Clear Sky Science · nl
Verbetering van diepteinschatting op lange afstand via heterogene CNN-transformer codering en cross-dimensionale semantische fusie
Diepte zien met één oog
Moderne robots, zelfrijdende auto's en drones vertrouwen vaak op dure 3D-sensoren om afstanden te bepalen. Deze studie laat zien hoe gewone kleurencamera's, zoals die in smartphones, veel verder kunnen worden benut: de auteurs ontwerpen een nieuwe manier voor een computer om diepte uit slechts één foto af te leiden, met focus op het moeilijkste deel van de scène — de grote afstand, waar obstakels klein, wazig en makkelijk te verkeerd te schatten zijn.
Waarom verre objecten zo moeilijk te beoordelen zijn
Diepte uit een enkele afbeelding, monoculaire diepteinschatting, is een soort visuele truc. Nabije objecten beslaan veel pixels en hebben scherpe texturen, waardoor neurale netwerken tegenwoordig al goed presteren op korte en middellange afstanden. Verder weg krimpen auto’s tot een paar pixels en vervagen wegmarkeringen in nevel. Standaard convolutionele neurale netwerken zijn goed in het oppikken van fijne lokale details maar hebben moeite het grotere geheel van een straat in zich op te nemen. Nieuwere Transformer-modellen vangen de globale context goed, maar zijn minder gevoelig voor fijne randen en texturen. Daardoor struikelen beide methoden vaak precies daar waar betrouwbare schattingen het meest nodig zijn voor veilige navigatie: op lange afstand.
Twee manieren van zien mengen
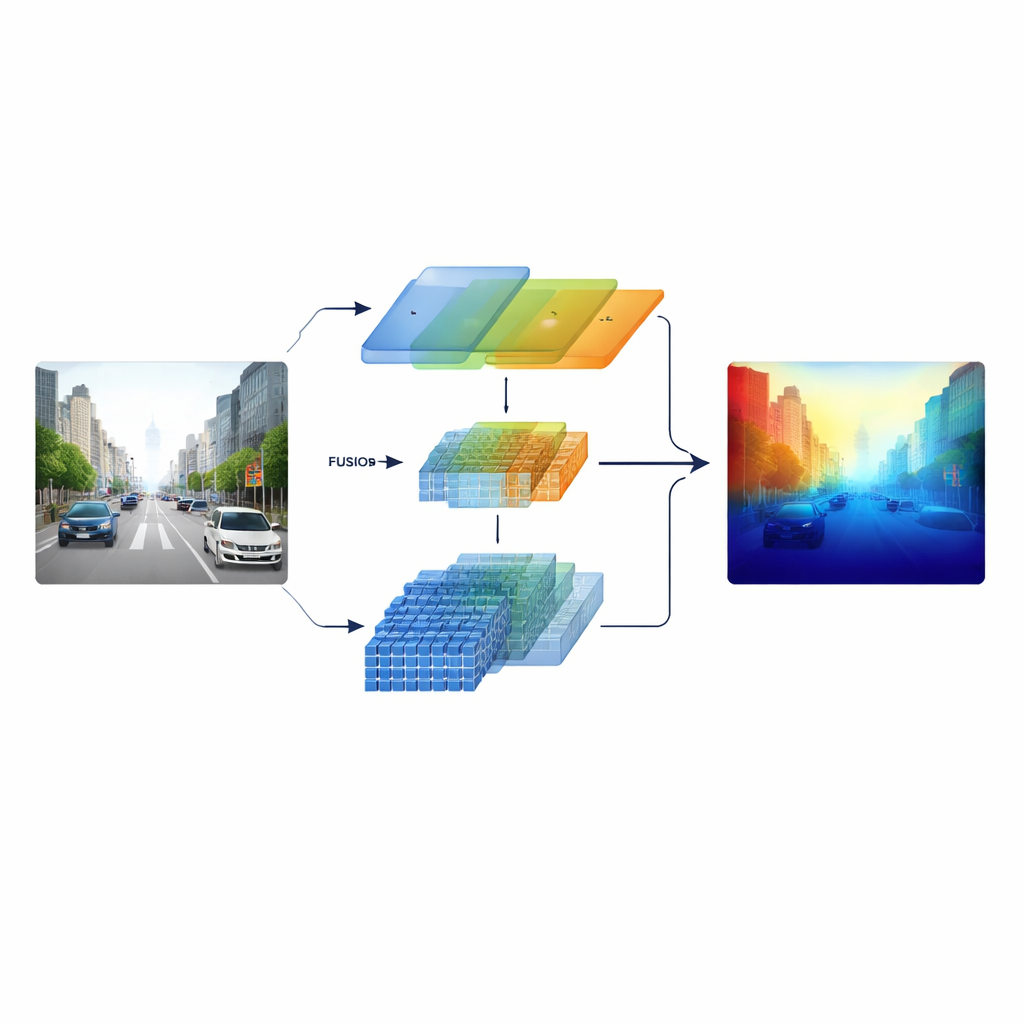
De onderzoekers pakken dit aan door een "heterogene" encoder te bouwen die twee verschillende typen visuele verwerking parallel uitvoert. De ene tak is gebaseerd op een klassieke ResNet-achtige convolutionele netwerkarchitectuur die zich specialiseert in scherpe lokale patronen zoals wegmarkeringen, lantaarnpalen en objectranden. De andere tak gebruikt een Swin