Clear Sky Science · nl
Kernel mean matching verbetert risico-inschatting bij ruimtelijke distributieverschuivingen
Waarom risico-inschatting onder verschuivende kaarten ertoe doet
Machine-learningmodellen worden steeds vaker gebruikt om te voorspellen waar soorten zullen voorkomen, hoe tumoren in weefsel zijn georganiseerd of hoe vervuiling zich verspreidt. De gegevens waarop deze modellen worden getraind, worden echter vaak in zeer specifieke locaties verzameld — dicht bemonsterd nabij steden, ziekenhuizen of gemakkelijk bereikbare veldlocaties — terwijl de modellen over veel grotere, andere gebieden worden toegepast. Deze mismatch tussen herkomst van de trainingsdata en de toepassingsgebieden kan modellen veiliger en nauwkeuriger doen lijken dan ze werkelijk zijn. De paper "Kernel mean matching enhances risk estimation under spatial distribution shifts" stelt een ogenschijnlijk eenvoudige vraag: als de wereld er anders uitziet dan je trainingsdata, hoe fout kan je model dan zijn, en hoe kun je dat ontdekken?
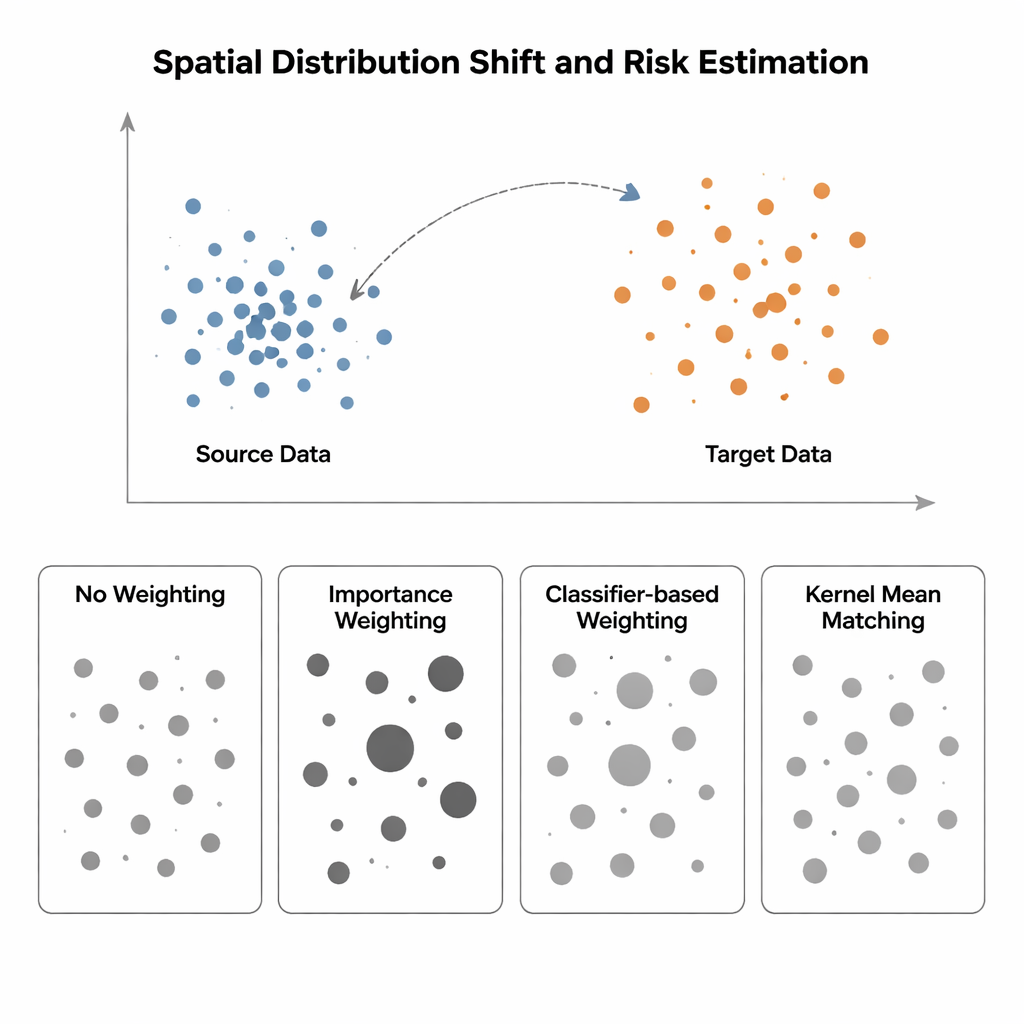
Wanneer training en testen in verschillende werelden leven
In de statistiek is het "risico" van een model de verwachte fout op nieuwe, niet-gezien data. Standaard evaluatietrucs — zoals cross-validatie of het apart houden van een willekeurige testset — veronderstellen stilzwijgend dat trainings- en testdata uit dezelfde distributie komen. Ruimtelijke data doorbreken deze aanname. Milieugradiënten, geclusterde bemonstering en veranderende klimaten betekenen dat de condities waarop we een model trainen sterk kunnen afwijken van de condities waar we het inzetten. Zo zijn soortenwaarnemingen vaak geconcentreerd nabij wegen, terwijl natuurbeschermingsbesluiten zich op afgelegen gebieden richten; tumormonsters kunnen uit één deel van een weefsel worden genomen, maar voorspellingen zijn elders nodig. In zulke gevallen zijn conventionele risicoschattingen vaak te optimistisch en verbergen ze hoe ernstig een model in nieuwe locaties kan falen.
