Clear Sky Science · nl
Verbeterde cricketwedstrijdvoorspelling met kernelmethoden voor feature-extractie en backpropagation-neurale netwerken
Slimmere voorspellingen voor cricketfans
Cricketliefhebbers kennen de spanning van het raden wie er zal winnen terwijl een wedstrijd alle kanten op kan gaan. Deze studie zet dat onderbuikgevoel om in cijfers door moderne data-instrumenten te gebruiken om de uitkomst van One Day International (ODI)-wedstrijden per bal te voorspellen. In plaats van te wachten tot het einde, werkt het systeem zijn schatting bij na elke over en geeft zo een doorlopende inschatting van de kansen van elk team naarmate de wedstrijd vordert.
Het spel lezen als een data-expert
De kern van het werk is een eenvoudig idee: iedere over is een momentopname van de wedstrijd. De auteurs behandelen elk van deze snapshots als een afzonderlijke speltoestand en vragen: “Gezien wat we nu weten, hoe waarschijnlijk is het dat Team B wint?” Om dit te beantwoorden voeren ze zes soorten informatie in een voorspellingssysteem: hoeveel ballen er nog zijn, met hoeveel runs Team A voorligt, hoeveel wickets er nog over zijn, hoe sterk elk team in het algemeen is, of het thuistalent een kant bevoordeelt, en wie de toss heeft gewonnen. Door deze elementen te combineren, vangt het systeem zowel de druk van de scoreboard-situatie als de bredere context waarnaar menselijke commentatoren vaak verwijzen.
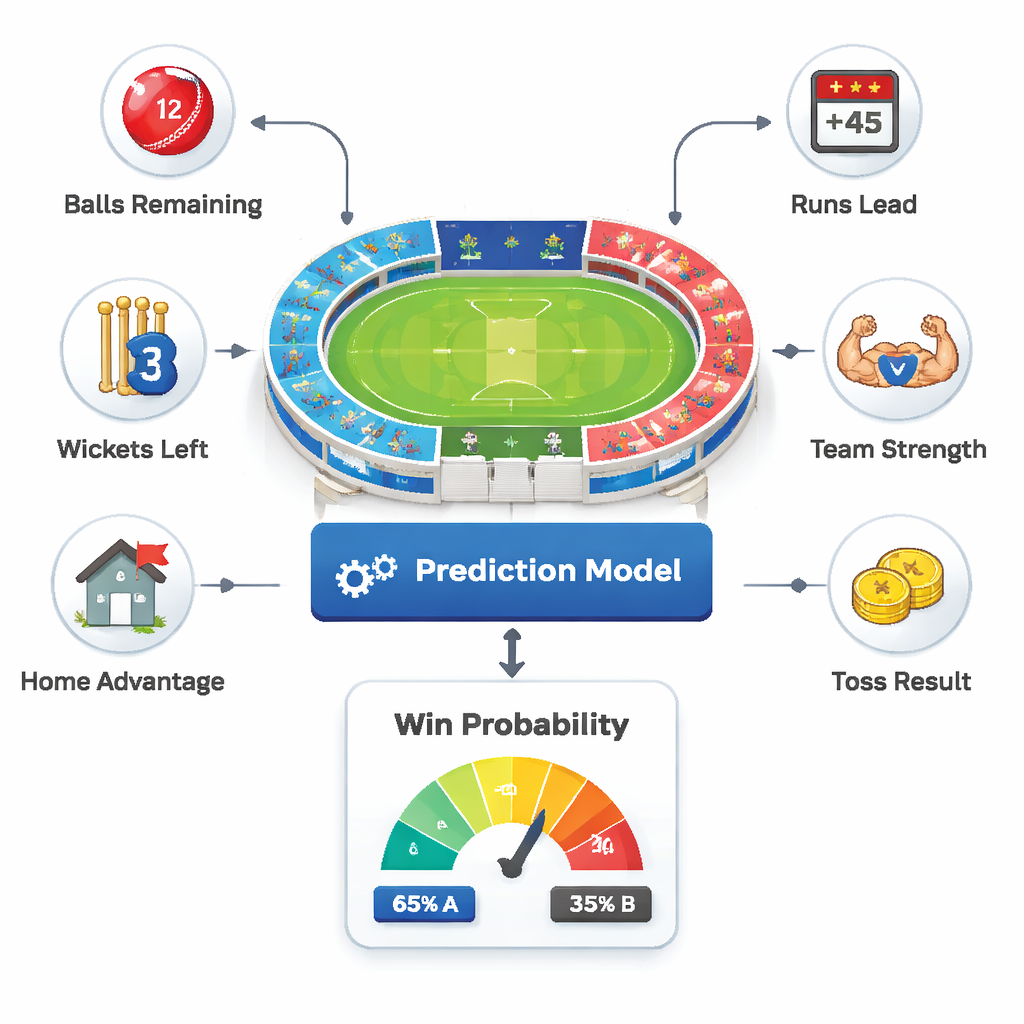
Sterktescores opbouwen uit een eeuw aan wedstrijden
Het model is getraind op een enorme verzameling internationale cricketgegevens die teruggaan tot 1877 en de ODI-, Test- en T20-formaten beslaan. Voor elke speler verzamelen de onderzoekers batting-, bowling- en fielding-statistieken zoals gemiddeldes, strike rates en economy rates. Deze worden gecombineerd tot een “teamsterkte”-score die aangeeft