Clear Sky Science · nl
Verbetering van adversaire veerkracht in semantische caching voor veilige retrieval-augmented generation-systemen
Waarom slimmer AI-geheugen ertoe doet
Naarmate chatbots en AI-assistenten hun intrede doen op de werkvloer, in klaslokalen en zelfs in ziekenhuizen, vertrouwen ze steeds vaker op een trucje: het «onthouden» van eerdere vragen zodat ze vergelijkbare vragen sneller en goedkoper kunnen beantwoorden. Dit geheugen, bekend als een semantische cache, kan kosten en vertragingen drastisch verlagen — maar het kan ook een achterdeur openen voor aanvallers die systemen misleiden om geheimen te lekken of foutieve antwoorden te geven. Dit artikel onderzoekt die verborgen risico’s en introduceert een nieuw ontwerp, SAFE-CACHE, dat het geheugen van AI snel houdt terwijl het veel moeilijker wordt om het te misbruiken.
Hoe hedendaagse AI-assistenten eerdere antwoorden hergebruiken
Moderne grote taalmodellen (LLM’s) werken vaak binnen een opzet die retrieval-augmented generation (RAG) wordt genoemd. Wanneer je een vraag stelt, zoekt het systeem eerst relevante documenten en laat vervolgens het LLM een antwoord formuleren op basis van dat materiaal. Omdat veel mensen vrijwel dezelfde vraag op verschillende manieren stellen, voegen bedrijven nu een semantische cache toe: een opslag van oude vragen en antwoorden, plus wiskundige vingerafdrukken van hun betekenis. Wanneer een nieuwe query binnenkomt, controleert het systeem of de vingerafdruk daarvan «nabij genoeg» is bij een bestaande in de cache; zo ja, wordt gewoon het oude antwoord hergebruikt in plaats van het hele zoek-en-genereerproces opnieuw te doorlopen. Dit idee, toegepast in tools zoals GPTCache en cloudplatforms van Microsoft en Google, bespaart geld en versnelt reacties in klantenservice-bots, enterprise chattools en andere AI-diensten met veel verkeer. 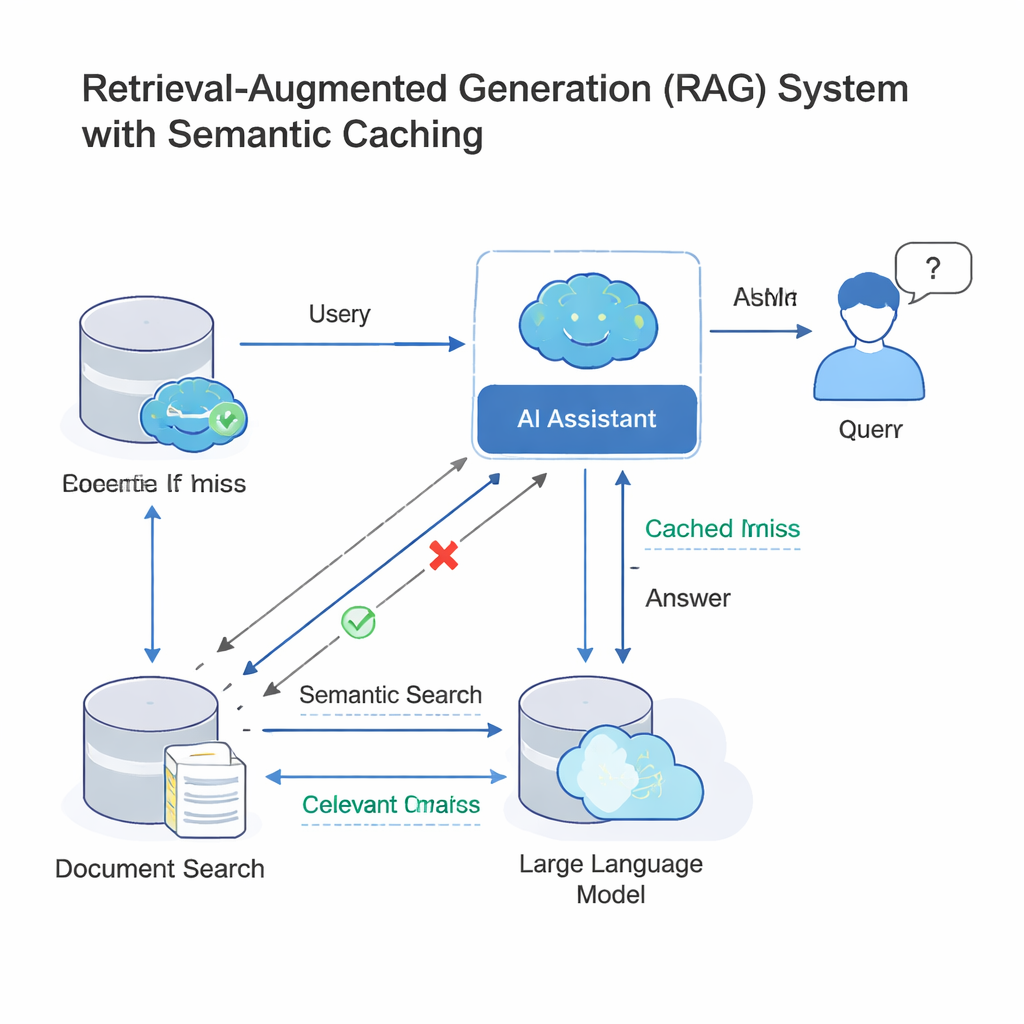
Wanneer slim geformuleerde vragen in een beveiligingslek veranderen
