Clear Sky Science · nl
Fijnmazige evaluatie van grote taalmodellen in de geneeskunde met niet-parametrische cognitieve diagnostische modellering
Waarom dit belangrijk is voor toekomstige doktersbezoeken
Kunstmatige-intelligentiesystemen die spreken en schrijven, bekend als grote taalmodellen, verplaatsen zich snel van onderzoeksinstituten naar ziekenhuizen. Ze kunnen artsen al helpen met het lezen van complexe dossiers, behandelingen voorstellen en medische vragen beantwoorden. Maar de meeste tests van deze systemen geven slechts één enkele totaalscore, vergelijkbaar met een eindexamencijfer, wat gevaarlijke blinde vlekken kan verbergen. Deze studie laat een nieuwe manier zien om die scores te doorgronden en precies te onthullen op welke medische terreinen deze modellen écht inzicht hebben — en waar ze nog steeds een risico voor patiënten kunnen vormen.
Voorbij één enkele testscore kijken
Vandaag de dag wordt medische AI meestal beoordeeld op hoeveel vragen ze correct beantwoordt op examens die gemodelleerd zijn naar dokterslicentieproeven. Die aanpak is eenvoudig maar grof. Een model kan een hoge totaalscore behalen en toch zwak zijn op een kritiek terrein zoals hartritmeanalyse of leverziekten. In echte klinische situaties kunnen zulke lacunes levensbedreigende consequenties hebben. De auteurs stellen dat veilig gebruik van AI in de geneeskunde een diepgaandere, fijnermazige evaluatie vereist — een evaluatie die een gedetailleerd vaardigheidsprofiel in kaart brengt in plaats van één mogelijk misleidend cijfer uit te delen.

Een slimmer manier om medische kennis te testen
Om dit te bereiken lenen de onderzoekers instrumenten uit de onderwijskunde, genaamd cognitieve diagnostische beoordeling. In plaats van elke examenvraag te behandelen alsof die dezelfde vage vaardigheid meet, splitst deze methode medische kennis op in specifieke bouwstenen, zoals cardiologie, radiologie of spoedeisende zorg. Elke meerkeuzevraag wordt getagd met de exacte mix van vaardigheden die daarvoor nodig is. Met behulp van een niet-parametrische statistische techniek vergelijkt het team hoe een model duizenden van zulke vragen beantwoordt met ideale responsprofielen. Daaruit leiden ze af of het model elke onderliggende vaardigheid ‘beheerst’, vergelijkbaar met een gedetailleerd rapportcijfer dat sterktes en zwaktes per vak toont.
41 AI-modellen een medische toets laten maken
Het team testte 41 veelgebruikte taalmodellen, inclusief commerciële systemen en open-sourcemodellen, op 2.809 zorgvuldig gecontroleerde vragen uit een Chinese nationale medische toetsbank. Deze vragen bestrijken 22 medische subdomeinen en zijn bedoeld voor studenten die op het punt staan hun artsenexamen af te leggen. Elke vraag heeft één correct antwoord en is door experts gelabeld om aan te geven welke specialismen eraan raken. Met hun diagnostische methode schatten de onderzoekers voor elk model in hoeveel van deze 22 medische attributen het effectief meester was, niet alleen hoeveel vragen het toevallig goed had beantwoord.
Sterke algemene kennis, maar scherpe blinde vlekken
De resultaten zijn zowel indrukwekkend als zorgwekkend. De best presterende modellen, zoals enkele toonaangevende commerciële systemen, beantwoordden de meeste vragen correct en toonden beheersing van 20 van de 22 medische domeinen. Over alle modellen heen was de prestatie uitstekend in veel voorkomende specialismen, met volledige beheersing in 15 gebieden waaronder cardiologie, dermatologie en endocrinologie. Toch bracht de fijnmazige analyse forse lacunes in andere gebieden aan het licht. Radiologie bleef duidelijk achter met veel lagere beheersingspercentages, en twee subdomeinen — ECG & hypertensie & lipiden en leveraandoeningen — werden door geen enkel model beheerst. Belangrijk is dat sommige kleinere modellen dezelfde beheersde vaardigheden toonden als veel grotere modellen, wat aangeeft dat pure grootte geen garantie is voor brede, betrouwbare medische kennis.