hoe sterk een ploeg op papier is voordat er een bal is gevallen. Tijdens de wedstrijd wordt deze langetermijnsterkte vermengd met kortetermijnfactoren zoals thuisvoordeel en de huidige chase-situatie, wat ongeveer 100.000 zorgvuldig schoongemaakte wedstrijdfase-registraties oplevert voor het leerproces.
Algoritmen laten kiezen welke aanwijzingen het meest spreken
Niet elke statistiek helpt de computer een betere voorspelling te doen, en te veel invoer kan hem juist verwarren. Om dit aan te pakken gebruiken de auteurs een zoekmethode geïnspireerd op sportcompetities, de League Championship Algorithm. In deze benadering concurreren veel verschillende subsets van kenmerken met elkaar. De subsets die tot betere voorspellingen leiden worden behandeld als winnende teams, en zwakkere subsets kopiëren delen van hun strategie. Over vele ronden spitst dit proces zich toe op een kleine set bijzonder bruikbare invoervariabelen. Tests tonen aan dat deze selectie-methode het vaker beter doet dan gebruikelijkere technieken, wat leidt tot hogere nauwkeurigheid en een eenvoudiger, efficiënter model.
Hoe het neurale netwerk leert een winnaar te voorspellen
Zodra de beste features zijn gekozen, worden ze in een backpropagation-neuraal netwerk gevoerd, een flexibel patroonherkenningsinstrument dat interne gewichten aanpast totdat het betrouwbaar wedstrijdfases aan uitkomsten kan koppelen. Elke over wordt één trainingsvoorbeeld: de input zijn de zes sleutelcriteria en de output is of Team B uiteindelijk won of verloor. Door herhaaldelijk zijn gissingen te vergelijken met echte resultaten en zijn interne instellingen bij te sturen om fouten te verminderen, leert het netwerk geleidelijk subtiele combinaties van omstandigheden — zoals een sterk jagend team met wickets in de hand en thuisvoordeel — die doorgaans tot een overwinning leiden.
