Clear Sky Science · nl
Verifiëren van de authenticiteit van Urdu-nieuws met deep learning en gekoppelde BERT- en GloVe-embeddings
Waarom het belangrijk is om nepnieuws in het Urdu te herkennen
In Pakistan en wereldwijd halen steeds meer mensen hun nieuws van websites en sociale media in plaats van van kranten of televisie. Die verschuiving heeft het eenvoudiger dan ooit gemaakt voor valse berichten om zich snel te verspreiden, vooral in nationale talen zoals Urdu waar digitale hulpmiddelen beperkt zijn. Deze studie pakt een eenvoudige maar urgente vraag aan: kan moderne kunstmatige intelligentie automatisch echt Urdu-nieuws onderscheiden van nepnieuws, en zo gewone lezers, journalisten en platforms helpen zich te verdedigen tegen misleidende informatie?
De groeiende uitdaging van online misinformatie
De auteurs beginnen met te schetsen hoe verzonnen koppen en vertekende verhalen de publieke opinie kunnen vormen, politieke spanningen kunnen aanwakkeren en zelfs de gezondheid en financiën van mensen kunnen schaden. Terwijl veel factcheck-websites en onderzoeksprojecten zich op het Engels richten, blijven regionale talen zoals Urdu vaak achter. Bestaande Urdu-bronnen bevatten slechts enkele duizenden nieuwsitems, veelal vertaald uit het Engels en gericht op smalle onderwerpen zoals politiek. Dat maakt het moeilijk betrouwbare computersystemen te trainen om verdachte inhoud te herkennen in de taal die de meeste Pakistanen daadwerkelijk lezen.
Opbouw van een grote verzameling Urdu-nieuws
Om deze kloof te dichten, verzamelden de onderzoekers wat zij beschrijven als de meest uitgebreide Urdu-dataset voor nepnieuws tot nu toe, met 14.178 nieuwsartikelen uit de periode 2017–2023, afkomstig van gerespecteerde Pakistaanse nieuwssites en online platforms. De verhalen bestrijken vijftien leefgebieden, waaronder politiek, gezondheid, onderwijs, zaken, misdaad, sport en milieu. Met behulp van factcheck-bronnen zoals PolitiFact, FactCheck en gespecialiseerde nieuws-API's werd elk item gelabeld als echt of nep; deels waar-geclassificeerde items werden bij echt nieuws ingedeeld om meer genuanceerde verslaggeving te weerspiegelen. Het team heeft de tekst vervolgens opgeschoond door duplicaten, webadressen en overtollige interpunctie te verwijderen, zinnen op te delen in woorden en veelvoorkomende stopwoorden te verwijderen.
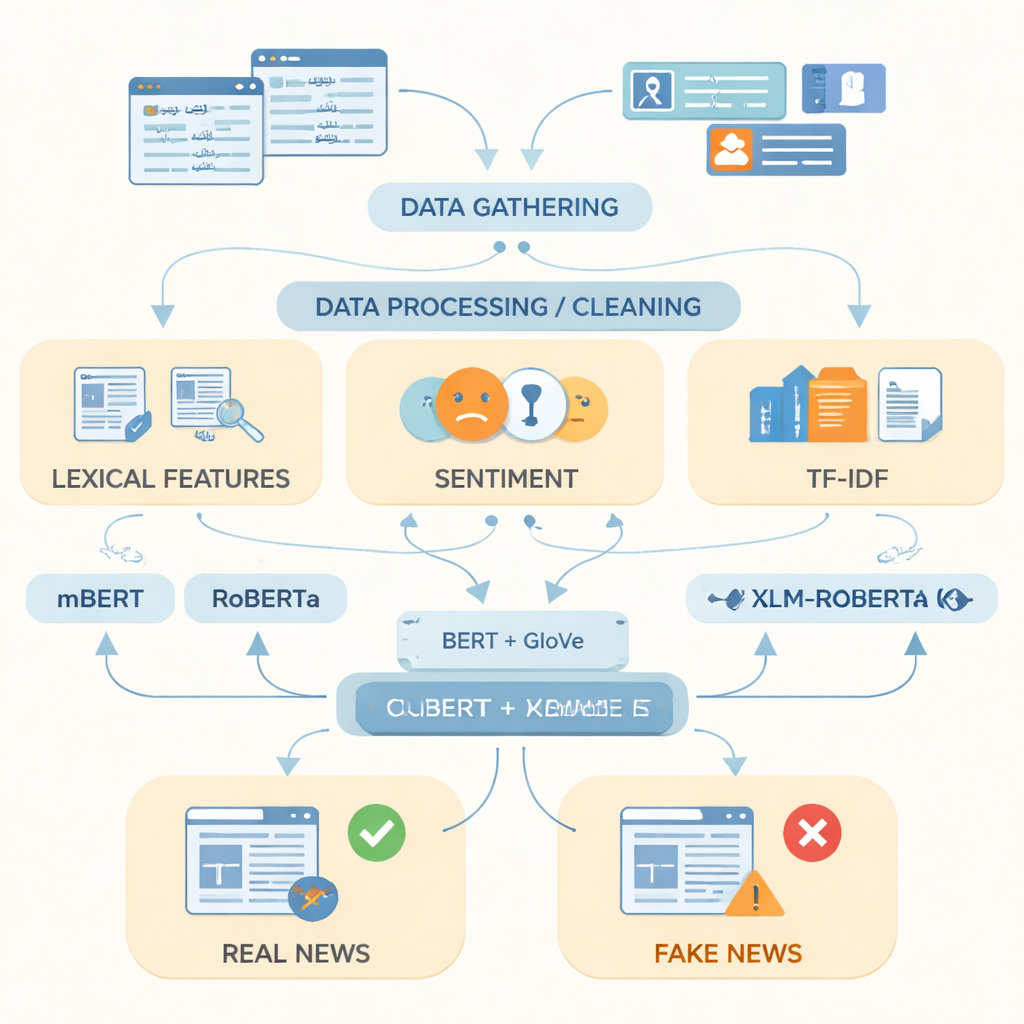
Computers leren herkennen hoe nepnieuws eruitziet
