Clear Sky Science · nl
Intelligente herkenning van het gedrag van studenten voor slimme leeromgevingen
Waarom slimme klaslokalen moeten zien wat studenten doen
In veel klaslokalen moeten docenten raden wie opletten, wie de draad kwijt is en wie stilletjes niet met de les bezig is. Dit artikel onderzoekt hoe kunstmatige intelligentie automatisch kan herkennen wat studenten doen — zoals lezen, schrijven of hun hand opsteken — op gewone foto’s uit het klaslokaal. Door ruwe beelden om te zetten in betrouwbare maten voor klaslokaalactiviteit, wil het systeem docenten realtime feedback geven over betrokkenheid zonder te vertrouwen op tijdrovende observatie of indringende monitoring.
Van rommelige foto’s naar gerichte fragmenten
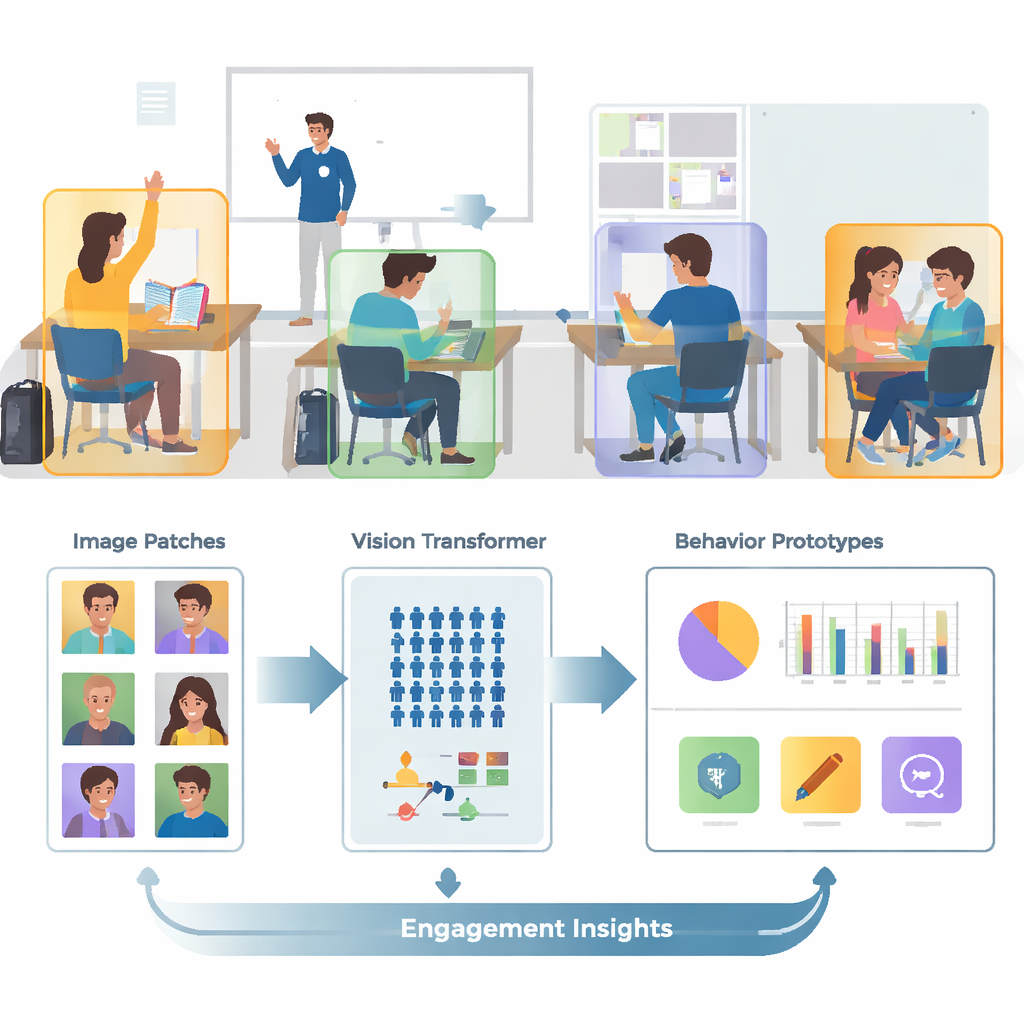
Werkelijke klaslokalen zijn vol, druk en visueel verwarrend. Een enkele foto kan tientallen studenten bevatten, overlappende lichamen en afleidende achtergronddetails zoals wanden, schermen en posters. De auteurs bouwen voort op een openbare beeldverzameling genaamd SCB‑05, die duizenden klaslokaalfoto’s bevat met labels voor specifieke gedragingen — zoals hand opsteken, lezen, schrijven, staan, praten of interactie bij het schoolbord. In plaats van hele scènes aan de computer te voeren, gebruikt het systeem eerst annotatiebestanden om alleen de regio’s rond elke student of docent uit te knippen. Deze voorbewerking verwijdert veel visuele rommel, zodat het model zich kan concentreren op houding, handpositie en andere aanwijzingen die het ene gedrag van het andere onderscheiden.