Dezelfde shortcut die de snelheid verhoogt, kan ook tegen het systeem worden gebruikt. Aanvallers kunnen queries samenstellen die qua structuur vergelijkbaar lijken maar iets anders bedoelen—een datum veranderen, een persoon of plaats verwisselen, of de betekenis van een vraag omkeren. Omdat huidige caches grotendeels vertrouwen op de numerieke gelijkenis van embeddings (die vingerafdrukken van betekenis), kan een kwaadaardige query in deze vectorruimte «botsen» met een goedaardige, ook al is de intentie veranderd. Die botsing kan ertoe leiden dat de cache het verkeerde antwoord teruggeeft, mogelijk vertrouwelijke informatie prijsgeeft of slechte gegevens opslaat voor later hergebruik. Eerder werk heeft al aangetoond dat vectordatabases en semantische caches op deze manier kunnen worden vergiftigd, vooral wanneer veel gebruikers dezelfde onderliggende cache delen in multi-tenant systemen.
Verspreide vragen omzetten in stabiele intent-clusters
De auteurs betogen dat het kernprobleem is dat elke query geïsoleerd wordt behandeld. Hun oplossing, SAFE-CACHE, groepeert eerdere vraag–antwoordparen in clusters die onderliggende intenties vertegenwoordigen — zoals «wie won de Senaatsverkiezing van Arizona 2022?» of «wat is de prijs van Tesla’s Full Self-Driving-software?» In plaats van nieuwe queries direct te vergelijken met individuele oude vragen, vergelijkt SAFE-CACHE ze met het centrum, of de centroid, van elke cluster. Om deze clusters te bouwen embedt het eerst elk volledig vraag-plus-antwoord (niet alleen de vraag) zodat verschillen in antwoorden — zoals een weigering om gevoelige data prijs te geven — ook de groepering beïnvloeden. Vervolgens gebruikt het een community-detectie-algoritme om natuurlijke clusters te vinden en statistische tests om rumoerige groepen te markeren die mogelijk verschillende intenties of adversaire inzendingen mengen. Deze verdachte clusters worden opgeschoond en gesplitst met een speciaal getrainde bi-encoder die heeft geleerd eerlijke voorbeelden samen te trekken en vergiftigde voorbeelden uit elkaar te duwen.
