Op de zeebodem fungeren autonome onderwatervoertuigen als onze ogen en oren voor klimaatonderzoek, inspectie van infrastructuur en zoek‑ en reddingsoperaties. Toch worstelen deze robotduikers met een fundamenteel probleem: duidelijk communiceren en beslissen in een vijandige omgeving waar signalen traag zijn, ruis bevatten en energie schaars is. Dit artikel introduceert een nieuwe methode om onderwaterrobots te helpen communiceren, objecten te detecteren en veilig te blijven door augmented en virtual reality te combineren met een tak van kunstmatige intelligentie genaamd reinforcement learning.
Waarom onderwatercommunicatie zo moeilijk is
Data verzenden onder water is veel moeilijker dan door lucht. Radiogolven, die Wi‑Fi en 5G aandrijven, worden snel door zeewater geabsorbeerd. Akoestische (geluidsgebaseerde) signalen reizen verder maar bieden zeer lage datasnelheden en kunnen vertraging, echo’s of vervorming ondervinden. Magnetische inductie werkt slechts over tientallen meters. Bestaande besturingssystemen voor onderwaterrobots behandelen deze kanalen vaak apart en gebruiken vaste regels voor navigatie en sensoren. Dat maakt hen traag om zich aan te passen wanneer omstandigheden veranderen, verspeelt batterijvermogen en laat communicatielinks kwetsbaar voor afluisteren of aanvallen.
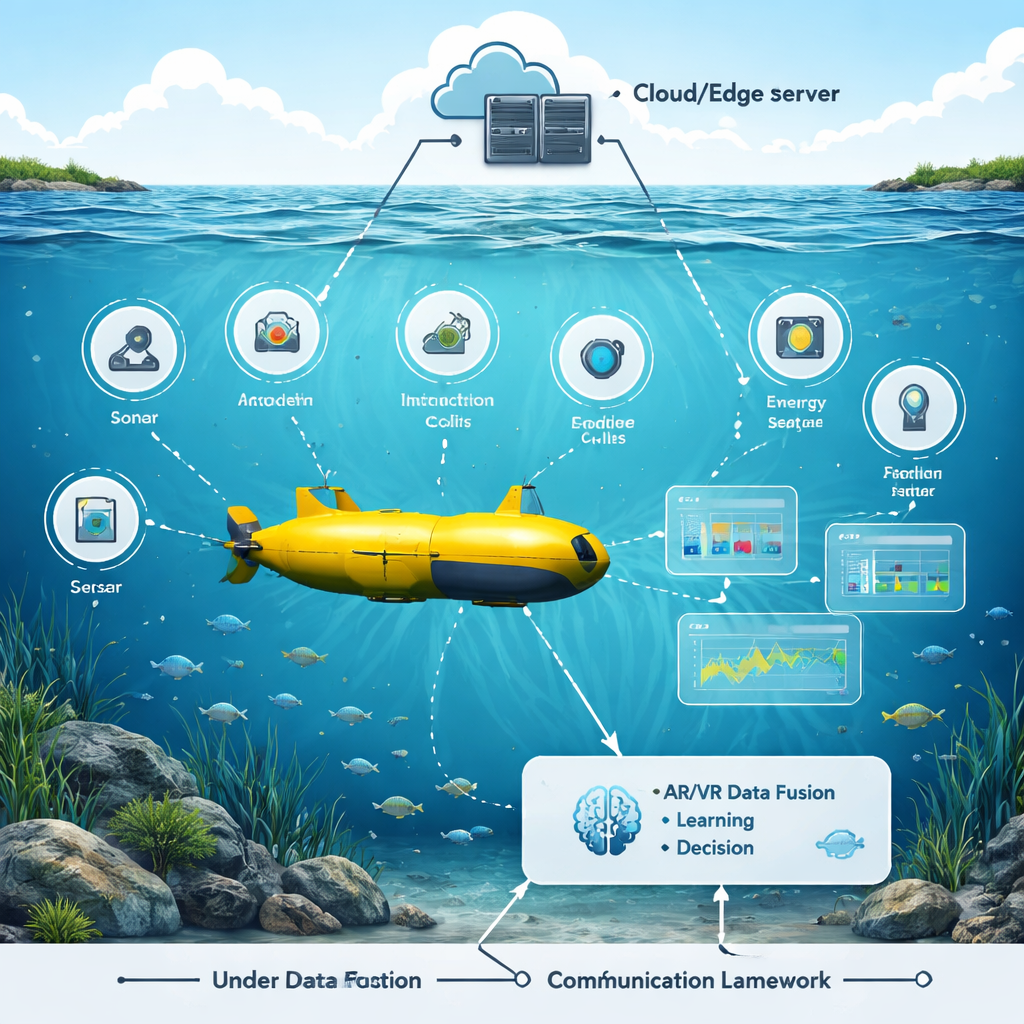
Een virtuele oceaan om betere reflexen te trainen Figuur 1.