Transformer, ontworpen om langbereikconnecties over de afbeelding vast te leggen, zoals de indeling van een wegcorridor of de skyline van verre gebouwen. In plaats van deze twee zienswijzen pas aan het einde te combineren, bewaart het systeem multi-schaal kenmerken van beide takken en voert ze naar een zorgvuldig ontworpen fusiefase, zodat fijne structuren en brede context elkaar gedurende het hele proces informeren.
Kanalen, ruimte en schaal kruisen
Centraal in het model staat een Cross-dimensional Semantic Fusion-module die fungeert als een slimme vergaderruimte voor de twee informatiestromen. Eerst bepaalt het welke kanalen — verschillende typen aangeleerde visuele patronen — meer aandacht verdienen, waarbij signalen van gedetailleerde texturen en hoge-niveau scènaanduidingen worden gebalanceerd. Daarna bekijkt het apart horizontale en verticale richtingen, die vooral veelzeggend zijn in scènes vol wegen, gebouwen en bomen, om belangrijke structuren te benadrukken die zich over de afbeelding uitstrekken. Ten slotte mengt het ondiepe, detailrijke kenmerken met diepere, meer abstracte kenmerken over meerdere schalen. Een leerbare weging laat het netwerk beslissen hoeveel vertrouwen het aan elke tak geeft voor elk gebied, zodat kleine, verre objecten niet worden weggedrukt door nabij landschap.
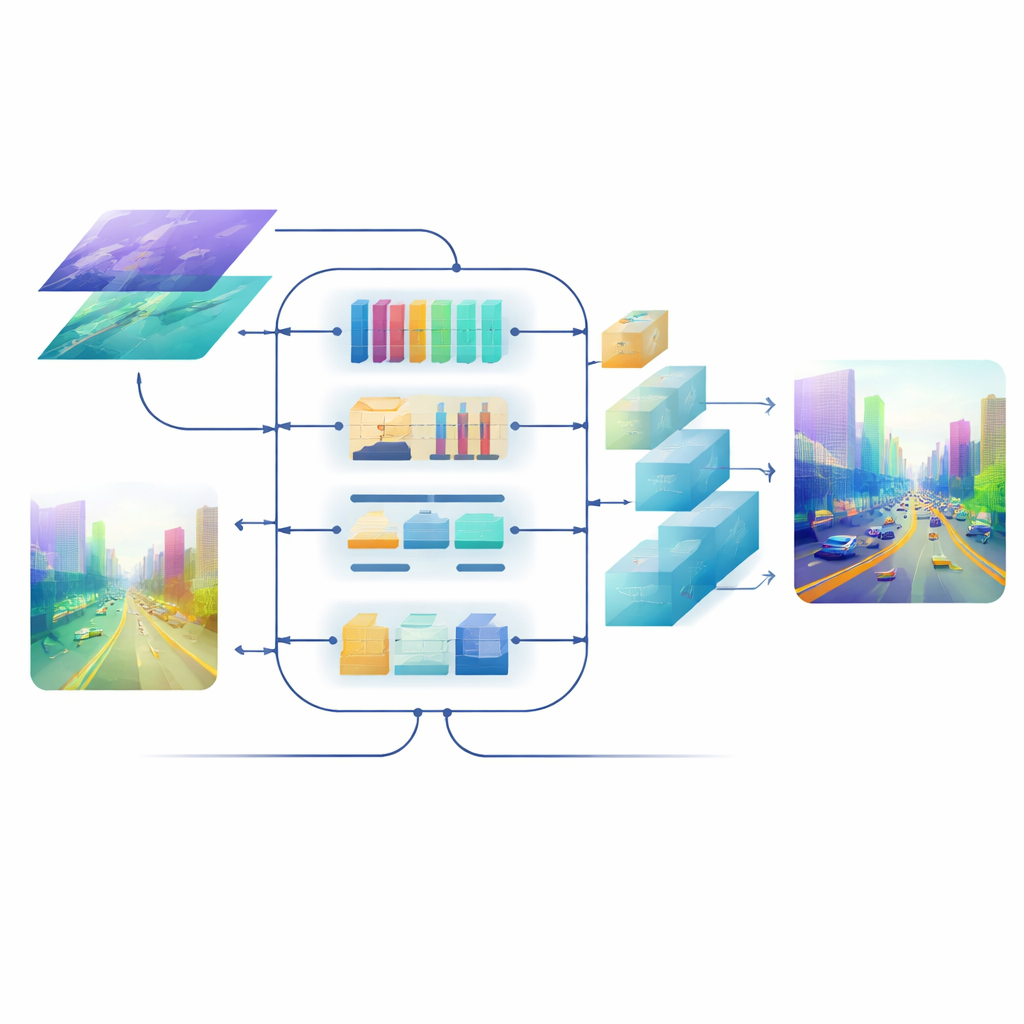
Het eindbeeld verscherpen
Zelfs met goed gefuseerde kenmerken kan het terugzetten naar een volledige resolutie dieptemap randen vervagen en dunne structuren doen verdwijnen. Om dit te voorkomen, ontwerpt het team een attention-gestuurde decoder. Zijn upsampling-blokken gebruiken lichtgewicht, depth-wise convoluties om de kaart te vergroten zonder context te verliezen, en een multi-schaal self-attentionmechanisme groepeert feature-kanalen zodat attention efficiënt kan worden berekend. Deze stap verfijnt dieptevoorspellingen op elke schaal terwijl de rekencapaciteit beheersbaar blijft. Het resultaat is een vloeiend, coherent diepteveld waarin objectgrenzen — zoals de omtrek van een verre fietser of de sporten van een stapelbed — scherp blijven.
