Clear Sky Science · nl
Taxonomische modellering en classificatie in rapportage van storingen aan ruimtehardware
Patronen vinden in ruimtevluchtstoringen
Elke missie naar de ruimte steunt op talloze hardwareonderdelen die feilloos moeten werken, van bouten en kabels tot levensondersteunende systemen. Wanneer er iets misgaat, leggen ingenieurs gedetailleerde discrepantieverslagen vast, maar NASA beschikt inmiddels over meer dan 54.000 van deze dossiers — veel te veel om handmatig stuk voor stuk te lezen. Deze studie laat zien hoe moderne taal- en machine-learningtechnieken die berg tekst kunnen omzetten in geordende kennis, waardoor ingenieurs patronen in storingen kunnen herkennen, ontwerpen kunnen verbeteren en astronauten veiliger kunnen houden.
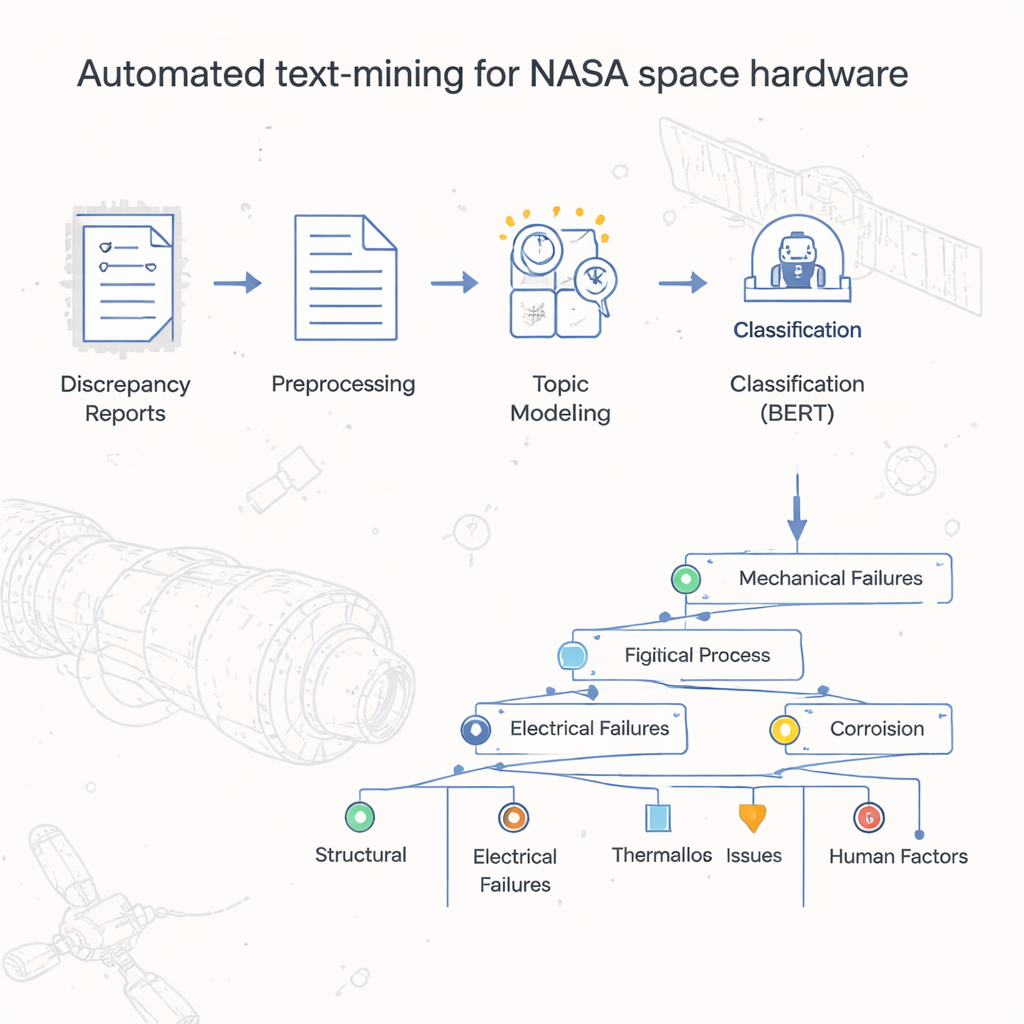
Van stapels rapporten naar geordend inzicht
Decennialang bewaarde NASA’s Johnson Space Center rapporten over hardwarestoringen en discrepanties als digitale documenten, vergelijkbaar met gescande versies van oude papieren formulieren. Eenvoudige spreadsheet-tellingen lieten zien welke officiële defectcodes het vaakst voorkwamen, maar het echte verhaal — de specifieke oorzaken, stappen en omstandigheden die tot problemen leidden — zat verborgen in vrije-tekstvelden. Meer dan 54.000 dossiers handmatig lezen en categoriseren zou ondoenlijk veel tijd kosten. De auteurs wilden een geautomatiseerde methode bouwen om deze rapporten te classificeren en te groeperen, en zo een soort 'kaart' of taxonomie creëren die vastlegt hoe ruimtehardware in de praktijk daadwerkelijk faalt.