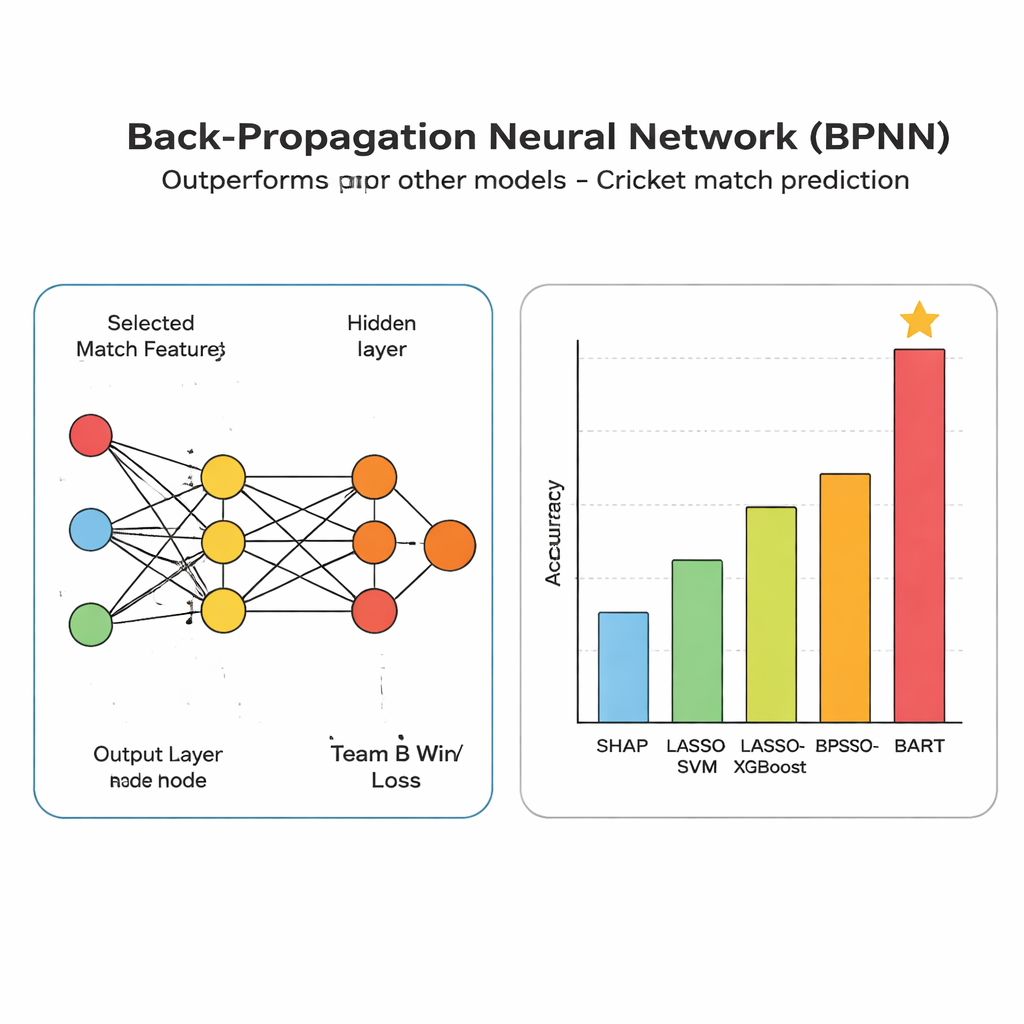
Beter presteren dan concurrerende modellen over formaten heen
De auteurs zetten hun netwerk af tegen diverse rivaliserende benaderingen, waaronder modellen met handmatig geselecteerde features en boomgebaseerde methoden die veel worden gebruikt in sportanalyse. Over ODI-, Test- en T20-data levert hun systeem hogere nauwkeurigheid, met scores op de testset rond het midden van de 80 procent, en sterkere prestaties op maatstaven die zowel vastleggen hoe vaak het een waarschijnlijke winnaar aanwijst als hoe vaak die positieve voorspellingen kloppen. De meest invloedrijke factoren blijken scoringsgerelateerde statistieken te zijn zoals strike rate en totaal aantal runs, wat de intuïtie van een fan bevestigt dat snelle, consistente scorers nauwe wedstrijden kunnen kantelen.
Wat het betekent voor fans, teams en omroepen
Voor een algemene lezer is de conclusie dat de dynamiek van een cricketwedstrijd nu kan worden vertaald naar precieze, regelmatig bijgewerkte winstkansen. Door langetermijnspelerstatistieken, directe matchomstandigheden en een zorgvuldig afgestemd leersysteem te combineren, toont de studie aan dat we uitkomsten met indrukwekkende betrouwbaarheid kunnen voorspellen terwijl de wedstrijd nog bezig is. Dergelijke hulpmiddelen kunnen live-commentaar ondersteunen, coachingsbeslissingen informeren en zelfs kijker-apps aandrijven die laten zien hoe elke bal de kansen verschuift. In eenvoudige termen laat het onderzoek zien dat wanneer de rijke statistieken van cricket worden gecombineerd met slimme algoritmen, ons instinctieve gevoel van “wie er bovenaan staat” kan worden omgezet in een helder, data-gedreven beeld.
Bronvermelding: Dhinakaran, K., Anbuchelian, S. Enhanced cricket match prediction using kernel methods for feature extraction and back-propagation neural networks. Sci Rep 16, 6478 (2026). https://doi.org/10.1038/s41598-026-36555-6
Trefwoorden: cricketanalyse, sportvoorspelling, machine learning, neurale netwerken, wedstrijdvoorspelling