Clear Sky Science · nl
Klinische validatie van lichtgewicht CNN-architecturen voor betrouwbare meerklassenclassificatie van longkanker met histopathologische beeldvormingstechnieken
Waarom dit onderzoek ertoe doet voor patiënten en artsen
Longkanker is vaak dodelijk omdat het laat wordt ontdekt of verkeerd wordt geclassificeerd, wat de juiste behandeling kan vertragen. Deze studie onderzoekt hoe kleine, efficiënte computerprogramma’s—in plaats van enorme, energie-intensieve modellen—betrouwbaar verschillende typen longkanker kunnen herkennen op microscoopbeelden van weefsel. Als zulke lichtgewicht hulpmiddelen goed werken, kunnen ze in ziekenhuizen wereldwijd worden ingezet, ook in instellingen met beperkte rekenkracht, om pathologen te ondersteunen bij snellere en consistentere diagnoses.
Nauw kijken naar kanker met digitale microscopen
Wanneer een verdachte longknobbel wordt verwijderd of gebiopteerd, onderzoeken pathologen dun gesneden, gekleurde weefselstukken onder een microscoop om te bepalen of het onschadelijk is of tot een van de kankertypen behoort. In dit werk richten de auteurs zich op drie hoofdgroepen: goedaardig longweefsel, longadenocarcinoom en plaveiselcelcarcinoom van de long. Deze subtypen zijn belangrijk omdat ze verschillend reageren op behandelingen. Het team gebruikt digitale snapshots van deze preparaten—histopathologische beelden—en onderzoekt of compacte neurale netwerken de subtiele visuele patronen kunnen leren die elke klasse onderscheiden, van celvormen tot weefselarchitectuur, net zo betrouwbaar als veel grotere modellen.
Kleinere maar slimme digitale klassificeerders bouwen
