Clear Sky Science · nl
Collaboratieve representatie en confidentiegestuurde semi‑supervised learning voor classificatie van hyperspectrale beelden
Scherpere blik op de verborgen kleuren van de aarde
Van het volgen van de gezondheid van gewassen tot het monitoren van wetlands: onderzoekers vertrouwen steeds vaker op hyperspectrale beelden—gedetailleerde opnamen die tientallen of zelfs honderden kleuren vastleggen die ons oog niet ziet. Deze rijke gegevens beloven nauwkeurigere kaarten van landgebruik en vegetatie, maar ze zijn berucht moeilijk te analyseren. Deze studie introduceert een nieuwe methode, GCN‑ARE, die deze complexe beelden betrouwbaarder en efficiënter begrijpelijk maakt, en zo de weg vrijmaakt voor betere milieumonitoring, slimmer landbouwbeheer en verbeterde stedelijke planning.
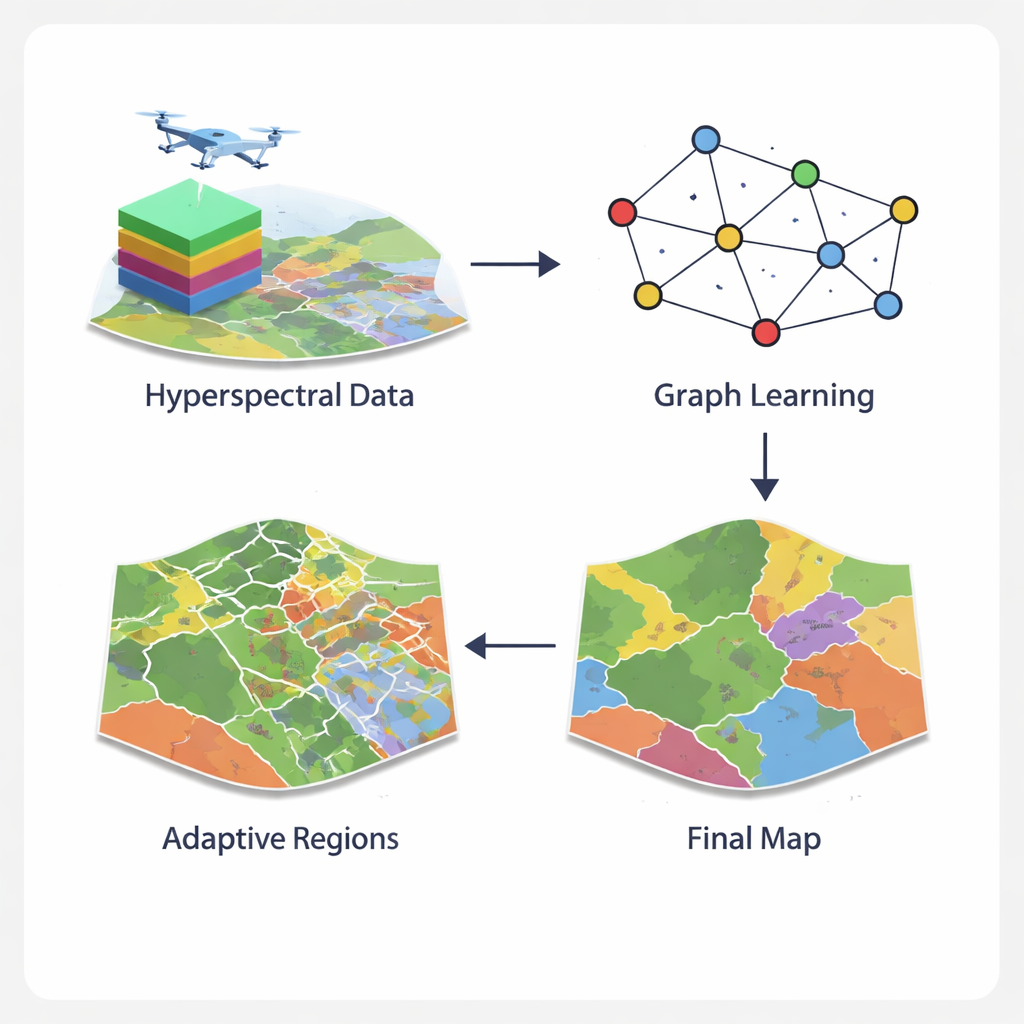
Waarom hyperspectrale beelden zo lastig zijn
In tegenstelling tot een gewone foto legt een hyperspectraal beeld voor elke pixel een volledig kleurspectrum vast. Daardoor kunnen wetenschappers bijvoorbeeld gezond gras onderscheiden van gestrest gras, of verschillende gewastypen die in gewone beelden vrijwel identiek lijken. Maar die rijkdom brengt uitdagingen met zich mee. Naburige gebieden kunnen meerdere landtypes mengen, klassen zijn vaak ongepaard (sommige landbedekkingen komen zelden voor) en het terrein kan ongelijkmatig zijn—denk aan versnipperde vegetatie of wirwar van stedelijke blokken. Traditionele machine learning steunt op handgemaakte kenmerken en mist vaak subtiele patronen, terwijl moderne diepe netwerken zoals convolutionele neurale netwerken en Transformers kunnen worstelen met onregelmatige vormen en veel rekenkracht vereisen. Daarom presteren modellen die goed werken in de ene scene vaak slecht in een andere.
