Clear Sky Science · nl
Een hybride ResNet50-vision transformer-model met een attentiemechanisme voor classificatie van luchtbeelden
Waarom slimmer kijken vanuit de lucht ertoe doet
Luchtfoto’s van drones en satellieten sturen tegenwoordig hulp bij rampen, stadsplanning, landbouw en zelfs verkeersbeheer. Computers leren begrijpen wat er in deze complexe, drukke top‑down beelden te zien is blijft echter lastig. Deze studie presenteert twee nieuwe modellen voor kunstmatige intelligentie die verschillende manieren van ‘zien’ combineren om tien typen objecten in dronefoto’s — zoals gebouwen, auto’s, bomen en wegen — beter te herkennen dan eerdere methoden. Hun aanpak kan geautomatiseerde bewaking vanuit de lucht sneller, betrouwbaarder en makkelijker inzetbaar maken in praktijkomstandigheden.
Uitdagingen van het kijken naar de wereld van bovenaf
Luchtbeelden verschillen van de alledaagse foto’s die we met onze telefoons maken. Objecten zijn kleiner, kunnen in vreemde hoeken verschijnen en liggen vaak dicht op elkaar. Een auto die deels door een boom wordt bedekt, een smal voetpad of hopen puin na een aardverschuiving zijn soms zelfs voor mensen lastig snel te detecteren. Toch vertrouwen overheden, hulpdiensten en milieuagentschappen steeds meer op drone‑ en satellietbeelden om overstromingen, bosbranden, stedelijke groei en infrastructuurschade in kaart te brengen. Met duizenden satellieten in een baan en een snel groeiende markt voor luchtfotografie neemt de hoeveelheid data zo snel toe dat handmatige inspectie onhoudbaar wordt, wat de behoefte aan nauwkeuriger en efficiëntere automatische classificatie vergroot.
Twee manieren waarop machines leren zien samenbrengen
De meeste succesvolle systemen voor beeldherkenning vandaag gebruiken deep learning. De ene familie, convolutionele neurale netwerken, blinkt uit in het oppikken van lokale patronen zoals randen, texturen en kleine vormen. De andere, nieuwere familie, de vision transformers, behandelt een afbeelding als een reeks patches en is bijzonder goed in het vastleggen van langeafstandrelaties, bijvoorbeeld hoe een weg, een cluster daken en een nabijgelegen open veld samen een scène vormen. Dit werk combineert beide: een bekend convolutioneel model genaamd ResNet-50 en een vision transformer. Elk verwerkt dezelfde luchtfoto en haalt zijn eigen set numerieke kenmerken naar boven — compacte samenvattingen van wat het netwerk over de scène heeft geleerd. Deze twee informatiestromen worden vervolgens samengevoegd en doorgegeven aan een ‘attentiemodule’ die leert welke kenmerken het belangrijkst zijn om te beslissen tussen de tien doelklassen.
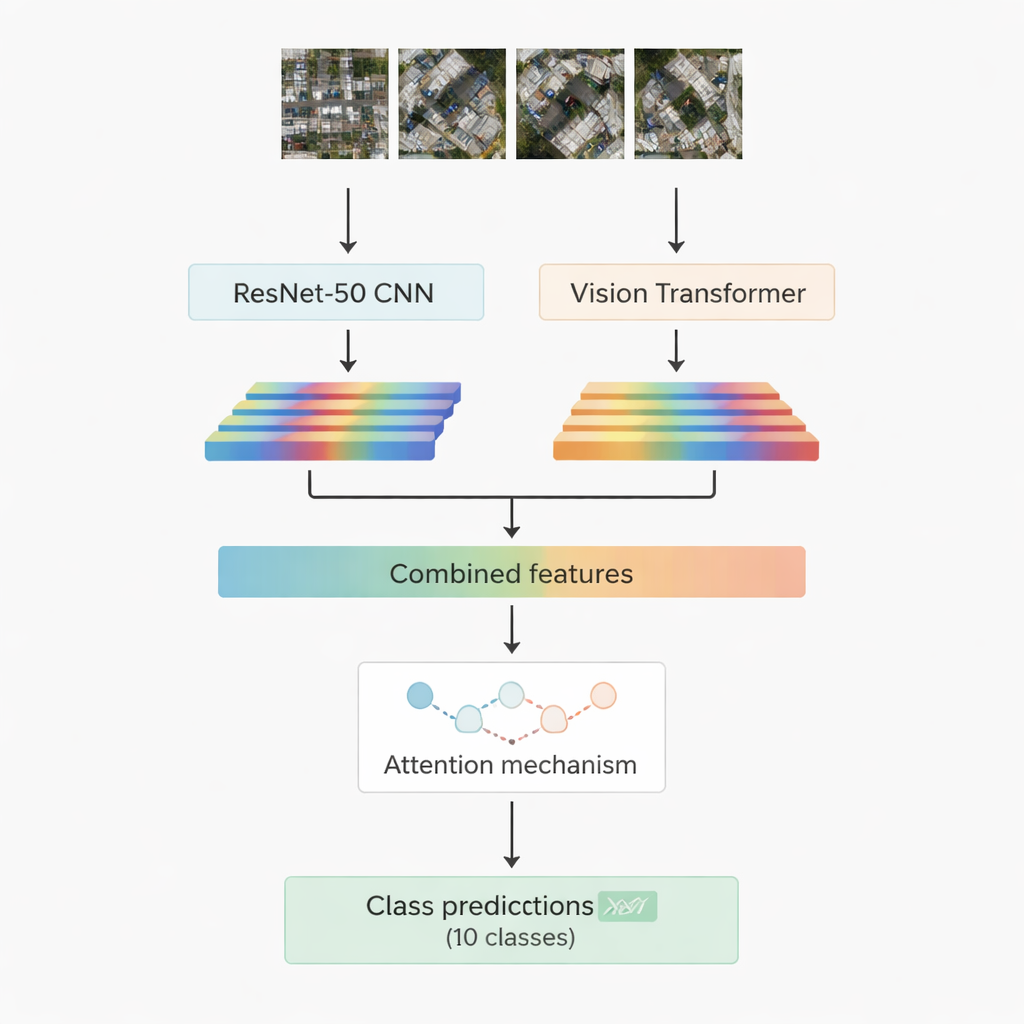
Twee attentiestrategieën om te focussen op wat telt