De meeste state-of-the-art beeldherkenningssystemen zijn zeer omvangrijk en vereisen dure grafische processors, waardoor ze moeilijk in veel klinieken inzetbaar zijn. De onderzoekers ontwerpen daarom vier “lite” beeldanalysemodellen, genoemd Lite-V0, Lite-V1, Lite-V2 en Lite-V4, elk een gestroomlijnde versie van een convolutioneel neuraal netwerk (CNN). Alle vier volgen hetzelfde basisrecept: ze halen geleidelijk visuele kenmerken naar boven via een stapel eenvoudige bouwstenen, samenvatten vervolgens het beeld en geven een van de drie longweefsellabels uit. Wat van versie tot versie verandert, is hoeveel bouwblokken worden gebruikt en hoe breed ze zijn—kortom, hoeveel capaciteit het model heeft om complexe patronen te leren. Dit gecontroleerde ontwerp stelt het team in staat te bestuderen hoeveel complexiteit echt nodig is voor betrouwbare kankersclassificatie.
Trainen, testen en het eerlijkste model kiezen
Om deze modellen te leren en te testen, stellen de auteurs een gebalanceerde verzameling van 15.000 longweefselbeelden samen, zorgvuldig verdeeld in trainings-, validatie- en testgroepen met gelijke aantallen per klasse. Voor het trainen wordt elk beeld van formaat veranderd, genormaliseerd en licht geaugmenteerd met spiegelen, kleine rotaties en zooms om te simuleren hoe preparaten er onder verschillende omstandigheden kunnen uitzien. Cruciaal is dat het team modellen niet alleen beoordeelt op ruwe nauwkeurigheid, omdat die maat slechte prestaties op één klasse kan verbergen. In plaats daarvan gebruiken ze een “macro-F1”-score, die het model dwingt goed te presteren op alle drie weefseltypen, niet alleen de gemakkelijkste. Een aangepaste trainingsprocedure bewaakt deze gebalanceerde score continu en stopt automatisch met trainen wanneer verbeteringen afvlakken, waarbij de beste versie van ieder model wordt opgeslagen voor vergelijking. 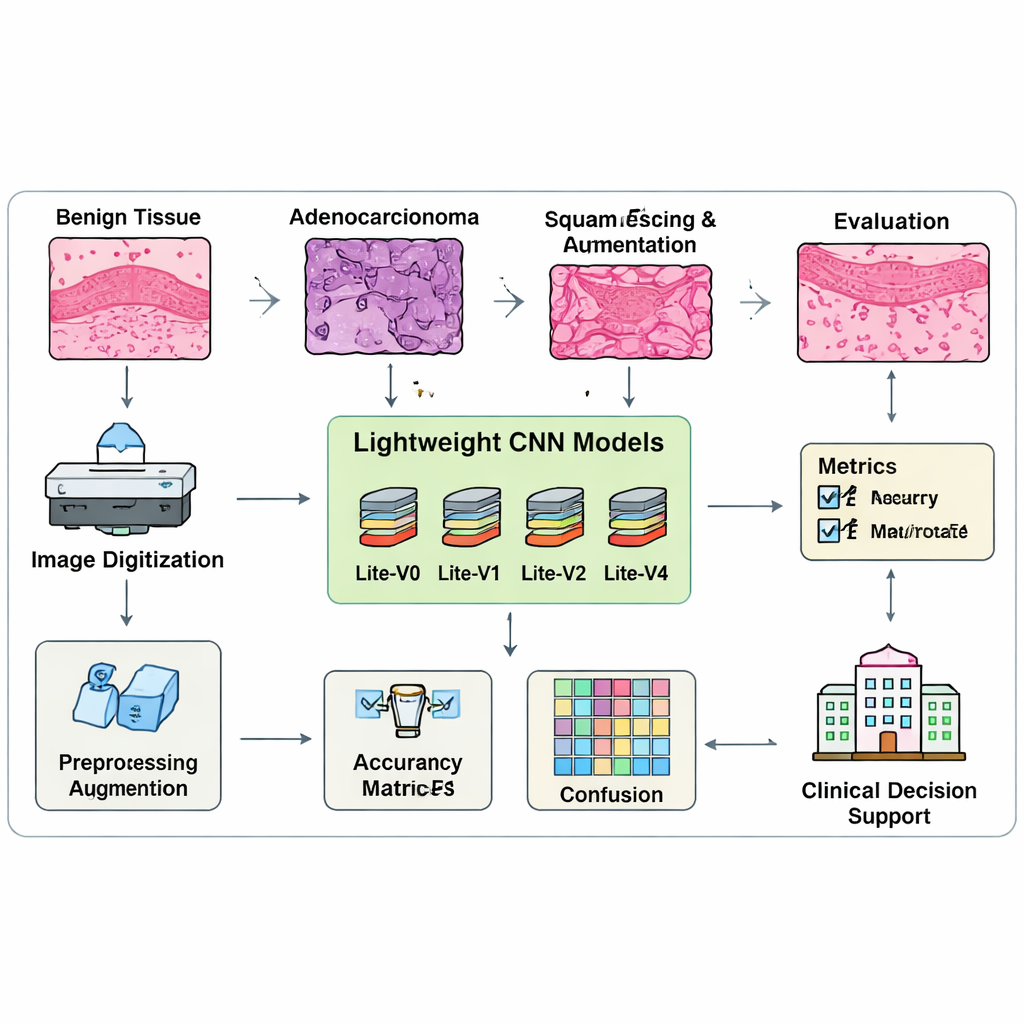
Wat het beste lichtgewicht model echt kan