Hoe goed het in de praktijk werkt
De methode is getest op meerdere standaarddatasets. Op KITTI, een grote verzameling rijscènes, behaalt het model staat-van-de-kunst nauwkeurigheid op de meeste gebruikelijke metrics en levert, cruciaal, de laagste fout in aangewezen lange-afstand regio's. Het produceert ook schonere dieptegrenzen rond objecten dan concurrerende systemen. Op NYU Depth V2, met binnenscènes, en op de SUN RGB-D benchmark generaliseert hetzelfde model succesvol en reconstrueert het meubels en kamerlayouts in overtuigende 3D-puntenwolken. Ablatie-studies — systematische tests die componenten verwijderen of vervangen — tonen aan dat elk voorgesteld onderdeel, van de hybride encoder tot de fusiemodule en het attention-blok van de decoder, de prestaties meetbaar verbetert, vooral voor verre, laag-textuur gebieden.
Wat dit betekent voor alledaagse technologie
Simpel gezegd leert dit werk een neuraal netwerk tegelijk een vergrootglas en een groothoeklens te gebruiken, en ze verstandig te combineren. Door lokale details en globale scènbegrip beter in balans te brengen, verbetert het voorgestelde raamwerk aanzienlijk hoe goed een enkele camera diepte aan het einde van de weg of aan de andere kant van een kamer kan inschatten. Dat maakt het praktischer om robots, voertuigen en drones uit te rusten met goedkopere sensoren, terwijl ze toch een rijke 3D-ervaring van de wereld krijgen — een belangrijke stap naar veiligere, capabelere en betaalbaardere autonome systemen.
Bronvermelding: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
Trefwoorden: monoculaire diepteinschatting, computervisie, transformer en CNN fusie, autonoom rijden, 3D-scène reconstructie