Hoe de AI nieuwe gedragingen leert van zeer weinig voorbeelden
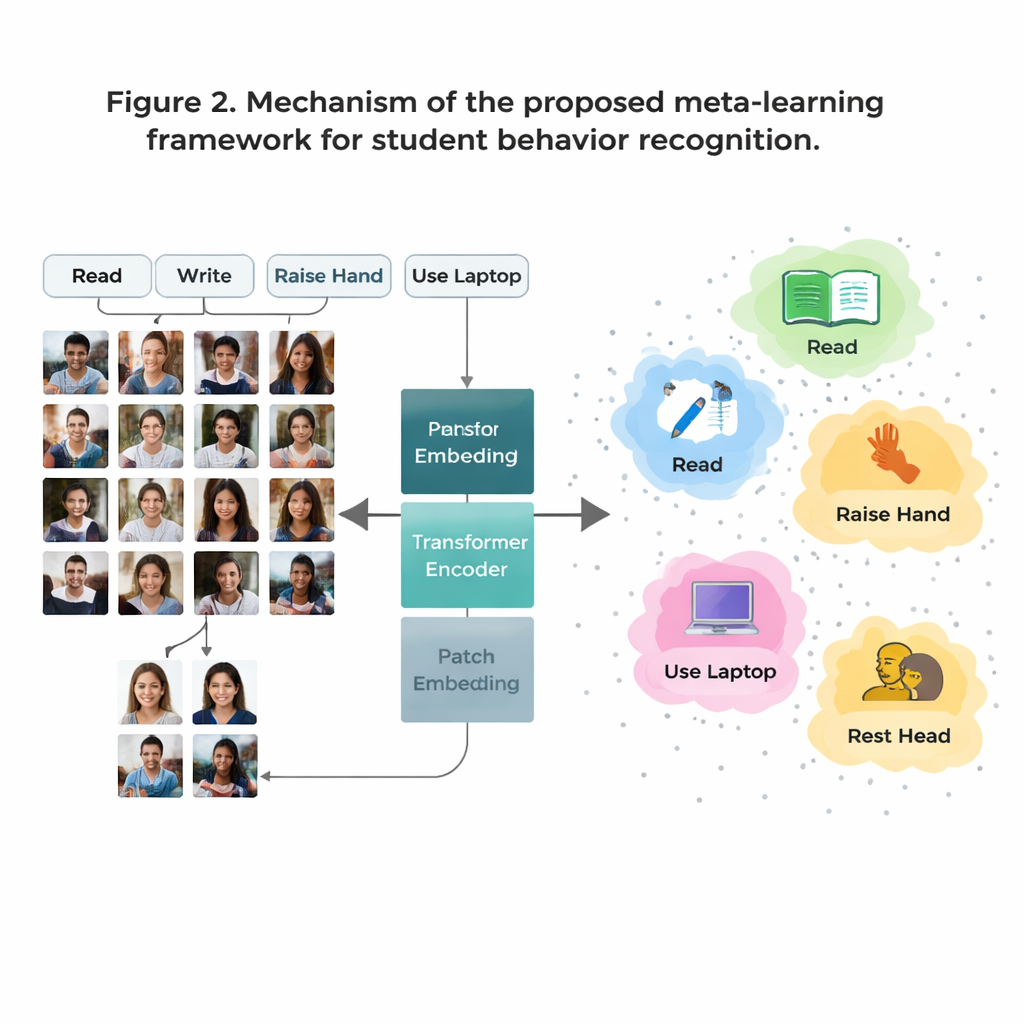
Een grote uitdaging is dat sommige klaslokaalgedragingen veel voorkomen in de data (zoals lezen) terwijl andere zeldzaam zijn (zoals korte interacties op het podium). Genoeg gelabelde afbeeldingen verzamelen voor elk mogelijk gedrag is duur en roept privacyvragen op. Om dit te omzeilen gebruiken de auteurs een strategie genaamd "few‑shot learning", waarbij het model wordt getraind om nieuwe klassen te herkennen aan slechts een handvol voorbeelden. Ze organiseren de training als veel kleine taken, elk met slechts een paar gedragingen en een paar voorbeeldafbeeldingen per gedrag. Voor elke taak vormt het systeem een eenvoudig "prototype" voor elk gedrag door de interne representaties van die voorbeelden te middelen. Nieuwe afbeeldingen worden vervolgens geclassificeerd door te bepalen bij welk prototype ze het dichtst in de buurt liggen, waardoor het model zich snel kan aanpassen, zelfs wanneer data schaars zijn.
Het hele klaslokaal zien, niet alleen kleine details
Traditionele beeldsystemen, zogenaamde convolutionele neurale netwerken, richten zich vaak op kleine lokale patronen, zoals randen of texturen. Dat kan beperkend zijn wanneer twee gedragingen, zoals lezen en schrijven, van dichtbij erg op elkaar lijken. Dit werk vervangt die oudere netwerken door een Vision Transformer, een model dat elke afbeelding in patches verdeelt en leert hoe alle patches zich tot elkaar verhouden. Dit globale perspectief helpt het systeem subtiele houdingsverschillen en langafstandssignalen te begrijpen — zoals de relatie tussen een opgeheven hand en een docent voorin het lokaal. Het team verfijnt het model verder door het te trainen om afbeeldingen van hetzelfde gedrag bij elkaar te trekken terwijl het vergelijkbare maar verschillende gedragingen uit elkaar duwt, met extra nadruk op moeilijk verwarrende gevallen. Dit maakt de interne kaart van gedragingen overzichtelijker en gemakkelijker te scheiden.