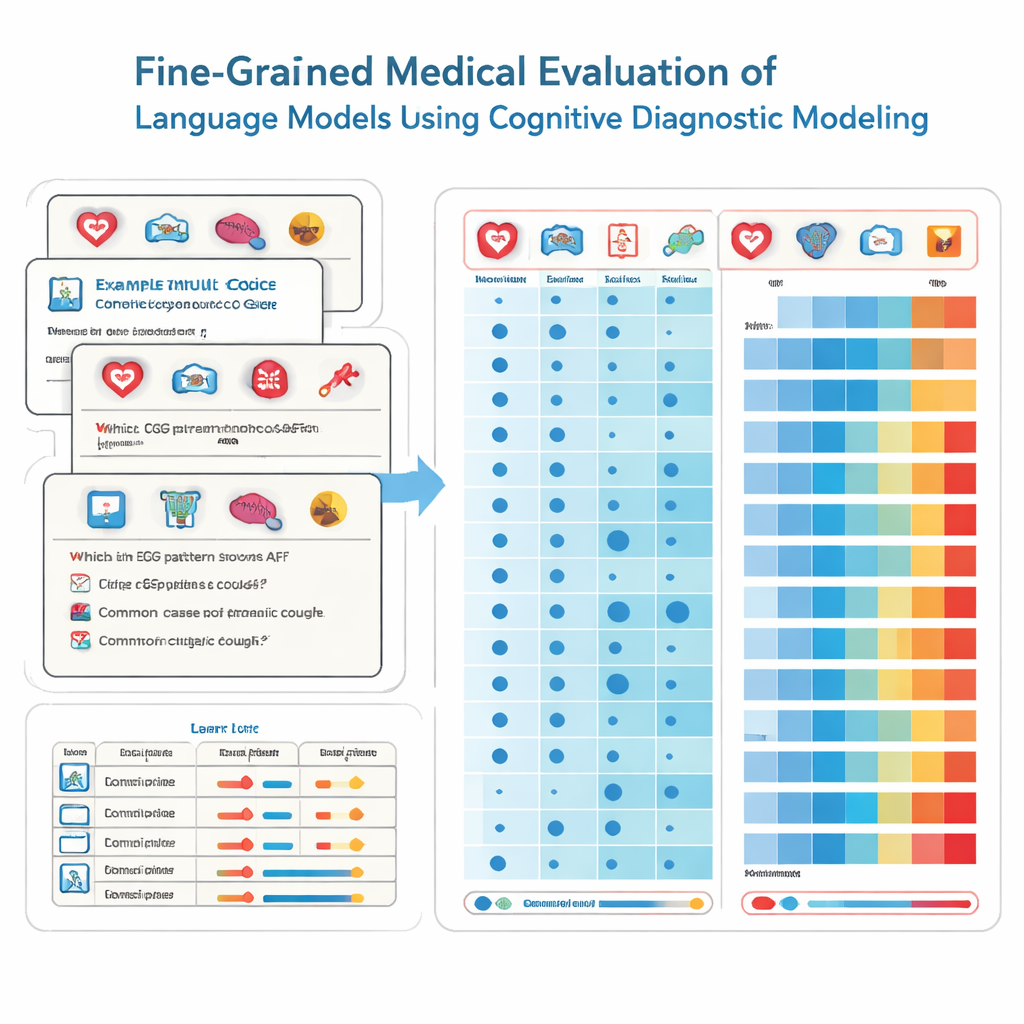
Het juiste hulpmiddel voor de juiste taak kiezen
Deze gedetailleerde profielen zijn van belang omdat modellen met zeer vergelijkbare totaalscores sterk verschillende patronen van sterktes en zwaktes kunnen hebben. Het ene systeem kan sterk zijn in neurologie maar zwak in farmacologie, terwijl een ander het omgekeerde laat zien. Voor ziekenhuisbestuurders betekent dit dat ze niet veilig een AI-assistent kunnen kiezen op basis van alleen het kopscore of het aantal parameters. In plaats daarvan hebben ze diagnostische resultaten zoals in deze studie nodig om elk model aan specifieke klinische taken te koppelen en om workflows te ontwerpen waarbij menselijke specialisten AI-uitvoer controleren op hoogrisicogebieden waar het model zwak blijkt te zijn.
Wat dit betekent voor patiënten en clinici
Kort gezegd concluderen de onderzoekers dat een hoog ‘cijfer’ op medische toetsen niet garandeert dat een AI-systeem veilig is in alle onderdelen van de geneeskunde. De nieuwe aanpak werkt eerder als een grondige gezondheidscontrole voor de AI zelf, door te onthullen welke ‘organen’ — in dit geval medische specialismen — gezond zijn en welke aandacht behoeven. Door verborgen lacunes in kritieke gebieden zoals ECG-interpretatie en leverziekten aan het licht te brengen, biedt de methode ziekenhuizen, toezichthouders en ontwikkelaars een praktisch stappenplan: gebruik modellen alleen waar ze bewezen sterk zijn, houd mensen stevig in de lus waar zwaktes blijven bestaan, en richt toekomstige training op de meest risicovolle blinde vlekken. Deze vorm van fijnmazige evaluatie, zo betogen de auteurs, is niet alleen nuttig — ze is essentieel voordat men AI aan patiëntenzorg toevertrouwt.
Bronvermelding: Zheng, T., Liu, J., Feng, S. et al. Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling. Sci Rep 16, 6460 (2026). https://doi.org/10.1038/s41598-026-36627-7
Trefwoorden: medische AI, grote taalmodellen, klinische veiligheid, modelevaluatie, diagnostische tests