Clear Sky Science · nl
Belang van kenmerken-gestuurde autoencoder voor dimensiereductie in indringingsdetectiesystemen
Waarom slimmer cyberverweer ertoe doet
Elke e-mail die u verstuurt, elke video die u streamt en elke aankoop die u doet, reist over netwerken die voortdurend worden aangevallen. Indringingsdetectiesystemen (IDS) fungeren als alarmsystemen voor deze netwerken en signaleren verdacht gedrag voordat het tot een inbreuk leidt. Maar moderne netwerkdata zijn enorm en complex; het doorzoeken van al die details kan systemen vertragen of ertoe leiden dat subtiele aanvallen worden gemist. Dit artikel onderzoekt een nieuwe manier om die data intelligent te verkleinen zodat IDS-tools zowel sneller worden als beter in het opsporen van zelfs zeldzame, moeilijk te ontdekken cyberaanvallen. 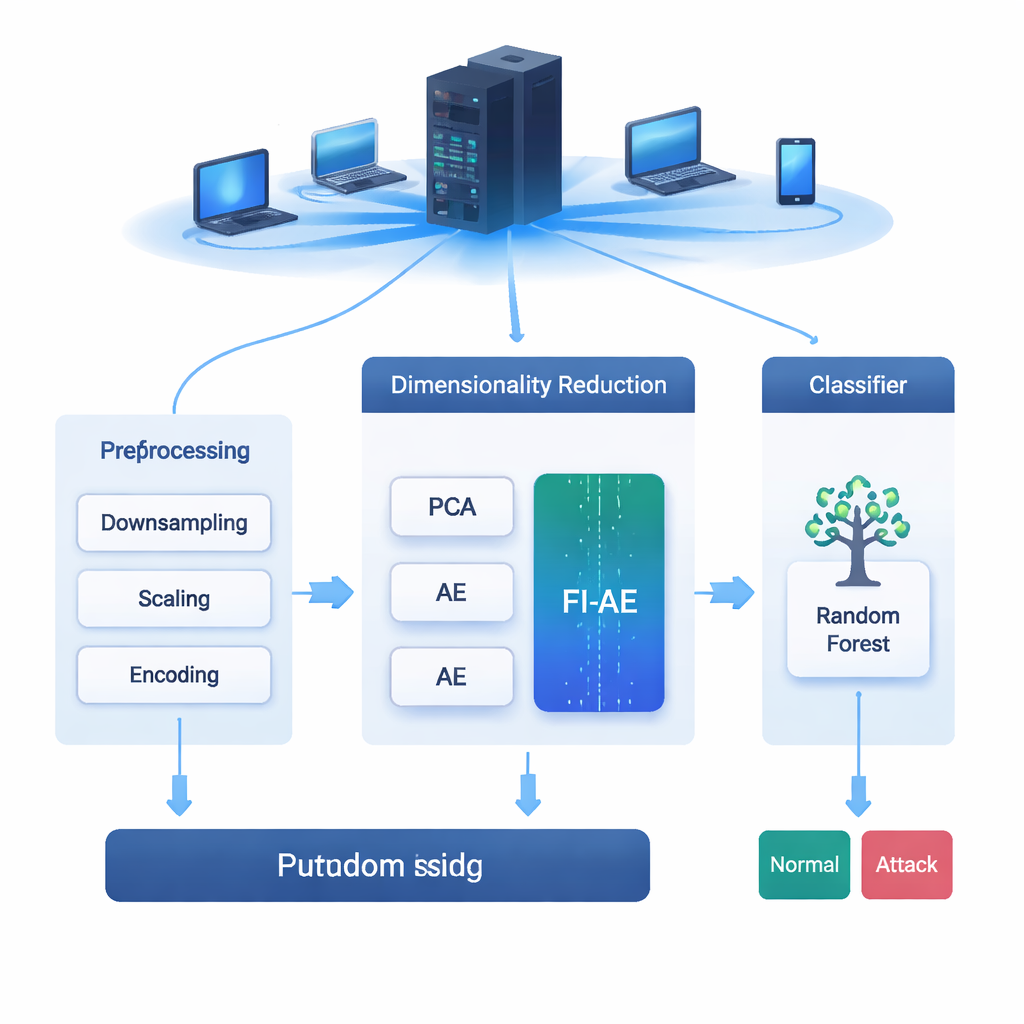
Het probleem van te veel netwerkdata
Netwerkverkeerslogboeken bevatten tientallen tot honderden metingen voor elke verbinding—zoals duur, aantal bytes en foutpercentages. Machine-learning gebaseerde IDS-modellen vertrouwen op deze metingen om te bepalen of verkeer normaal of kwaadaardig is. Het gebruik van alle metingen kan echter de detectie vertragen en soms zelfs de nauwkeurigheid schaden, vooral wanneer sommige aanvallen veel zeldzamer zijn dan andere. Veelgebruikte methoden voor dimensiereductie, zoals hoofdcomponentenanalyse en standaardautoencoders, comprimeren de data maar richten zich vooral op het reconstrueren van het algemene verkeer. Daardoor kunnen ze meer aandacht besteden aan de meerderheid van alledaagse verbindingen en de zwakke, kenmerkende patronen die minder vaak voorkomende aanvalstypen markeren, over het hoofd zien.