Wanneer de stof is neergedaald, steekt één variant—Lite-V2—er met kop en schouders bovenuit. Het is niet het kleinste netwerk, noch het grootste, maar zit in het midden en bereikt de beste balans tussen nauwkeurigheid en efficiëntie. Op niet eerder geziene testbeelden classificeert Lite-V2 goedaardig weefsel, adenocarcinoom en plaveiselcelcarcinoom correct met een hoge en gelijkmatig verdeelde prestatie, met een macro-F1-score van ongeveer 0,96. Confusiematrices tonen dat het zelden de drie categorieën door elkaar haalt, terwijl diepere versies beginnen te “overfitten”, waarbij ze de trainingsdata memoriseren maar betrouwbaarheid op nieuwe gevallen verliezen. De auteurs voeren Lite-V2 verder meerdere keren opnieuw uit met verschillende willekeurige startpunten en gebruiken een statistische test om te bevestigen dat het voordeel ten opzichte van de andere varianten geen toevalligheid is. 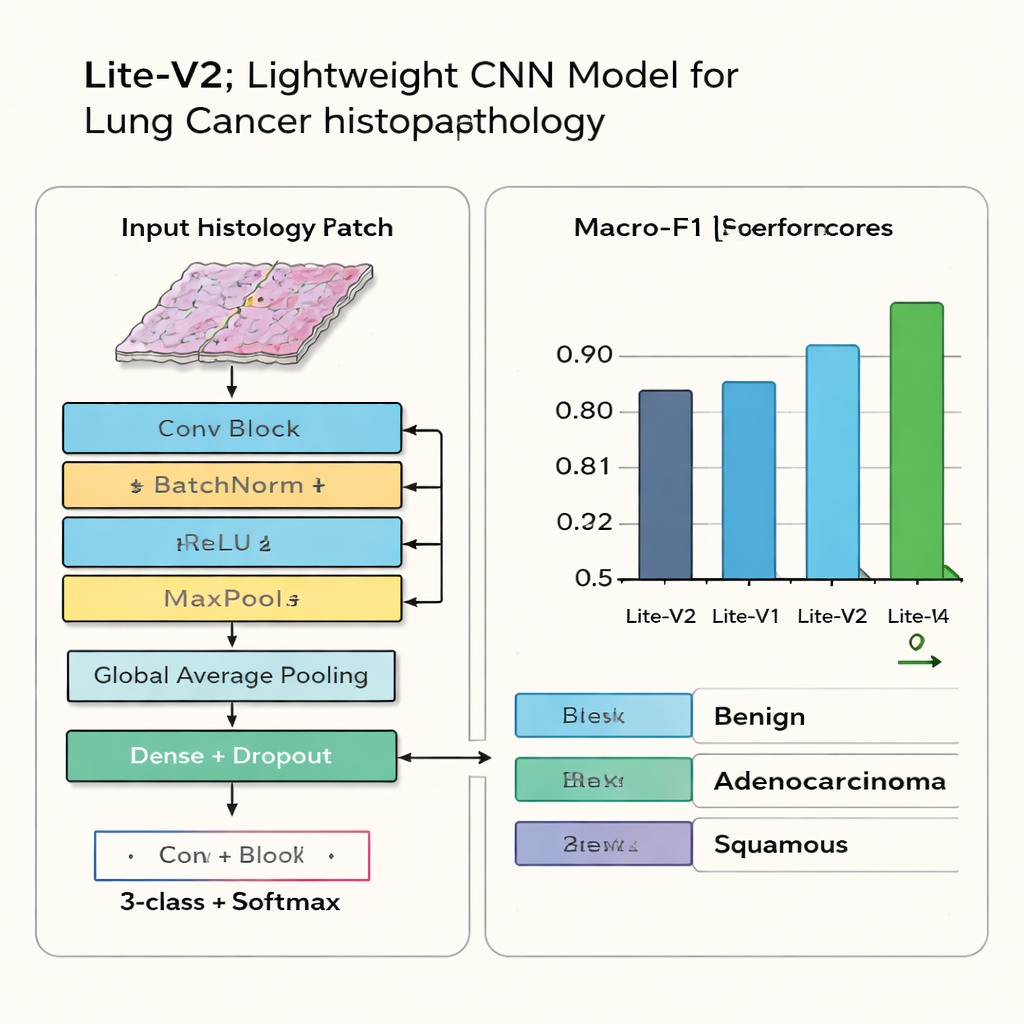
Van onderzoekscode naar praktijkondersteuning
Buiten de prestatiecijfers benadrukt de studie praktische inzetbaarheid. Omdat Lite-V2 en verwante modellen compact zijn, kunnen ze draaien op bescheiden ziekenhuishardware of zelfs edge-apparaten zonder gevoelige beelden naar de cloud te sturen. De auteurs publiceren een reproduceerbaar raamwerk dat elk experimenteel detail vastlegt, van gegevensverwerking tot trainingscurves en foutpatronen, zodat andere teams het werk kunnen verifiëren of uitbreiden. Voor patiënten en clinici is de belangrijkste conclusie dat doordacht ontworpen lichtgewicht AI kan helpen betrouwbare longkankervalidatie dichter bij de dagelijkse pathologiepraktijk te brengen en snellere, consistenter beslissingen kan ondersteunen—zelfs in klinieken zonder geavanceerde rekenkracht.
Bronvermelding: Raza, A., Hanif, F. & Mohammed, H.A. Clinical validation of lightweight CNN architectures for reliable multi-class classification of lung cancer using histopathological imaging techniques. Sci Rep 16, 6512 (2026). https://doi.org/10.1038/s41598-026-36652-6
Trefwoorden: longkanker, histopathologie, convolutionele neurale netwerken, AI voor medische beeldvorming, computerondersteunde diagnose