Clear Sky Science · nl
Multitaskoptimalisatie en convergentiestabiliteit met hiërarchisch feature‑leren voor zelfgestuurde optimalisatie
Slimmere AI die meerdere taken tegelijk kan uitvoeren
Moderne toepassingen vertrouwen steeds vaker op kunstmatige intelligentie die meerdere dingen tegelijk moet doen — zoals beeld en tekst gezamenlijk begrijpen, medische beslissingen ondersteunen of voertuigen helpen de weg waar te nemen. Maar wanneer één AI‑model te veel vaardigheden tegelijk leert, kan het trainingsproces instabiel worden en kunnen de vaardigheden elkaar in de weg zitten. Dit artikel introduceert een nieuw deep‑learning‑kader, de Unified Multitask and Multiview Deep Architecture (UMDA), ontworpen om één model uit meerdere datatypes te laten leren en vele taken op te lossen zonder verward of instabiel te raken.
Waarom hedendaagse multi‑vaardige AI vaak moeite heeft
De meeste huidige systemen die meerdere taken leren (multitask learning) of meerdere datatypes combineren, zoals beeld en tekst (multiview learning), kampen met drie grote problemen. Ten eerste kunnen verschillende taken elkaar tijdens training tegenwerken: betere prestaties op de ene taak kunnen ongemerkt een andere schaden, een probleem dat negatieve overdracht wordt genoemd. Ten tweede gaat bij het simpel stapelen of middelen van informatie uit verschillende bronnen vaak subtiele maar belangrijke relaties tussen die bronnen verloren. Ten derde kan het trainingsproces zelf wankel worden, met grote schommelingen in de richting waarin de parameters van het model worden bijgewerkt. Deze problemen zijn vooral ernstig in praktijkomgevingen zoals medische diagnostiek of industriële inspectie, waar data complex is en beslissingen betrouwbaar moeten zijn.
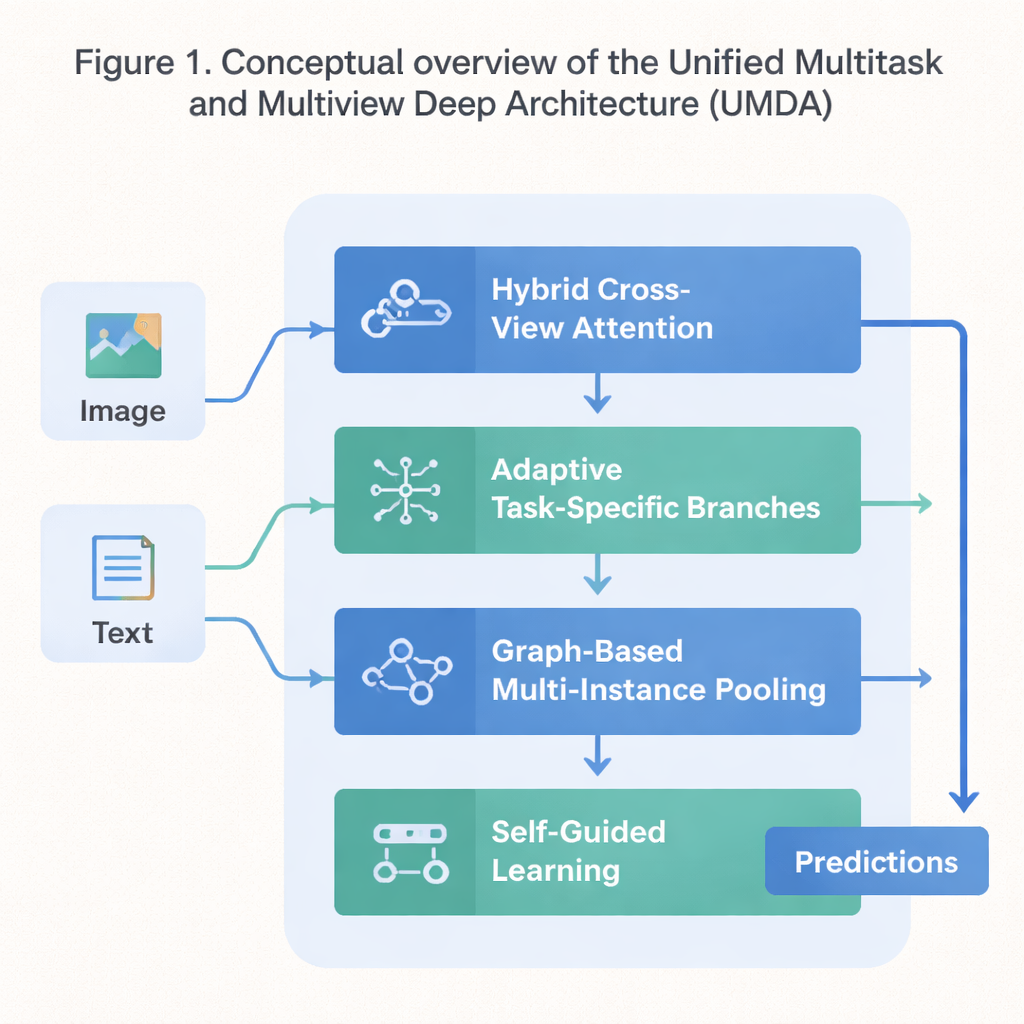
Een vierdelig plan voor coöperatief leren
UMDA pakt deze zwaktes aan door het leerproces op te delen in vier nauw verbonden onderdelen die informatie op een gecontroleerde manier delen. Het eerste onderdeel, Hybrid Cross‑View Attention, bekijkt verschillende zienswijzen van dezelfde data — zoals tekst en afbeeldingen die een film beschrijven — en leert welke zienswijze op elk moment een andere moet beïnvloeden. Het gebruikt wiskundige middelen die het model stimuleren niet te veel op één zienswijze te vertrouwen, om elke zienswijze onderscheidend te houden en tegelijk algemeen overeenstemming te bewaren. Simpel gezegd leert het model al zijn “zintuigen” te gebruiken zonder dat één het andere overstemt.