Een nieuwe manier om te rangschikken wat echt telt
De auteurs introduceren een kenmerk-rangschikkingsschema dat one-versus-all (OVA) feature importance heet om dit onevenwicht aan te pakken. In plaats van te vragen: “Welke metingen zijn het meest nuttig in het algemeen?”, stelt OVA die vraag afzonderlijk voor elk aanvalstype. Voor elke klasse (bijvoorbeeld normaal verkeer, denial-of-service of wachtwoordpogingen) wordt een random-forestmodel getraind om die klasse te onderscheiden van alle andere. De ingebouwde belangrijkheidsscores van het model tonen vervolgens welke metingen vooral nuttig zijn voor die specifieke klasse. Door dit proces klasse voor klasse te herhalen en vervolgens, voor elke meting, de hoogste belangrijkheid te nemen die het voor enige klasse bereikt, bouwt de methode een enkele gewichtvector die kenmerken benadrukt die van belang zijn voor ten minste één soort aanval—zelfs als die aanval zeldzaam is in de data.
Een autoencoder leren te focussen op sleutel-signalen
Om deze gewichten te gebruiken, ontwerpen de onderzoekers een feature-importance-gebaseerde autoencoder (FI-AE). Net als een conventionele autoencoder comprimeert FI-AE de invoer tot een laag-dimensionele "bottleneck"-representatie en reconstrueert vervolgens de oorspronkelijke data. De wending zit in het trainingsdoel: in plaats van alle reconstructiefouten gelijk te behandelen, gebruikt het model een gewogen mean squared error waarbij de fout van elke feature wordt vermenigvuldigd met zijn OVA-gebaseerde belangrijkheid. Simpel gezegd wordt FI-AE harder gestraft voor het fout weergeven van metingen die cruciaal zijn om aanvallen te onderscheiden, en minder voor minder informatieve details. De architectuur zelf is compact en perst netwerkrecords terug tot slechts 16 getallen, waarbij gebruik wordt gemaakt van standaardtechnieken zoals batchnormalisatie, dropout en de Adam-optimizer om de training stabiel te houden.