Een klein model trainen om het AI-geheugen te versterken
Sommige intenties komen in echt verkeer maar een paar keer voor, waardoor hun clusters kwetsbaar zijn. Om ze te stabiliseren gebruikt SAFE-CACHE een fijn-afgesteld lichtgewicht taalmodel (een variant van Gemma-3 met 1 miljard parameters) om parafrasen te genereren die dezelfde intentie behouden maar de bewoording variëren. Deze extra voorbeelden maken de clusters dichter en hun centroids betrouwbaarder, zonder dat mensen duizenden varianten hoeven te labelen. Tijdens gebruik wordt elke nieuwe query embedded en vergeleken met deze centroids. Als de gelijkenis met de best passende centroid boven een zorgvuldig afgestelde drempel ligt, wordt het gecachte antwoord teruggegeven; anders valt het systeem terug op de volledige RAG-pijplijn en beslist het later hoe het nieuwe paar te clusteren. In experimenten met sterke aanvalsmethoden gebaseerd op metamorfische herschrijving en GPT‑4.1 verminderde SAFE-CACHE succesvolle vergiftigingspogingen met ongeveer twee derde tot driekwart vergeleken met een GPTCache-achtig ontwerp, terwijl de reactiesnelheid wezenlijk ongewijzigd bleef. 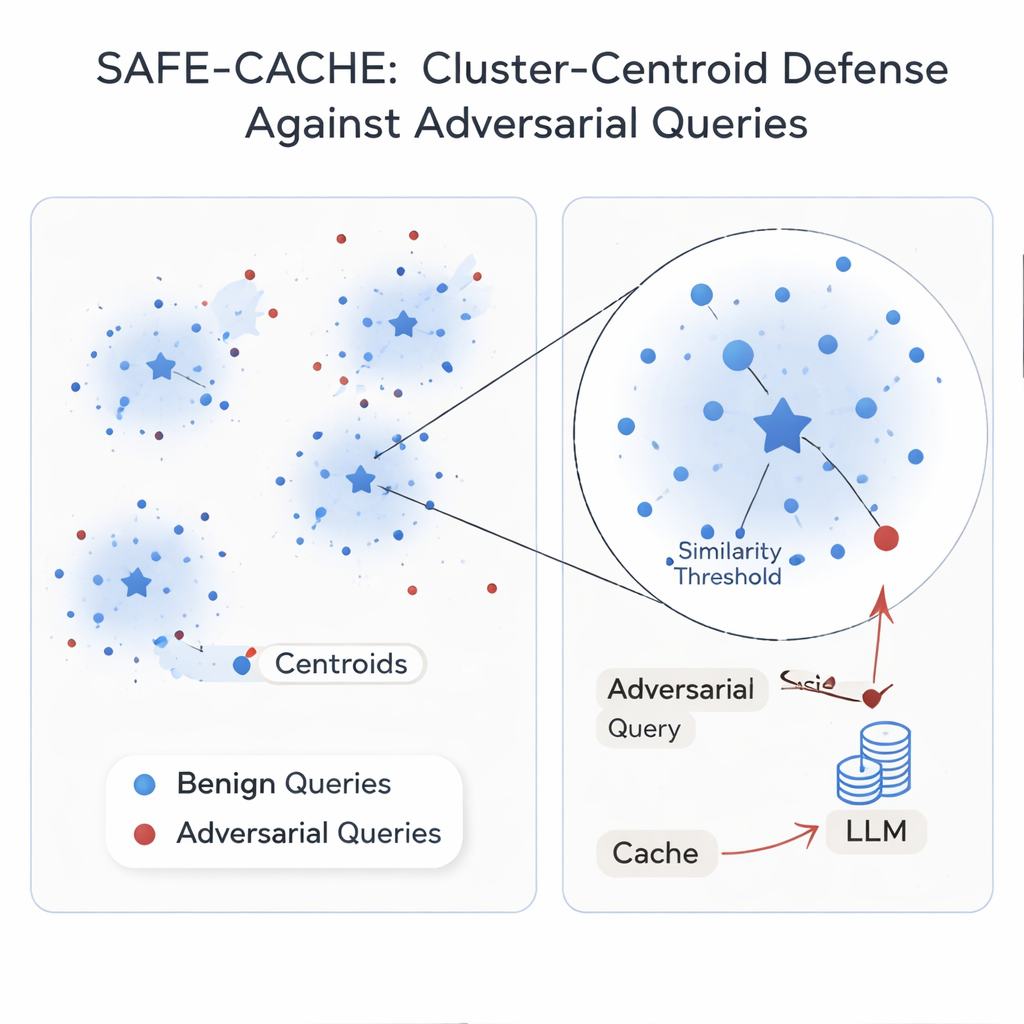
Wat dit betekent voor alledaagse AI-gebruikers
Voor niet-specialisten is de boodschap dat het «geheugen» van AI-systemen niet gratis is: naïeve ontwerpen kunnen geheimen lekken of worden misleid om slechte antwoorden te verspreiden. SAFE-CACHE laat zien dat door geheugen te organiseren rond diepere, intentieniveau-patronen en die patronen te versterken met gerichte parafrasen, het mogelijk is de snelheid- en kostenvoordelen van semantische caching te behouden terwijl het risico op aanvallen scherp wordt verminderd. Nu AI-assistenten de voordeur worden naar gevoelige data — van bedrijfsdossiers tot persoonlijke informatie — zullen benaderingen zoals SAFE-CACHE cruciaal zijn om te zorgen dat wat AI onthoudt niet eenvoudig tegen ons kan worden gebruikt.
Bronvermelding: Afiffy, M., Fakhr, M.W. & Maghraby, F.A. Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems. Sci Rep 16, 5936 (2026). https://doi.org/10.1038/s41598-026-36721-w
Trefwoorden: semantische caching, retrieval-augmented generation, adversaire aanvallen, cluster-gebaseerde verdediging, LLM-beveiliging