Clear Sky Science · nl
Cross-domain continuous-scale remote sensing image super-resolution via meta-weight learning
Scherper zicht vanuit de ruimte
Satellietbeelden vormen de basis voor alles van stedelijke planning tot hulp bij rampen, maar veel foto’s zijn minder scherp dan gewenst door beperkingen in camerahardware en datatransmissie. Deze paper presenteert een nieuwe methode om vage satellietfoto’s bij elk gewenst zoomniveau scherper te maken, met een leerstrategie die zich kan aanpassen aan het specifieke uiterlijk van luchtbeelden zonder voor elke situatie opnieuw te hoeven worden getraind.
Waarom scherpere satellietbeelden belangrijk zijn
Hoge-resolutie remote sensing-beelden zijn cruciaal om kleine objecten te detecteren, veranderingen op de grond te volgen en landgebruik in detail in kaart te brengen. In de praktijk moeten satellieten echter een afweging maken tussen resolutie, kosten, sensorformaat en bandbreedte, waardoor veel beelden van lagere kwaliteit zijn dan analisten zouden willen. Traditionele "super-resolutie"-technieken kunnen beelden verscherpen, maar zijn meestal getraind voor een vaste vergroting, bijvoorbeeld precies twee- of viermaal. Dat betekent dat operators voor elk zoomniveau aparte modellen nodig hebben, wat ondoelmatig en inflexibel is bij het omgaan met veel satellieten en uiteenlopende taken.
Meer dan één-formatie-voor-alle zoom
Recente onderzoeken hebben "continuous-scale" super-resolutie ontwikkeld, waarbij een beeld wordt gezien als een glad signaal en een enkel model scherpe resultaten kan genereren voor elk zoomfactor. De meeste van deze methoden zijn echter ontwikkeld en getest op alledaagse foto’s, niet op satellietdata. Ze bepalen doorgaans hoe nabije pixelinformatie moet worden gemengd met vaste geometrische regels—in essentie door buren te wegen op afstand. Dat werkt redelijk goed voor natuurlijke scènes zoals gezichten of landschappen, maar satellietbeelden bevatten dichte bebouwing, repetitieve texturen en abrupte randen die niet dezelfde patronen volgen. Wanneer modellen die op natuurlijke foto’s zijn getraind op satellietbeelden worden toegepast, werken hun veronderstellingen niet meer en worden details zoals daken, wegen en voertuigen niet betrouwbaar hersteld.
