Clear Sky Science · nl
Hybride deep learning-model voor luchtkwaliteitsvoorspelling en de impact op de gezondheidszorg
Waarom schonere lucht en slimmer voorspellen ertoe doen
Luchtvervuiling is meer dan een wazige skyline—het verergert ongemerkt ademhalingsproblemen, belast het hart en verkort levens. Stedelijke autoriteiten vertrouwen tegenwoordig op de Air Quality Index (AQI) om mensen te waarschuwen wanneer het onveilig is om buiten te zijn, maar die waarschuwingen zijn vaak gebaseerd op gisteren’s gegevens of eenvoudige prognoses die plotselinge pieken missen. Dit artikel onderzoekt een nieuwe manier om de kortetermijnluchtkwaliteit te voorspellen met een combinatie van geavanceerde computermodellen en zorgvuldig ontworpen invoerfeatures, met als doel mensen en zorgsystemen eerder en betrouwbaarder te waarschuwen.
Van vuile lucht naar één gezondheidsscore
De studie richt zich op Gurugram, een snelgroeiende stad in India waar verkeer, industrie en bouw allemaal bijdragen aan slechte lucht. Zes belangrijke verontreinigende stoffen—fijne deeltjes (PM2.5 en PM10), grondozon, stikstofdioxide, zwaveldioxide en koolmonoxide—werden elk uur over vier maanden verzameld met de OpenWeather-luchtvervuilingsdienst. Deze metingen werden omgezet in