Pixels omzetten in een slim netwerk
Het GCN‑ARE‑framework pakt deze problemen aan door anders te kijken naar de representatie van hyperspectrale beelden. In plaats van elke pixel geïsoleerd te behandelen of te dwingen in starre vierkante buurtjes, bouwt de methode een graaf—een netwerk waarin pixels knopen zijn en nabijgelegen pixels verbonden worden. Een gespecialiseerde graafoperator houdt de informatiestroom stabiel en voorkomt numerieke problemen die het trainen kunnen ontsporen wanneer het terrein rommelig is. Een graph‑convolutional network verspreidt en verfijnt vervolgens informatie langs dit netwerk, waarbij wordt gecombineerd wat elke pixel in zijn spectrum 'ziet' met wat de buren onthullen. Dit graafperspectief vangt complexe ruimtelijke structuren, zoals gekartelde perceelsgrenzen of gefragmenteerde stedelijke vegetatie, natuurlijker dan standaard afbeeldingsfilters.
Complexe gebieden passend maken
Zelfs met een krachtig graafmodel blijven sommige delen van een beeld moeilijk te classificeren—bijvoorbeeld randzones waar akkers een weg raken of waar vegetatie zich mengt met kale grond. GCN‑ARE pakt dit aan door het beeld adaptief op te delen in regio’s op basis van hoe goed ze worden geclassificeerd. Als een regio slecht presteert, wordt die automatisch opgesplitst in kleinere, uniformere stukken met een clusteringstap die vergelijkbare pixels groepeert. Dit proces wordt gestuurd door statistische regels, dus het is niet slechts een visuele truc: de auteurs tonen aan dat deze splitsingen theoretisch de verwachte fout van het model verminderen, waardoor het subtiele verschillen in landbedekking betrouwbaarder kan onderscheiden.
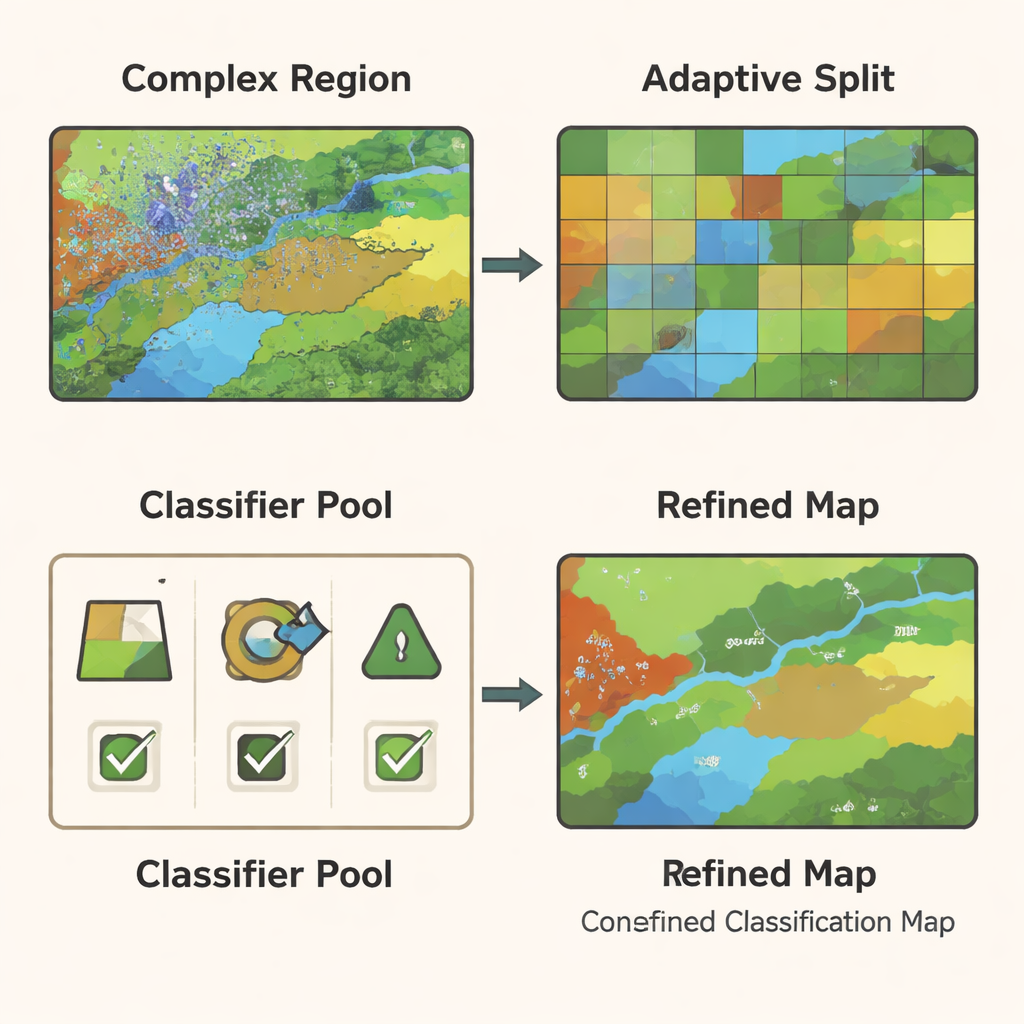
Meerdere classifiers laten stemmen—maar slim
Verschillende typen classifiers—zoals beslissingsbomen, support vector machines en random forests—blinken uit onder verschillende omstandigheden. In plaats van te gokken op één model, traint GCN‑ARE een kleine pool van deze classifiers op de graafgebaseerde kenmerken en kiest vervolgens per regio welke te gebruiken. Die keuze is niet giswerk: een wiskundig hulpmiddel, de ongelijkheid van Hoeffding, laat zien dat naarmate een regio meer data bevat, de kans snel stijgt dat de methode de werkelijk beste classifier kiest. Tijdens gebruik vergelijkt het systeem de voorspellingen van de classifiers. Als zij het eens zijn, accepteert het een consensusbeslissing; als zij het oneens zijn, activeert het de geselecteerde ‘beste’ classifier van die regio. Dit adaptieve ensemble maakt de uiteindelijke kaart zowel stabiel in gemakkelijke gebieden als scherper in moeilijke gebieden.
