Clear Sky Science · nl
Realtime detectie van brand en rook met vision transformers en spatio-temporeel leren
Waarom snellere brandwaarschuwingen ertoe doen
Branden in huizen, fabrieken en bossen kunnen binnen enkele minuten dodelijk worden. Vandaag vertrouwen veel alarmen nog op warmte- of rookmelders die pas reageren nadat vlammen al goed ontwikkeld zijn. Dit artikel beschrijft een nieuw computer-visionsysteem dat in camerabeelden bijna onmiddellijk tekenen van vuur en rook kan herkennen, zelfs onder moeilijke omstandigheden zoals weinig licht of zware nevel. Door meerdere geavanceerde kunstmatige-intelligentietechnieken in één model te combineren, willen de onderzoekers brandweerlieden, stadsplanners en milieuagentschappen veel eerder waarschuwen—waardoor mogelijk levens, eigendommen en ecosystemen worden gered.
De groeiende uitdaging van het detecteren van vlammen
Moderne steden en bossen worden steeds vaker bewaakt met camera’s, maar computers leren om betrouwbaar brand en rook in die beelden te herkennen is lastig. Traditionele benaderingen gebruiken neurale netwerken die goed werken op stilstaande beelden of korte clips, maar ze hebben vaak moeite in rommelige, realistische scènes. Een enkele foto kan iets tonen dat op rook lijkt maar alleen mist of uitlaat is. Video-gebaseerde systemen kunnen volgen hoe vormen zich in de tijd bewegen, maar ze zijn vaak traag en veeleisend qua hardware. Daardoor geven eerdere modellen vaak vals alarm of missen ze subtiele, snel veranderende tekenen van gevaar—vooral bij slecht licht, dichte rook of drukke achtergronden.
Een hybride AI-’wachter’ voor beelden en video
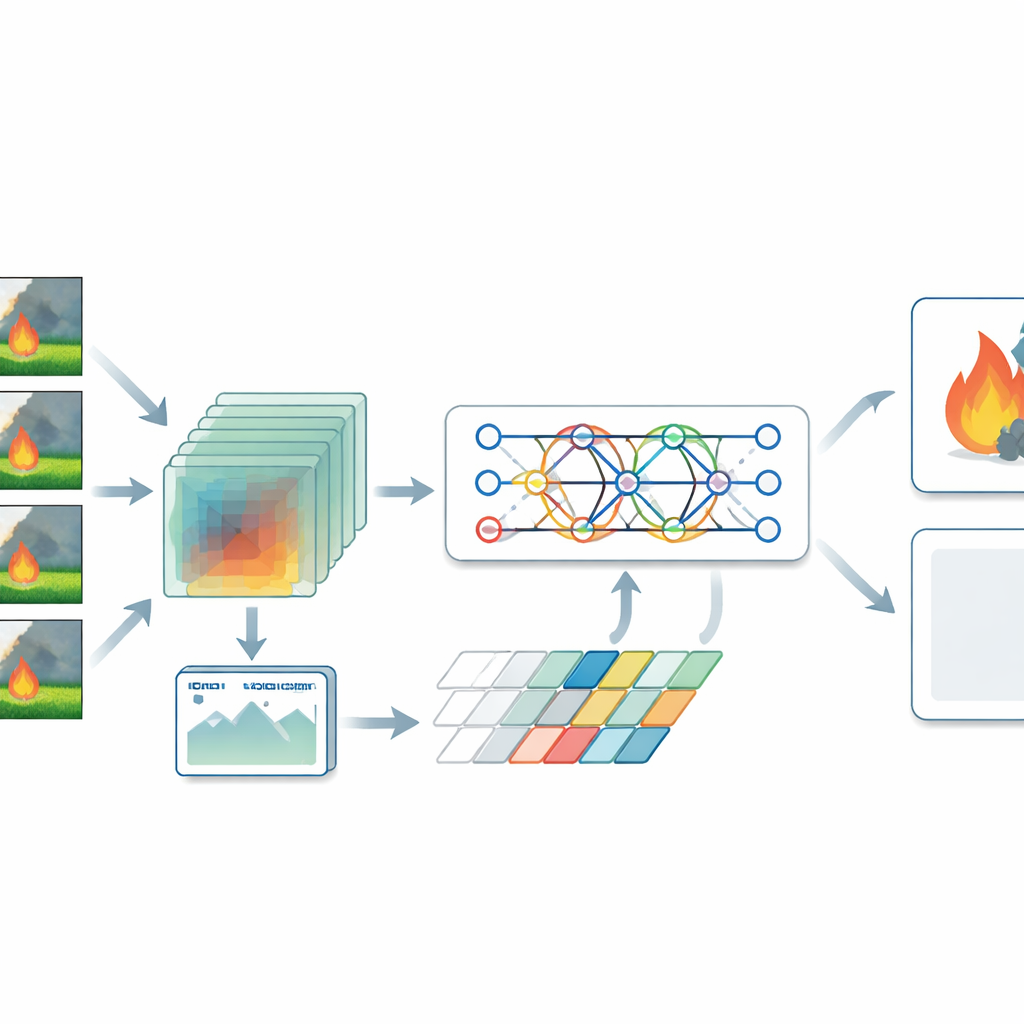
De auteurs stellen een hybride model voor dat branddetectie zowel als een ruimtelijk als een temporeel probleem behandelt. Voor stilstaande beelden gebruiken ze een type neurale netwerk dat een vision transformer wordt genoemd, dat een afbeelding als een lappendeken van gebieden bekijkt en leert hoe verafgelegen delen zich tot elkaar verhouden. Dit helpt het brede patronen op te merken, zoals rooksluieren die over een vallei verspreiden of vlammen die verspreid in een bos staan. Voor video vertrouwt het systeem op een driedimensionaal convolutioneel netwerk dat stapels frames tegelijk verwerkt en vastlegt hoe rook en vuur zich in de tijd veranderen. Een transformer-encoder onderzoekt vervolgens die veranderende patronen en richt de aandacht op de momenten en regio’s die het meest waarschijnlijk op gevaar wijzen, in plaats van elk frame gelijk te behandelen.
Clues combineren en de data balanceren