De methode op de proef stellen
Het team evalueert FI-AE op drie veelgebruikte indringingsdetectiedatasets: NSL-KDD, UNSW-NB15 en CIC-IDS2017, die samen miljoenen verbindingen en een breed scala aan aanvalstypen omvatten. Voor het trainen maken ze de data schoon door extreem scheve klassenverdelingen te balanceren, numerieke kenmerken te schalen en categorieën te encoderen op een manier die hun relatie met de doellabels behoudt. Ze vergelijken vervolgens drie pijplijnen die allemaal eindigen met een random-forestclassificator: één met PCA, één met een standaardautoencoder en één met FI-AE voor dimensiereductie. Over alle drie datasets levert FI-AE consequent hogere nauwkeurigheid en F1-scores, met bijzonder opmerkelijke winst bij minderheids- en zeldzame aanvallen waar traditionele methoden vaak moeite mee hebben. 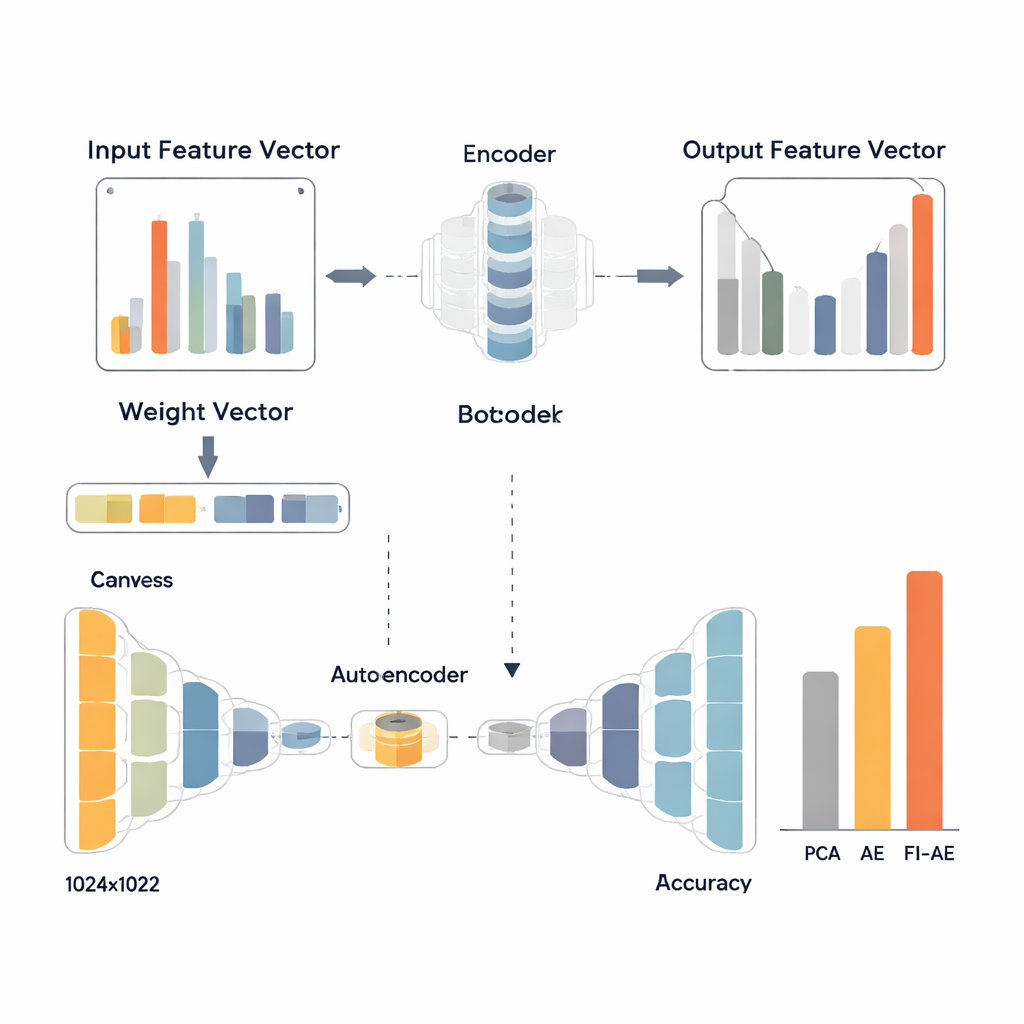
Wat dit betekent voor alledaagse beveiliging
Voor niet-specialisten is de kernboodschap dat dit werk een scherper instrument biedt voor netwerkmonitoring. In plaats van data louter te comprimeren om ze kleiner te maken, leert FI-AE de metingen te behouden die er echt toe doen bij het opsporen van verschillende soorten aanvallen, inclusief de zeldzame die het meest schadelijk kunnen zijn. Met slechts 16 gedistilleerde kenmerken kunnen indringingsdetectiesystemen die op deze aanpak zijn gebouwd efficiënter draaien terwijl ze toch gelijk of beter presteren dan de huidige detectie-standaarden. In de praktijk betekent dit dat beveiligingstools meer verkeer kunnen scannen, sneller kunnen reageren en betere bescherming kunnen bieden voor de digitale diensten waarop mensen dagelijks vertrouwen.
Bronvermelding: Abdel-Rahman, M.A., Alluhaidan, A.S., El-Rahman, S.A. et al. Feature importance guided autoencoder for dimensionality reduction in intrusion detection systems. Sci Rep 16, 5013 (2026). https://doi.org/10.1038/s41598-026-36695-9
Trefwoorden: indringingsdetectie, netwerkbeveiliging, dimensiereductie, autoencoder, belang van kenmerken