Taken onderscheidend maar toch coöperatief houden
Het tweede onderdeel, Adaptive Task‑Specific Branching, scheidt generieke kennis die veel taken delen van de specifieke kennis die elke taak uniek nodig heeft. In plaats van alle taken precies dezelfde features te laten gebruiken, bouwt UMDA aparte “takken” voor elke taak die toch via zorgvuldig gewogen verbindingen met elkaar kunnen communiceren. Extra straftermen in het trainingsdoel duwen deze takken ertoe verschillend genoeg te worden om te specialiseren, maar niet zo verschillend dat ze uiteendrijven en stoppen met samenwerken. Deze balans vermindert schadelijke interferentie tussen taken terwijl ze toch profiteren van wat de anderen leren.
Structuur zien in verzamelingen voorbeelden
Veel echte datasets bestaan uit verzamelingen gerelateerde items — bijvoorbeeld meerdere beeldpatches van één medische preparaat of veel frames van een video. Het derde onderdeel van UMDA, Graph‑Based Multi‑Instance Pooling, modelleert expliciet de relaties tussen deze items door ze als knopen in een netwerk te behandelen. Het verbindt vergelijkbare items, laat informatie langs die verbindingen stromen en vat vervolgens de hele verzameling samen in één compacte representatie. Extra regularisatie stimuleert nabije items met elkaar overeen te stemmen terwijl er genoeg diversiteit blijft, waardoor het model structurele patronen kan vastleggen die simpel middelen zou missen.
Zelfsturend trainen voor gestaag vooruitgang
Het laatste onderdeel, Self‑Guided Learning, richt zich op hoe het model wordt getraind in plaats van op zijn interne structuur. Het meet continu hoe sterk en hoe vergelijkbaar de trainingssignalen van elke taak zijn en past automatisch de leersnelheid voor elke taak aan. Het maakt ook de gradients glad en weegt ze opnieuw — de signalen die het model vertellen hoe het moet veranderen — zodat taken met overeenkomende doelen elkaar versterken en taken die in zeer verschillende richtingen trekken de training niet destabiliseren. Getest op een standaarddataset die filmbeschrijvingen en posters combineert, behaalde UMDA een hogere gemiddelde nauwkeurigheid dan een dozijn state‑of‑the‑art concurrenten, hield de relatie tussen zienswijzen consistenter en verminderde een belangrijke maat voor trainingsinstabiliteit met meer dan de helft.
Wat dit betekent voor AI‑systemen in de praktijk
Voor niet‑specialisten is de kernboodschap dat UMDA een manier biedt om enkele AI‑modellen te bouwen die meerdere datatypes en doelen betrouwbaarder aankunnen. Door het model te leren wanneer informatie gedeeld moet worden en wanneer ze gescheiden moet blijven, en door het automatisch te laten afstemmen hoe het leert, levert het kader betere voorspellingen, meer coherente interne representaties en een vloeiender trainingsproces. Dit maakt het een veelbelovende bouwsteen voor toekomstige systemen in de geneeskunde, autonoom rijden en andere complexe toepassingen waar AI veel signalen tegelijk moet interpreteren zonder het evenwicht te verliezen.
Bronvermelding: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
Trefwoorden: multitask learning, multimodale AI, stabiliteit van deep learning, attention‑netwerken, graph neural networks