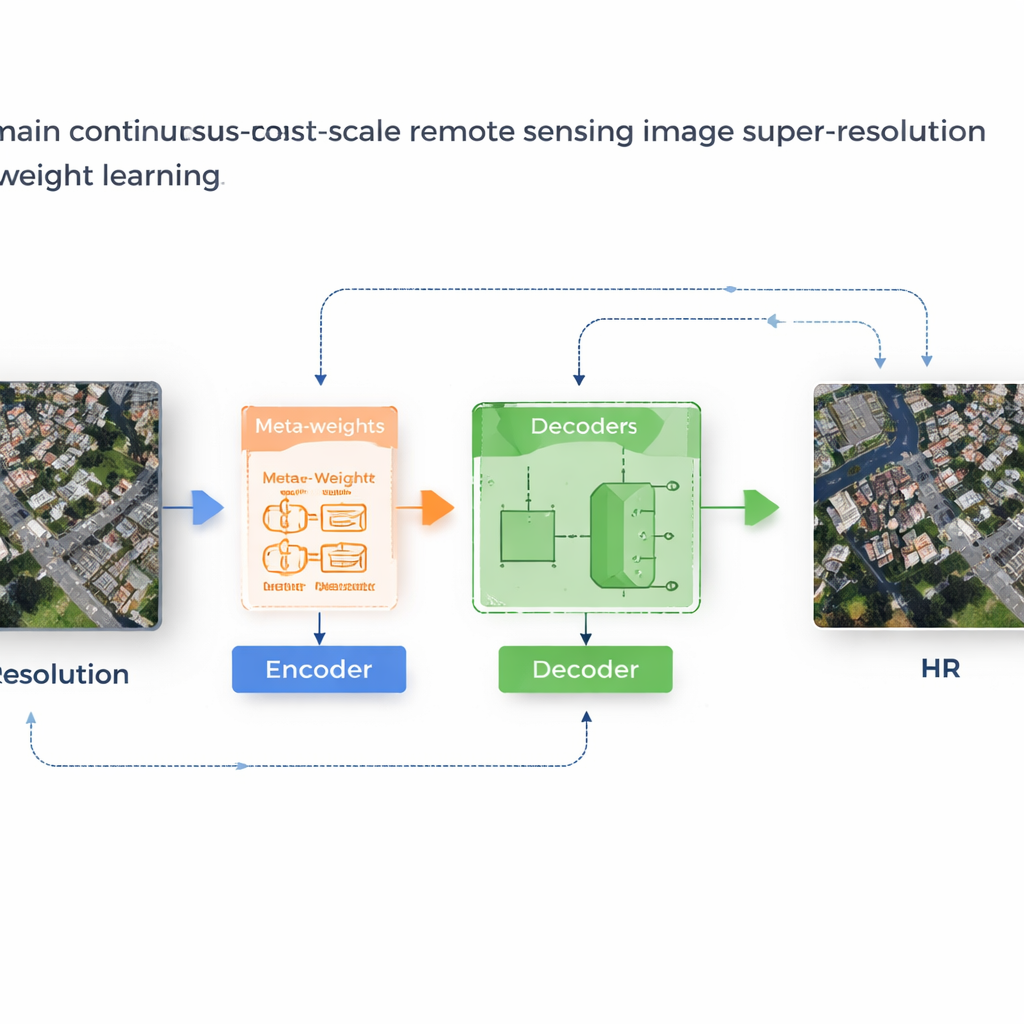
Een leersysteem dat zijn eigen regels aanpast
De auteurs stellen een raamwerk voor genaamd MLIN (Meta-Learning-based Implicit Neural Network) om dit cross-domain probleem aan te pakken. In plaats van handmatig te bepalen hoe nabije pixelfeatures gecombineerd moeten worden, leert MLIN deze combinatieregels uit data. Het behoudt een krachtig image-encoder die oorspronkelijk op natuurlijke foto’s is getraind volledig bevroren, zodat die rijke visuele patronen kan blijven extraheren zonder vervormd te raken door de kleinere satellietdatasets. Daarbovenop voegt MLIN een nieuwe "implicit decoder" toe die is uitgerust met een meta-learningmodule. Voor elk punt in het hoogresolutiebeeld dat het model wil reconstrueren, bekijkt deze module de omringende features en hun precieze posities en voorspelt vervolgens een set zachte gewichten die de decoder aangeven hoe sterk elke buur moet bijdragen. Met andere woorden, het systeem veronderstelt niet langer dat alleen afstand telt; het laat lokale inhoud—zoals texturen van daken, velden of water—de reconstructie sturen.
Van vage blokken naar scherpe structuren
Technisch werkt de methode door voor elke doelpositie in de output een kleine 2×2 buurt van verborgen features te sampelen. Een meta-netwerk combineert vervolgens informatie over deze features, hun relatieve coördinaten en de gevraagde zoomfactor om gewichten te kiezen die optellen tot één. De decoder gebruikt deze gewichten om voorspellingen van elke buur te mengen en zo een uiteindelijke kleurwaarde op die locatie te produceren. Omdat deze weging geleerd wordt, kan MLIN complexe gebieden—zoals dichtbebouwde woonblokken, havens met schepen of luchthavens met start- en landingsbanen—heel anders behandelen dan vlakke gebieden zoals woestijnen of oceanen. Experimenten op twee veelgebruikte satellietdatasets (WHU-RS19 en UCMerced) laten zien dat MLIN consequent hogere numerieke kwaliteitscores en visueel scherpere details levert dan verschillende toonaangevende continuous-zoom-methoden, zowel bij bekende zoomniveaus als bij extreme vergrotingen tot wel tien keer.