Oude hulpmiddelen hebben moeite met ruimtelijke bias
De studie vergelijkt vier manieren om modelrisico te schatten wanneer de inputdistributie verschuift van een "bron"gebied (waar labels bekend zijn) naar een "doel"gebied (waar labels schaars of afwezig zijn). De eenvoudigste methode, No Weighting, meet gewoon de gemiddelde fout op beschikbare data en gaat ervan uit dat bron en doel vergelijkbaar zijn — een aanname die bij ruimtelijke bias niet standhoudt. Importance Weighting probeert dit te corrigeren door elk bronsample te schalen op basis van hoe vaak dat soort punt voorkomt in het doel ten opzichte van de bron. In theorie herstelt dit het juiste risico, maar in de praktijk vereist het het schatten van kansdichtheden in hoge dimensies. Wanneer brondata sterk geclusterd zijn en doeldata meer verspreid — een typische situatie in ruimtelijke ecologie of medische beeldvorming — worden deze dichtheidsschattingen onbetrouwbaar en krijgen enkele samples enorme gewichten, waardoor de risicoschatting extreem instabiel wordt. Classifier-gebaseerde benaderingen, die een classifier trainen om bron en doel te onderscheiden en diens waarschijnlijkheden in gewichten omzetten, vermijden expliciete dichtheidsschatting maar geven vaak slecht gekalibreerde risico’s omdat ze classificatienauwkeurigheid optimaliseren in plaats van distributieaanpassing.
Een andere route: distributies direct matchen
De auteurs pleiten voor Kernel Mean Matching (KMM), een aanpak die dichtheidsschatting volledig omzeilt. In plaats van te proberen uit te rekenen hoe waarschijnlijk elk punt is onder bron- en doelverdelingen, zoekt KMM naar gewichten op bronsamples zodat hun gemiddelde "handtekening" in een flexibele, door een kernel bepaalde featurespace overeenkomt met die van de doelmonsters. Intuïtief vergroot of verkleint het de invloed van elk bronpunt zodat de gewogen bronwolk gezamenlijk op de doelwolk gaat lijken. Zodra deze gewichten zijn gevonden, wordt het risico geschat als een gewogen gemiddelde van de bronfouten. Een aanvullend hulpmiddel, de Local Correlation Function, kwantificeert hoe sterk de data in de ruimte geclusterd zijn; het dient als diagnose om aan te geven wanneer distributieverschuivingen sterk genoeg zijn dat herweging waarschijnlijk behulpzaam is.
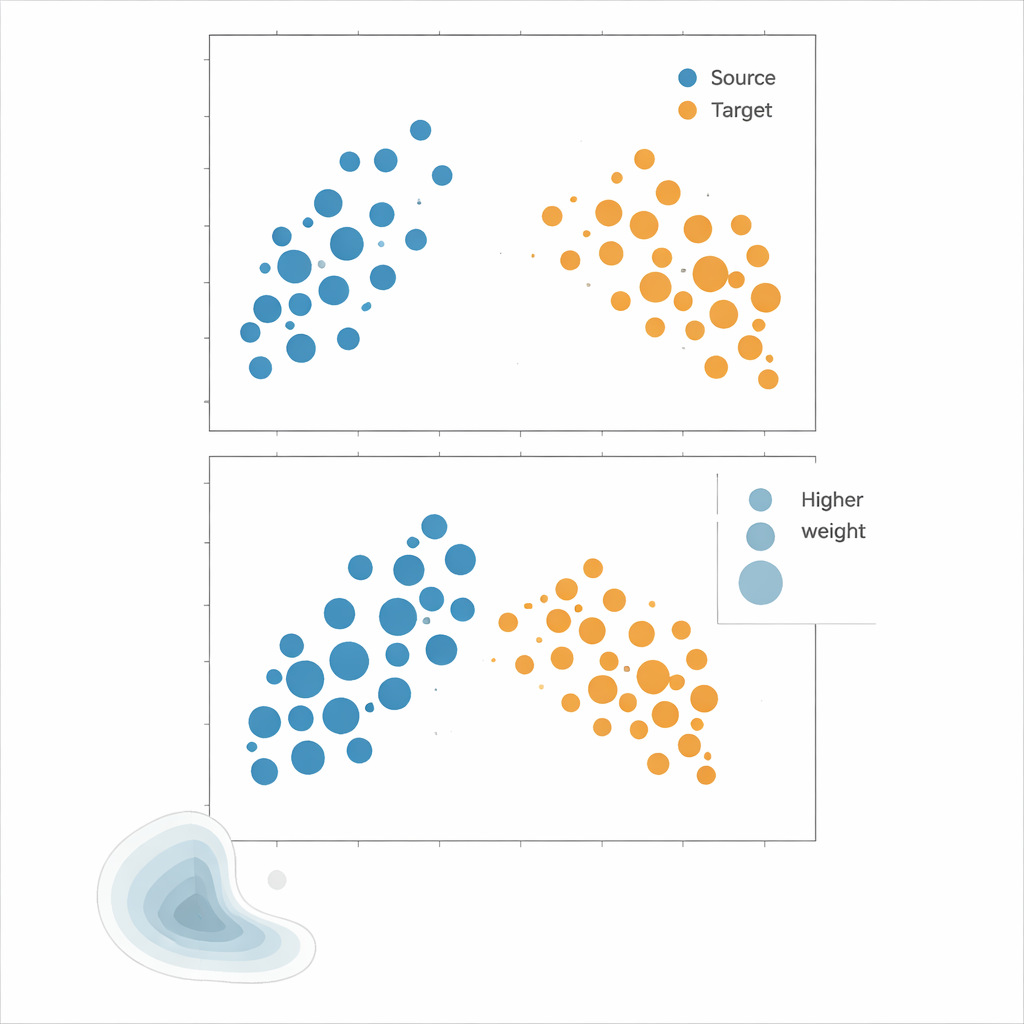
De methoden op de proef stellen