Een cruciale stap in het systeem is een fusielaag die gedetailleerde aanwijzingen uit stilstaande beelden mengt met bewegingspatronen uit video. Door deze aanvullende gezichtspunten te combineren, kan het model echte branden beter onderscheiden van onschadelijke gelijkenissen zoals zonsondergangglans, mist of wolken. De onderzoekers merkten ook dat veel openbare datasets veel meer brand- dan niet-brandvoorbeelden bevatten, wat een model kan bevoordelen om te vaak vlammen te melden. Om dit tegen te gaan genereerden ze een grote variëteit aan realistische niet-brand scènes via zorgvuldige data-augmentatie—het aanpassen van helderheid, bijsnijden en spiegelen van beelden, en het simuleren van situaties zoals mistige ochtenden of schemerige interieurs. Vervolgens trainden ze het model met een verliesfunctie die expliciet fouten op brand- en niet-brandgevallen in balans brengt, waardoor de betrouwbaarheid in het dagelijks gebruik verbetert.
Het systeem onder de loep
Om te testen hoe goed hun aanpak werkt, hebben de auteurs het systeem getest op twee veelgebruikte datasets: een van bijna duizend stilstaande beelden van de NASA Space Apps Challenge en een andere met brandgerelateerde video’s van Kaggle. Na preprocessing en balancering trainden en evalueerden ze hun hybride model naast bekende basismodellen zoals ResNet, VGG, LSTM, pure 3D-convolutionele netwerken en verschillende hybride combinaties van deze oudere methoden. Het nieuwe systeem bereikte ongeveer 99,2% nauwkeurigheid op de NASA-beelden en 98,3% op de videotdataset, en overtrof daarmee duidelijk de traditionele modellen, die doorgaans tussen midden 80 en midden 90 procent scoorden. Het draaide ook snel genoeg—tientallen milliseconden per frame—en met een bescheiden modelgrootte, waardoor het geschikt is voor inzet op edge-apparaten zoals kleine GPU’s en embedded boards.
Wat dit betekent voor dagelijkse veiligheid
In praktische termen laat dit onderzoek zien dat een doordacht ontworpen AI camerabeelden realtime kan volgen en betrouwbaar een eenvoudige maar wezenlijke vraag kan beantwoorden: “Is er op dit moment hier brand of gevaarlijke rook?” Door brede visuele context, beweging in de tijd en slimme aandacht voor de meest veelzeggende details te combineren, vermindert het hybride model zowel gemiste branden als valse alarmen sterk. Met verdere afstemming en blootstelling aan meer gevarieerde scènes—zoals dichte stedelijke gebieden, ondergrondse ruimten en extreem weer—zou het een praktische ruggengraat kunnen worden voor slimere alarmsystemen, netwerken voor bosbrandbewaking en industriële veiligheidstools die sneller en nauwkeuriger reageren dan veel van de oplossingen van vandaag.
Bronvermelding: Lilhore, U.K., Sharma, Y.K., Venkatachari, K. et al. Real time fire and smoke detection using vision transformers and spatiotemporal learning. Sci Rep 16, 8928 (2026). https://doi.org/10.1038/s41598-026-36687-9
Trefwoorden: branddetectie, rookdetectie, computer vision, transformermodels, realtime monitoring