één AQI-waarde door elke verontreinigende stof te vergelijken met nationale veiligheidslimieten en vervolgens de slechtste waarde als de algemene score van de stad te nemen. Deze AQI-waarde is wat mensen in weerapps zien als categorieën zoals “Goed,” “Matig,” “Slecht,” of “Zeer slecht,” elk gekoppeld aan verschillende niveaus van gezondheidszorgvuldigheid.
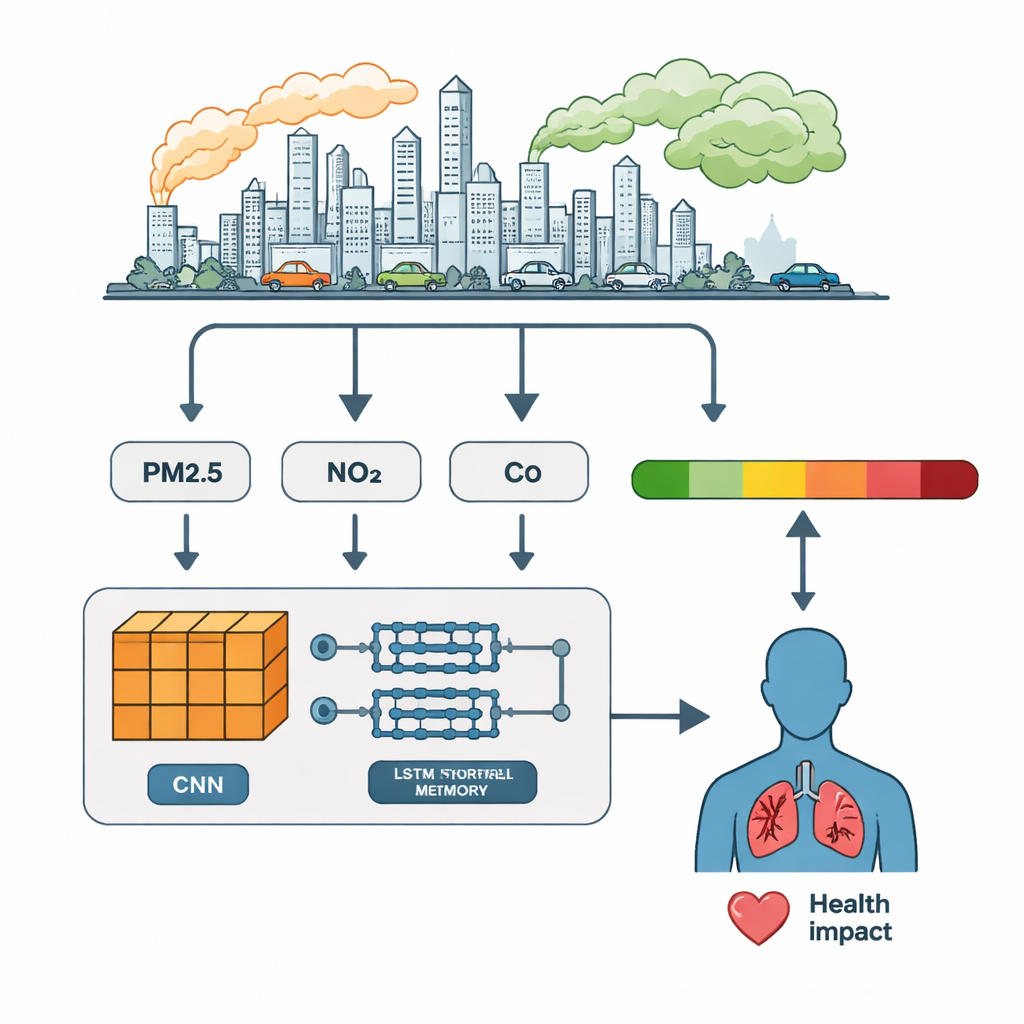
Computers leren de ritmes van vervuiling lezen
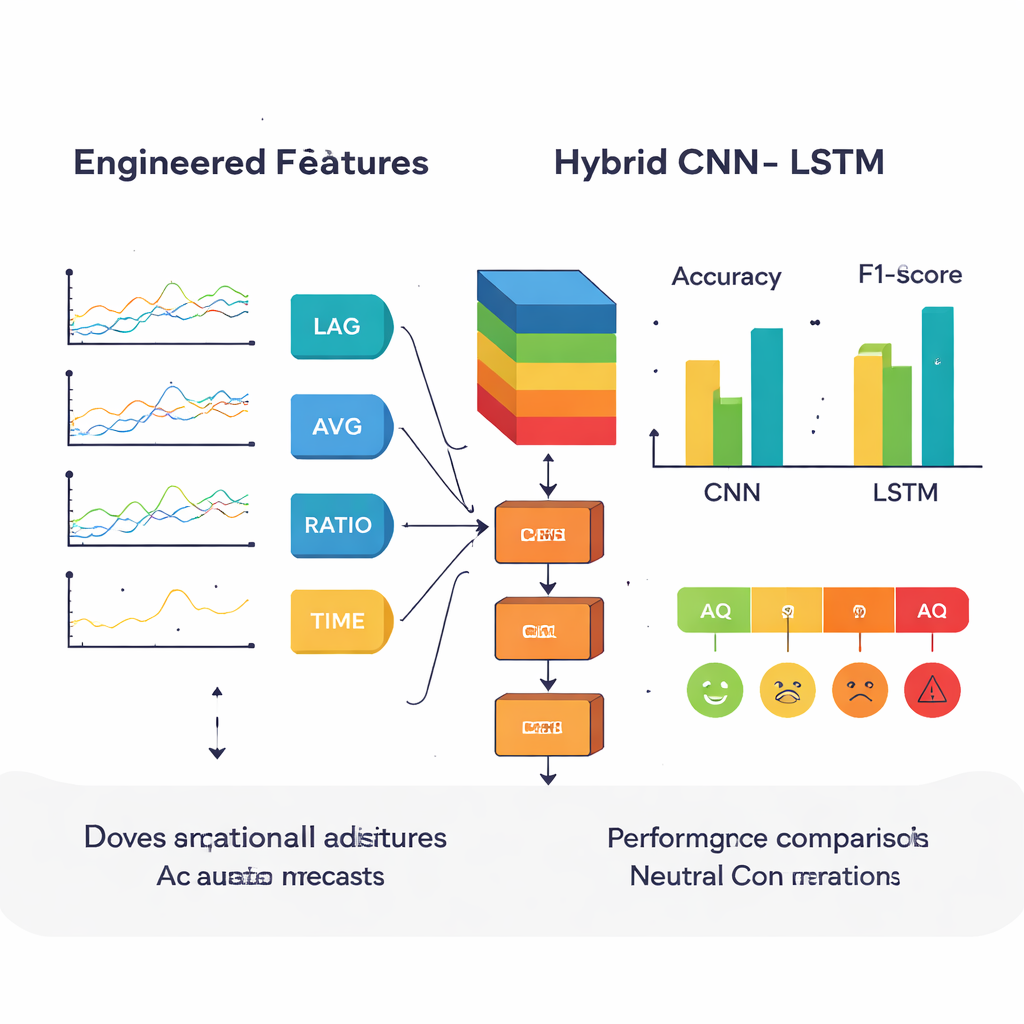
In plaats van ruwe meetwaarden direct in een model te stoppen, creëerden de auteurs eerst extra features die weerspiegelen hoe lucht zich in werkelijkheid gedraagt. Ze voegden vertraagde waarden toe om te tonen hoe vervuiling er een paar uur eerder uitzag, voortschrijdende gemiddelden om korte pieken glad te strijken, en verhoudingen zoals PM2.5/PM10 om fijn stof van grof stof te onderscheiden. Ze codeerden ook kalenderpatronen—zoals tijd van de dag, dag van de week en maand—met cyclische signalen om routinematige menselijke activiteiten vast te leggen, zoals verkeersdrukte doordeweeks of vertragingen in het weekend. Deze door mensen ontworpen signalen moesten de modellen helpen subtiele trends en interacties te zien die ruwe cijfers alleen kunnen verbergen.
