makkelijker toepasbaar te maken, onderzochten de onderzoekers vervolgens welke metingen het meest bijdroegen aan de voorspellingen. Statistische technieken wezen eerst acht bijzonder belangrijke kenmerken aan, waaronder body mass index (BMI), triglyceriden, nuchtere bloedglucose, ferritine (een ijzeropslagproteïne), bloedplaatjes, alkalische fosfatase, creatinine en een bloedstollingsmaat. Leverspecialisten beoordeelden deze resultaten vervolgens en selecteerden vier maten die zowel sterk verbonden zijn met de ziektebiologie als praktisch in de dagelijkse zorg: BMI, triglyceriden, nuchtere bloedglucose en ferritine. Opmerkelijk genoeg bleven modellen die opnieuw werden getraind met slechts deze vier invoerwaarden patiënten nog steeds in ongeveer 70% van de gevallen correct classificeren, en tot 76% met de beste methode.
Wat dit betekent voor patiënten en klinieken
Voor een leek is de belangrijkste boodschap dat een klein aantal routinematige cijfers uit een standaardcontrole — gewicht en lengte voor BMI, samen met eenvoudige bloedtesten voor vetten, suiker en ijzerreserves — een verrassend gedetailleerd beeld van de levergezondheid kan geven wanneer ze worden geïnterpreteerd door goed ontworpen computermodellen. Hoewel deze hulpmiddelen geen vervanging zijn voor deskundig medisch oordeel of gespecialiseerde beeldvorming wanneer die beschikbaar is, bieden ze een veelbelovende manier om mensen met risico te identificeren, vooral in klinieken met beperkte middelen en in regio's waar vetslever veel voorkomt. Vroegere opsporing kan aanleiding geven tot leefstijlveranderingen, zoals gewichtsverlies, gezondere voeding en meer lichamelijke activiteit, waarvan bekend is dat ze de levergezondheid verbeteren. Deze studie suggereert dat in de nabije toekomst uw reguliere laboratoriumuitslagen kunnen fungeren als een vroeg waarschuwingssysteem voor een stille maar ernstige ziekte.
Bronvermelding: Sadeghi, B., Zarrinbal, M., Poustchi, H. et al. Diagnosis and grading of steatotic liver disease via clinical and laboratory data using machine learning. Sci Rep 16, 6866 (2026). https://doi.org/10.1038/s41598-026-36834-2
Trefwoorden: vetsleverziekte, machine learning, bloedonderzoeken, BMI en triglyceriden, niet-invasieve diagnose