Aangetoond in de praktijk
De auteurs testten GCN‑ARE op vier bekende datasets: wetlands in Botswana, een stedelijk gebied rond Houston, landbouwgrond in Indiana (Indian Pines) en een hoge‑resolutie akkerscène in China (WHU‑Hi‑LongKou). Over al deze datasets behaalde hun methode hogere overall‑accuratesse, betere gemiddelde accuratesse over klassen en sterkere overeenkomstsscores dan toonaangevende benaderingen zoals graph attention networks en Vision Transformers—gewonerwijs een verbetering van de overall‑accuratesse met ongeveer 1,5 tot 5,7 procentpunt. Het was vooral sterk in het herkennen van zeldzame klassen en complexe grenzen, en deed dit met bescheiden rekentijd en geheugen. Ablatie‑experimenten toonden aan dat zowel de adaptieve regiessplitsing als het dynamische ensemble essentieel waren—het verwijderen van een van beide verminderde de prestaties merkbaar.
Wat dit betekent voor alledaagse toepassingen
In praktische zin is GCN‑ARE een slimmere manier om ruwe hyperspectrale data om te zetten in betrouwbare kaarten. Door een stabiele graafrepresentatie, gerichte regiementslijping en statistisch onderbouwde modelselectie te combineren, produceert het duidelijkere landbedekkingskaarten, zelfs wanneer gelabelde trainingsgegevens schaars zijn en het landschap rommelig. Voor boeren kan dit betekenen dat gewasmonitoring preciezer wordt met minder veldmetingen; voor milieudiensten betrouwbaardere monitoring van wetlands, bossen of stedelijke uitbreiding. Hoewel de huidige methode nog uitdagingen kent op echt zeer grote schaal, schetsen de auteurs wegen om het sneller en lichter te maken, en suggereren zij dat dergelijke adaptieve, confidentiegestuurde kaartvormingstools belangrijker zullen worden naarmate hyperspectrale sensoren zich verspreiden van satellieten naar vliegtuigen en drones.
Bronvermelding: Chen, Y., Lu, H. & Huang, X. Collaborative representation and confidence-driven semi-supervised learning for hyperspectral image classification. Sci Rep 16, 6180 (2026). https://doi.org/10.1038/s41598-026-36806-6
Trefwoorden: hyperspectrale beeldvorming, landbedekkingskaarten, graph neural networks, ensemble learning, remote sensing