Twee soorten deep learning combineren
De onderzoekers vergeleken drie deep learning-benaderingen. Een eendimensionaal convolutioneel neuraal netwerk (CNN) blinkt uit in het herkennen van lokale patronen—korte uitbarstingen of vormen in de data. Een long short-term memory (LSTM)-netwerk is sterk in het onthouden hoe waarden zich in de tijd ontwikkelen. Het hybride CNN–LSTM-model schakelt deze sterke punten achter elkaar: eerst comprimeren en benadrukken CNN-lagen belangrijke features uit de verontreinigingsreeksen; daarna volgen LSTM-lagen die bijhouden hoe die features uur na uur veranderen. Alle drie de modellen werden getraind op het grootste deel van de data en getest op het restant, waarbij gebruikgemaakt werd van standaardscores zoals precisie, recall en F1-score om te beoordelen hoe goed ze elk uur aan de juiste AQI-categorie toeschreven.
Scherpere voorspellingen en de betekenis voor de gezondheid
In herhaalde experimenten leverde het hybride model consequent de beste balans tussen nauwkeurigheid en betrouwbaarheid. Met de ontworpen features erbij behaalde het een F1-score van ongeveer 91 procent, iets vóór de autonome LSTM en duidelijk beter dan de CNN. Het maakte ook bijzonder sterke onderscheidingen aan het viesste uiteinde van de schaal, waarbij het zelden “Zeer slecht” met veiligere categorieën verwarde. Een eenvoudige toevoeging zette elk voorspeld AQI-niveau om in een ruwe gezondheidsrisicoscore, die bijvoorbeeld aangeeft dat “Zeer slecht” en “Ernstig” samenhangen met sterk verhoogde kansen op ademhalings- en hartproblemen. De auteurs benadrukken dat deze risicoscores richtlijnen zijn en geen medische diagnoses, maar ze laten zien hoe luchtkwaliteitsvoorspellingen kunnen worden omgezet in meer intuïtieve gezondheidssignalen.
Wat dit betekent voor steden en burgers
De studie concludeert dat het combineren van doordacht ontworpen invoerfeatures met een hybride CNN–LSTM-architectuur kortetermijn-AQI-voorspellingen zowel nauwkeuriger als stabieler kan maken dan het gebruik van één enkel model. Hoewel het werk beperkt is tot één stad en een paar maanden aan data, wijst het op praktische hulpmiddelen die schoolsluitingen, schema’s voor buitenwerk, ziekenhuisparaattheid en persoonlijke keuzes zoals wanneer je buiten gaat sporten of een mondkapje draagt, kunnen informeren. Met langere datasets en bredere tests zouden vergelijkbare systemen de ruggengraat kunnen vormen van datagedreven luchtkwaliteitsmonitoring, waardoor mensen eerder gewaarschuwd worden voor ongezonde lucht en beleidsmakers kunnen reageren voordat vervuiling piekt.
Bronvermelding: Madan, T., Sagar, S., Singh, Y. et al. Hybrid deep learning model for air quality prediction and its impact on healthcare. Sci Rep 16, 6036 (2026). https://doi.org/10.1038/s41598-026-36564-5
Trefwoorden: luchtkwaliteitsindex, deep learning, CNN-LSTM, gezondheidsrisico, vervuilingsvoorspelling