Na de voorbereiding van de data richtten de auteurs zich op de beste manier om Urdu-tekst voor een computer te representeren. Ze combineerden eenvoudige indicatoren zoals frequent gebruikte woorden, de emotionele toon van de taal en termfrequentiescores met twee krachtige woordrepresentatietechnieken. De ene, GloVe genaamd, behandelt elk woord als een vaste numerieke vector gebaseerd op hoe vaak het samen met andere woorden voorkomt in de hele verzameling. De andere, gebaseerd op BERT-achtige modellen, bekijkt elk woord in zijn zin en kent het een contextbewuste betekenis toe. Door deze twee taalperspectieven in één rijkere representatie te combineren, kan het systeem zowel algemene patronen als subtiele verschuivingen in woordkeus vastleggen die vaak nep- en echte verhalen van elkaar onderscheiden.
Geavanceerde taalmodellen op de proef gesteld
De onderzoekers voerden deze representaties vervolgens in drie moderne deep learning-modellen die op teksten uit meerdere talen zijn getraind: mBERT, RoBERTa en XLM-RoBERTa. Alle drie werden fijn afgesteld op de Urdu-dataset om te voorspellen of elk artikel echt of nep was. Hun prestaties werden beoordeeld met standaardmaatstaven: nauwkeurigheid (hoe vaak ze het bij het juiste eind hadden), precisie (hoe vaak aangewezen nepitems daadwerkelijk nep waren), recall (hoeveel van alle nepverhalen ze vingen) en de F1-score, die precisie en recall in evenwicht brengt. Hoewel elk model sterk presteerde, bleek XLM-RoBERTa in combinatie met de samengevoegde BERT- en GloVe-representatie het beste: het classificeerde ongeveer 96 procent van de testartikelen correct en behaalde een F1-score van 0,956—beter dan eerdere Urdu-nepnieuwssystemen die kleinere datasets of eenvoudigere methoden gebruikten.
Wat dit betekent voor dagelijkse lezers
Voor niet-specialisten is de boodschap helder: met voldoende hoogwaardige Urdu-gegevens en het juiste type AI is het nu mogelijk tools te bouwen die waarschijnlijk nepverhalen automatisch en met hoge betrouwbaarheid markeren. De studie toont aan dat rijkere taalrepresentaties en meertalige modellen computers veel beter laten begrijpen hoe Urdu daadwerkelijk wordt geschreven in verschillende regio's en onderwerpen. Hoewel het huidige werk zich uitsluitend op tekst richt en nog geen beelden of gedrag op sociale media analyseert, legt het een solide basis voor toekomstige systemen die over talen en mediatypen heen kunnen werken. In praktische termen brengt dit onderzoek Pakistan een stap dichter bij browserextensies, redactiedashboards of sociale-mediasfilters die mensen helpen feit van fictie te scheiden in de taal die zij dagelijks gebruiken.
Bronvermelding: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
Trefwoorden: detectie van nepnieuws, Urdu-taal, deep learning, BERT en GloVe, misinformatie online