De onderzoekers ontwerpen en testen twee versies van hun hybride systeem. In de eerste voegen ze simpelweg de kenmerken van ResNet-50 en de transformer samen en voeren die in een multi‑head attention‑module. Dit mechanisme is te vergelijken met vele kleine spots die elk naar de kenmerken kijken vanuit een iets andere invalshoek en daarna hun bevindingen combineren. In de tweede versie gebruiken ze cross‑attention: de kenmerken van het convolutionele netwerk fungeren als een query die de transformer‑kenmerken vraagt waar te kijken, waardoor de ene stroom de andere kan sturen. In beide gevallen wordt de attentieoutput door gangbare lagen geleid die uiteindelijk het beeldpatch toewijzen aan een van de tien klassen, waaronder gebouwen, auto’s, puin, voetpaden, metalen wegen, open velden, schaduwen, tanks, bomen en daken.
Testen op dronebeelden uit de praktijk
Om te beoordelen hoe goed hun modellen presteren, gebruiken de auteurs een openbare dataset uit de Indiase staat Sikkim, verzameld door een drone op 60 tot 120 meter hoogte. De data bestrijken rivieren, bossen, heuvels en bebouwde gebieden, opgedeeld in kleine patches zodat elke afbeelding in één van de tien categorieën valt. De dataset is gebalanceerd, met een gelijk aantal trainings‑ en testbeelden per klasse, wat het een eerlijke testomgeving maakt. De onderzoekers trainen beide hybridemodellen onder identieke omstandigheden en vergelijken vervolgens hun prestaties met veelgebruikte maatstaven: nauwkeurigheid, precisie, recall, F1‑score, verwarringsmatrices en ROC‑curves. Ze benchmarken hun resultaten ook tegen verschillende bekende netwerken en recentere transformer‑gebaseerde methoden uit de literatuur.

Scherpere classificatie en potentie voor toepassingen
Beide hybridemodellen presteren beter dan eerdere systemen op deze dataset en bereiken totale nauwkeurigheden van 95,52% en 95,80%, waarbij de multi‑head attention‑versie een kleine voorsprong heeft. Hun prestatie blijft sterk en stabiel over alle tien objecttypen, en gedetailleerde analyses tonen aan dat zelfs de zwakkere klassen nog steeds goed worden herkend. Dit suggereert dat het mengen van convolutionele netwerken, vision transformers en attentiemechanismen een krachtige benadering is om complexe luchtbeelden te begrijpen. Voor de niet‑specialist komt het erop neer dat computers veel beter worden in het beantwoorden van vragen als “Waar zijn de wegen?” of “Welke stukken tonen puin of gebouwen?” in enorme verzamelingen dronebeelden. Naarmate zulke modellen worden verfijnd en uitgebreid naar nieuwe datasets, kunnen ze de basis vormen voor slimmer rampenbeheer, milieumonitoring en slimme stadsdiensten die afhangen van snelle, betrouwbare interpretatie van beelden vanuit de lucht.
Bronvermelding: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
Trefwoorden: classificatie van luchtbeelden, dronebeelden, deep learning, vision transformer, remote sensing