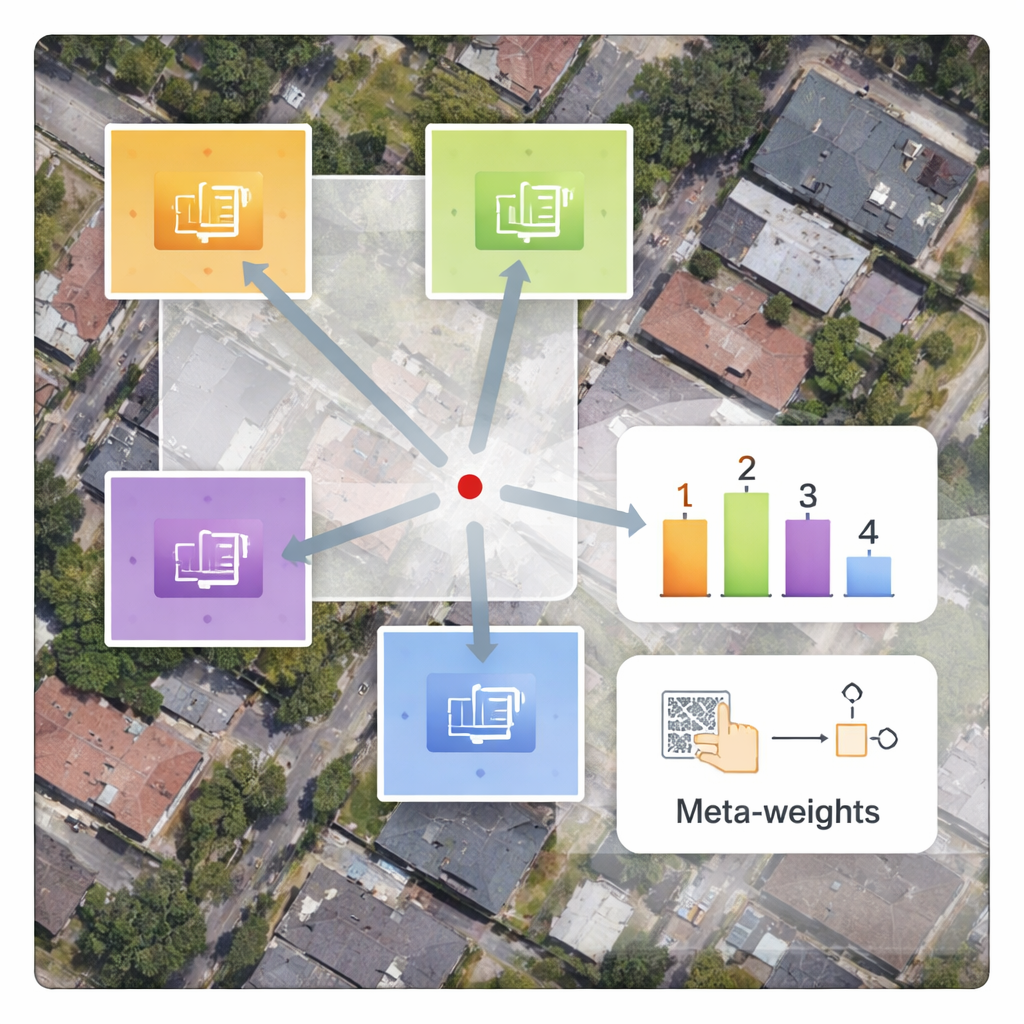
Snelder trainen zonder extra vertraging
Een praktisch voordeel van het ontwerp is dat alleen de nieuwe decoder en het meta-weight netwerk op satellietbeelden hoeven te worden getraind, terwijl de grote encoder vast blijft. Dit vermindert de trainingstijd aanzienlijk vergeleken met methoden die alle parameters vanaf nul opnieuw trainen. Hoewel het meta-netwerk extra rekenwerk introduceert, verwerken moderne grafische processors deze bewerkingen efficiënt, zodat de tijd om een enkel beeld te verwerken vrijwel gelijk blijft aan bestaande benaderingen. Ablatieonderzoek—zorgvuldig testen waarbij onderdelen van het systeem worden verwijderd of vereenvoudigd—bevestigt dat de content-aware weging het sleutelbestanddeel is dat zowel randverscherping als textuurcontinuïteit verbetert.
Heldere ogen op aarde
Simpel gezegd laat dit werk zien hoe krachtige beeldmodellen die op alledaagse foto’s zijn getraind opnieuw gebruikt en slim aangepast kunnen worden aan de heel andere wereld van satellietbeelden. Door het systeem te laten leren hoe informatie van nabije pixels te wegen op basis van wat er daadwerkelijk in de scène staat, produceert MLIN helderdere, betrouwbaardere satellietbeelden op elk zoomniveau met één enkel model. Dat betekent betere hulpmiddelen voor wetenschappers, planners en hulpverleners die afhankelijk zijn van gedetailleerde beelden van onze planeet, terwijl de rekencapaciteit en opslagbehoefte beheersbaar blijven.
Bronvermelding: Zhang, Q., Ma, S., Tang, Y. et al. Cross-domain continuous-scale remote sensing image super-resolution via meta-weight learning. Sci Rep 16, 6073 (2026). https://doi.org/10.1038/s41598-026-36632-w
Trefwoorden: satellite super-resolution, remote sensing imagery, meta-learning, arbitrary-scale zoom, image enhancement