Hoe goed het werkt en waarom het ertoe doet
Op de SCB‑05 benchmark bereikt de voorgestelde methode ongeveer 91% overall nauwkeurigheid en sterke scores op zwaardere maten die rekening houden met ongelijke data. Veelvoorkomende gedragingen zoals lezen en hand opsteken worden bijzonder goed herkend, terwijl zeldzamere gedragingen zoals schrijven op het schoolbord uitdagender blijven maar nog steeds beter presteren dan bij eerdere systemen. Visuele inspecties van de interne clusters van het model tonen aan dat verschillende gedragingen strakke, goed gescheiden groepen vormen, wat aangeeft dat de AI onderscheidende "handtekeningen" van klaslokaalacties heeft geleerd. Getest op een andere dataset met nieuwe camerahoeken en indelingen daalde de prestatie slechts licht, wat suggereert dat de geleerde representatie niet aan één specifieke ruimte of school is gebonden.
Wat dit betekent voor onderwijs en leren
Simpel gezegd laat de studie zien dat computers veel belangrijke studentengedragingen uit stilstaande beelden betrouwbaar kunnen opsporen, zelfs wanneer ze van elk gedrag slechts enkele voorbeelden hebben gezien. In plaats van docenten te vervangen, kunnen zulke systemen stilletjes samenvatten wie betrokken is, wie vaak hulp zoekt of welke activiteiten de aandacht doen verslappen — allemaal zonder studentidentiteiten te volgen. Met verdere inspanningen op het gebied van privacy, eerlijkheid en videoanalyse over tijd kan dit soort gedragsbewuste AI een krachtige bondgenoot worden voor docenten die responsievere en inclusievere leeromgevingen ontwerpen.
Bronvermelding: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
Trefwoorden: slimme klaslokaal, studentengedrag, computer vision, few-shot learning, vision transformer