De auteurs bouwden een augmented- en virtual-reality testomgeving die een druk onderwaterlandschap nabootst: zwemmende vissen, rotsen, boten en boeien, gecombineerd met realistische ruis en signaalverlies in het water. Een gesimuleerd onderwatervoertuig vaart door deze omgeving met vele sensoren—sonar, camera’s, akoestische modems, energiemeters en positietrackers. In de virtuele scène kunnen onderzoekers schuifregelaars gebruiken om objectposities, watercondities en sensorinstellingen te veranderen en direct te zien hoe de robot reageert. Deze AR/VR-laag is niet alleen visueel; hij verenigt ruwe sensorfeeds in een eenduidig 3D‑beeld dat makkelijker is voor een AI‑systeem om te interpreteren en op te handelen.
De robot leren van ervaring
Centraal in het kader staat een AI‑strategie die de auteurs Adaptive Augmented Reality and Reinforcement Learning Scheduling Strategy (AARLSS) noemen. In plaats van een vast script te volgen leert de robot door proberen en fouten maken in de virtuele oceaan. Elke moment observeert hij zijn gefuseerde sensorstatus, kiest een actie (zoals koerswijziging, aanpassen van de sensoraannamefrequentie of schakelen tussen korte‑ en langeafstandcommunicatie) en ontvangt een beloning. Die beloning balanceert vier doelen: energie besparen, vertraging verminderen, het beveiligingsrisico verlagen en minder reken‑ en netwerkbronnen gebruiken. Een deep Q‑learning netwerk slaat de verwachte waarde van verschillende beslissingen op en werkt die bij, met mini‑batches van eerdere ervaringen bewaard in een replaygeheugen zodat de robot kan leren van zowel recente als oudere situaties.
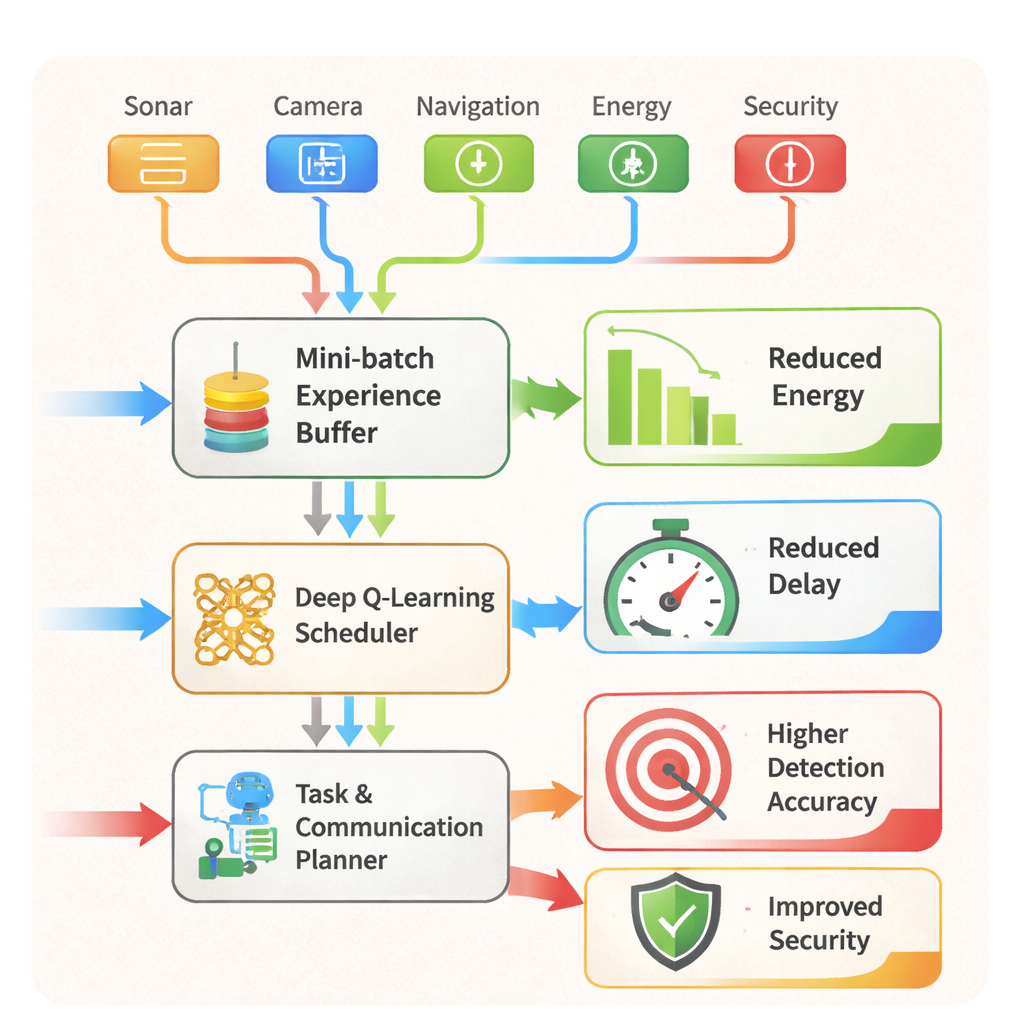
Van slim plannen naar veiligere missies Figuur 2.