Om te bepalen welke strategie het beste werkt, voeren de auteurs uitgebreide experiments uit op zowel synthetische als echte data. Synthetische "landschappen" zijn opgebouwd uit mengsels van Gaussiaanse clusters waarvan spreiding, vorm en domeindekking precies kunnen worden gecontroleerd, waardoor gestructureerde tests mogelijk zijn zoals het bijsnijden van een deel van het domein, het veranderen van correlatiepatronen tussen kenmerken of het schakelen tussen sterk geclusterde en bijna uniforme puntpatronen. Reële datasets omvatten waarnemingen van Noordse plantensoorten, beschreven door klimaat en locatie, en ruimtelijke indelingen van immuuncellen binnen tumoren. In al deze scenario’s worden modellen getraind op geclusterde brondataset en geëvalueerd op minder-geclusterde doeldata, wat veelvoorkomende bemonsteringsbias nabootst. De prestaties worden beoordeeld met meerdere foutmaten, met de nadruk op hoe nauwkeurig de geschatte risico’s van elke methode het werkelijke foutniveau op het doel volgen.
Betere risicoschatting in rommelige, hoge-dimensionale ruimtes
Over bijna alle synthetische opstellingen en echte datasets levert KMM de meest nauwkeurige en stabiele risicoschattingen. Het vermindert de gemiddelde absolute procentuele fout met ongeveer 12 tot 87 procent vergeleken met de alternatieven, en voorkomt vooral de "gewichtsexplosie" die importance weighting in hoge dimensies teistert. In uitdagende tumorceldistributies kan importance weighting bijvoorbeeld fouten opleveren die meerdere duizenden procenten overschrijden, terwijl KMM binnen beheersbare grenzen blijft. Classifier-gebaseerde herweging verbetert doorgaans ten opzichte van naïeve methoden maar blijft achter bij KMM, wat weerspiegelt dat het zich richt op discriminatie in plaats van op trouw distributies af te stemmen. Deze resultaten suggereren dat voor ruimtelijke toepassingen — waar data geclusterd, vertekend en hoog-dimensionaal zijn — KMM een beproefde manier biedt om in te schatten hoeveel vertrouwen je in de voorspellingen van een model kunt stellen.
Wat dit betekent voor beslissingen in de praktijk
Voor niet-specialisten die machine learning toepassen in ecologie, milieuwetenschappen of biomedicine is de boodschap helder: standaard testscores kunnen gevaarlijk misleidend zijn wanneer je inzetgebied verschilt van waar je data vandaan komen. Kernel Mean Matching biedt een manier om dit te corrigeren door de invloed van trainingssamples zodanig te herbalanceren dat ze statistisch lijken op de plaatsen of weefsels die voor jou van belang zijn. De studie toont aan dat deze aanpak consequent eerlijkere schattingen van modelfouten oplevert, zelfs bij ernstige ruimtelijke bias en met veel invoervariabelen. In de praktijk betekent dat betrouwbaardere begeleiding bij het kiezen tussen modellen en een duidelijker beeld van waar voorspellingen betrouwbaar zijn — en waar voorzichtigheid geboden is.
Bronvermelding: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
Trefwoorden: distributieverschuiving, ruimtelijke modellering, kernel mean matching, modelrisico-inschatting, ecologische en biomedische data