Computers leren de engineeringtaal te lezen
Het team maakte eerst de tekst in elk rapport schoon zodat computers er effectief mee konden werken. Ze verwijderden losse symbolen en cijfers die ruis toevoegden, splitsten zinnen in afzonderlijke woorden en brachten die terug tot een eenvoudigere grondvorm (bijvoorbeeld door “gelekt” en “lekt” terug te brengen tot “lek”). Veelvoorkomende woorden zonder veel betekenis, zoals “de” of “en”, werden gefilterd. Zodra de tekst gestandaardiseerd was, zetten de onderzoekers die om in cijfers die machine-learningalgoritmen kunnen verwerken, met beproefde technieken die vastleggen hoe vaak woorden voorkomen en hoe sterk ze een document karakteriseren. Deze voorbereiding maakte het mogelijk krachtige hulpmiddelen, oorspronkelijk ontwikkeld voor algemene taaltoepassingen, toe te passen op de sterk gespecialiseerde wereld van rapporten over ruimtehardware.
Een boom van fouttypes opbouwen
Centraal in het project staat een tweestapsmodel dat de auteurs LDA-BERT noemen. De eerste stap, Latent Dirichlet Allocation (LDA), ontdekt automatisch thema’s — topics genoemd — door te zoeken naar woordpatronen die vaak samen voorkomen in duizenden rapporten. Een enkel rapport kan meerdere topics mengen, wat de realiteit weerspiegelt waarin één hardwareprobleem meerdere bijdragende kwesties kan hebben. De tweede stap gebruikt BERT, een modern taalmodel, om te controleren en verfijnen hoe goed deze topics de rapporten scheiden. Door de LDA-topics als voorlopige labels te behandelen en BERT te trainen om die te voorspellen, konden de onderzoekers het aantal en de combinatie van topics identificeren die stabiele, nauwkeurige classificaties opleverden. Vervolgens deelden ze elk topic verder op in subtopics, met behulp van clustering en statistische toetsen, om een vertakkende taxonomie te construeren die storingsrapporten ordent van brede defectcodes tot gedetailleerde procesniveaulabels.
Taxonomieën omzetten in bruikbare trends
Zodra de taxonomie klaar was, visualiseerde het team die met dashboards en interactieve tools. Elke tak en subtak van de boom kon worden gekoppeld aan andere informatie in de rapporten: wanneer een probleem voor het eerst werd gemeld, hoe lang het duurde om het af te handelen, welke organisatie verantwoordelijk was en welke eindbeslissing werd genomen. Tijdreeksgrafieken lieten zien of bepaalde typen problemen — zoals inspectieoversights of tolerantiedata-kwesties — over de jaren vaker of juist minder vaak voorkwamen. Woordkaarten gaven snel een indruk van de taal die in elk cluster werd gebruikt zonder elk rapport te hoeven lezen. Deze weergaven helpen managers zich te richten op sterk stijgende en hoogrelevante processtoringen, en sturen training, procedurewijzigingen of ontwerpaanpassingen waar ze het meest effect hebben.
Beperkingen van automatische zoektocht naar oorzaken
De onderzoekers onderzochten ook hulpmiddelen die verder willen gaan dan labelen en trendherkenning, door te proberen directe oorzaak-gevolgrelaties uit tekst af te leiden. Ze testten systemen zoals INDRA-Eidos en aangepaste regelsets gebouwd met de spaCy-taalbibliotheek. Hoewel deze tools enkele oorzaak-en-gevolg-paren konden extraheren en visualiseren als interactieve netwerken, waren veel voorgestelde koppelingen te vaag of verwarrend om nuttig te zijn. In de praktijk hadden de modellen moeite omdat de oorspronkelijke rapporten vaak geen worteloorzaken expliciet benoemden; ingenieurs suggereerden die of lieten ze open voor nader onderzoek. De studie concludeert dat betrouwbare automatisering van worteloorzaakontdekking zowel rijkere gegevensinvoer — zoals expliciete velden voor waarschijnlijke oorzaken — als duurdere, sterk op maat gemaakte modeltraining zou vereisen, wat voor deze eenmalige analyse niet gerechtvaardigd is.
Waarom dit belangrijk is voor toekomstige missies
Door een groot, ongestructureerd archief van storingsrapporten om te zetten in een duidelijke, gelaagde taxonomie biedt dit werk NASA een praktische manier om bij te houden hoe en waarom hardwareproblemen zich in de loop van de tijd voordoen. Hoewel de methoden nog geen menselijke beoordelingskracht kunnen vervangen voor diepgaande worteloorzaakanalyses, blinken ze uit in het scannen van enorme hoeveelheden tekst om te benadrukken waar problemen zich clusteren en welke processen vaak betrokken zijn. Dat soort vroege waarschuwing en gestructureerd inzicht kan engineeringteams helpen hun aandacht te richten, procedures te verfijnen en robuustere systemen te ontwerpen — concrete stappen naar veiligere, betrouwbaardere missies naar de Maan, Mars en verder.
Bronvermelding: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
Trefwoorden: storingen in ruimtehardware, verwerking van natuurlijke taal, topicmodellering, risicoanalyse in engineering, NASA discrepantieverslagen