AARLSS fungeert ook als realtime planner. Het beslist welke taken—navigatie, objectdetectie, communicatie of beveiligingscontroles—waar en wanneer moeten draaien, en of data op de robot moet worden verwerkt, naar een edge‑server moet worden uitbesteed of vertraagd. Daarbovenop scant een ingebouwd indringingsdetectiesysteem continu patronen in sensor‑ en netwerkdata om anomalieën te signaleren die op een aanval of storing kunnen wijzen, en kan het beschermende acties triggeren zoals het blokkeren van risicovolle verbindingen of het afdwingen van lokaal alleen verwerking. In tests binnen de AR/VR‑simulator overtrof het kader meerdere gevestigde reinforcement‑learning methoden. Het verlaagde het energieverbruik van het onderwatervoertuig met ongeveer 20%, verminderde communicatie‑ en taakvertragingen met circa 18–20% en verhoogde de objectdetectienauwkeurigheid tot ongeveer 97–98%, zelfs tijdens complexe manoeuvres en in drukke scènes.
Wat dit betekent voor echte oceanen
Voor niet‑specialisten is de kernboodschap dat dit onderzoek wijst op onderwaterrobots die onafhankelijker, efficiënter en betrouwbaarder zijn. Door te trainen in een rijke virtuele oceaan en te leren energie, tijd, nauwkeurigheid en veiligheid gelijktijdig te balanceren, kan AARLSS een voertuig laten kiezen wanneer het moet praten, wanneer het moet luisteren en wanneer het stil moet blijven om energie te besparen—terwijl het scherp de omgeving in de gaten houdt en zijn data beschermt. Hoewel deze resultaten uit een geavanceerde simulator komen en niet uit open water, suggereren ze dat toekomstige vloten onderwaterrobots langere, veiligere en datarijkere missies met minder menselijke supervisie zouden kunnen uitvoeren, wat alles verbetert van mariene wetenschap tot offshore inspecties.
Bronvermelding: Lakhan, A., Mohammed, M.A., Ghani, M.K.A. et al. A novel augmented reality and reinforcement learning empowered communication framework for underwater unmanned autonomous vehicle.
Sci Rep16, 6241 (2026). https://doi.org/10.1038/s41598-026-36647-3