Clear Sky Science · nl
Geoptimaliseerde aandacht-gebaseerde gelaagde shuffle-longterm afhankelijke netwerkprestatieanalyse van adaptief e‑learning onder IT‑professionals
Slimmere online training voor werkende techprofessionals
Voor veel informatie‑technologie (IT)‑professionals zijn online cursussen inmiddels de belangrijkste manier om vaardigheden up‑to‑date te houden. De meeste trainingsplatforms beoordelen deelnemers echter nog met grove middelen zoals quiztotalen of voltooiingsbadges. Deze studie presenteert een slimmer manier om de digitale “voetafdrukken” die leerlingen achterlaten te lezen en die om te zetten in nauwkeurige, realtime inzichten over hoe goed iemand daadwerkelijk leert.
Waarom one‑size‑fits‑all online cursussen tekortschieten
Conventioneel e‑learning behandelt de meeste deelnemers hetzelfde: iedereen ziet dezelfde modules, maakt dezelfde quizzes en wordt beoordeeld met vaste testen. Die aanpak negeert hoe verschillend professionals vooruitgang boeken, vooral in snel veranderende vakgebieden zoals cybersecurity of cloudcomputing. Eerdere onderzoeken probeerden dit te verbeteren met machine learning—door quizscores, bestede tijd en klikgedrag te combineren om succes te voorspellen—maar veel modellen hadden moeite met ruis of onvolledige data, konden niet opschalen naar realistische platforms of volgden niet hoe leren zich over weken en maanden ontwikkelt. Het resultaat was vaak vertraagde, grove feedback die niet gemakkelijk kon sturen naar gepersonaliseerde inhoud of tijdige interventie.
Ruwe cursussessielogs omzetten in schone, eerlijke data
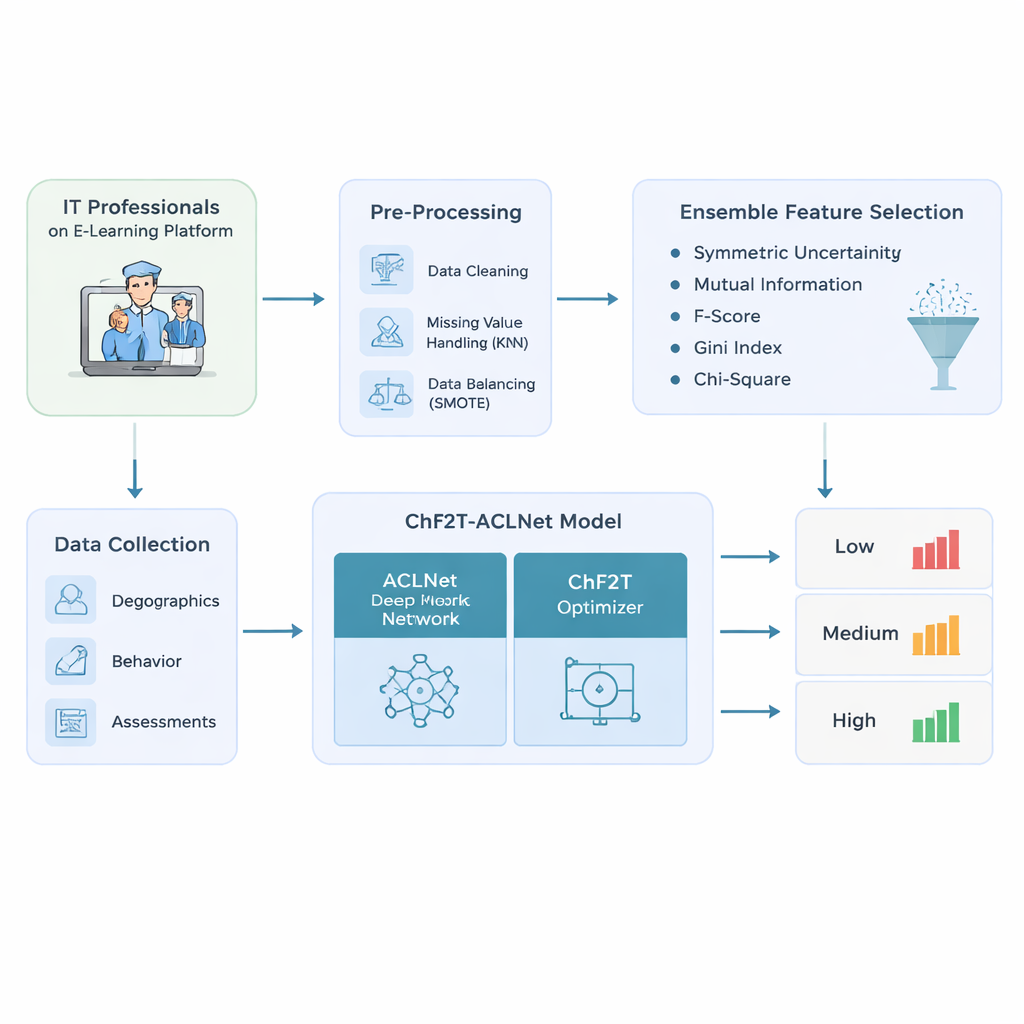
De auteurs beginnen met het ontwerpen van een zorgvuldig datapijplijn voor IT‑professionals die adaptieve e‑learningplatforms gebruiken. Ze verzamelen een rijke mix aan informatie: basisprofielgegevens zoals leeftijd en functierol; gedragssporen zoals bestede tijd, toegangsdata en actieve dagen; en prestatie-indicatoren inclusief quizscores, pogingen, certificaten en beoordelingsratings. Voor het modelleren reinigen ze de data—duplicaten verwijderen, ontbrekende waarden schatten door naar vergelijkbare leerlingen te kijken, en scheve klassenverdelingen corrigeren zodat lage, gemiddelde en hoge presteerders eerlijker worden vertegenwoordigd. Deze balansstap voorkomt modellen die te zelfverzekerd zijn voor alleen de meest voorkomende “gemiddelde” leerlingen en blind zijn voor degenen die worstelen of excelleren.
Selecteren van alleen de meest betekenisvolle signalen
Uit de opgeschoonde dataset stopt het systeem niet simpelweg elke beschikbare kolom in een black box. In plaats daarvan gebruikt het een ensemble van vijf eenvoudige rangschikkingsmethoden om te bepalen welke kenmerken werkelijk belangrijk zijn voor het voorspellen van leerresultaten. Elke methode onderzoekt de relatie tussen een kandidaatkenmerk—zoals quizpogingen of bestede tijd—en het uiteindelijke prestatielabel. Door hun ranglijsten te combineren met een mediaanscore filtert de aanpak ruisende of redundante signalen eruit en houdt alleen de meest informatieve over. Dit vermindert niet alleen de hoeveelheid rekenwerk die het latere model nodig heeft, maar helpt het ook te focussen op patronen die zinvol onderscheid maken tussen lage, gemiddelde en hoge presteerders.
Een hybride netwerk getraind als een sportteam
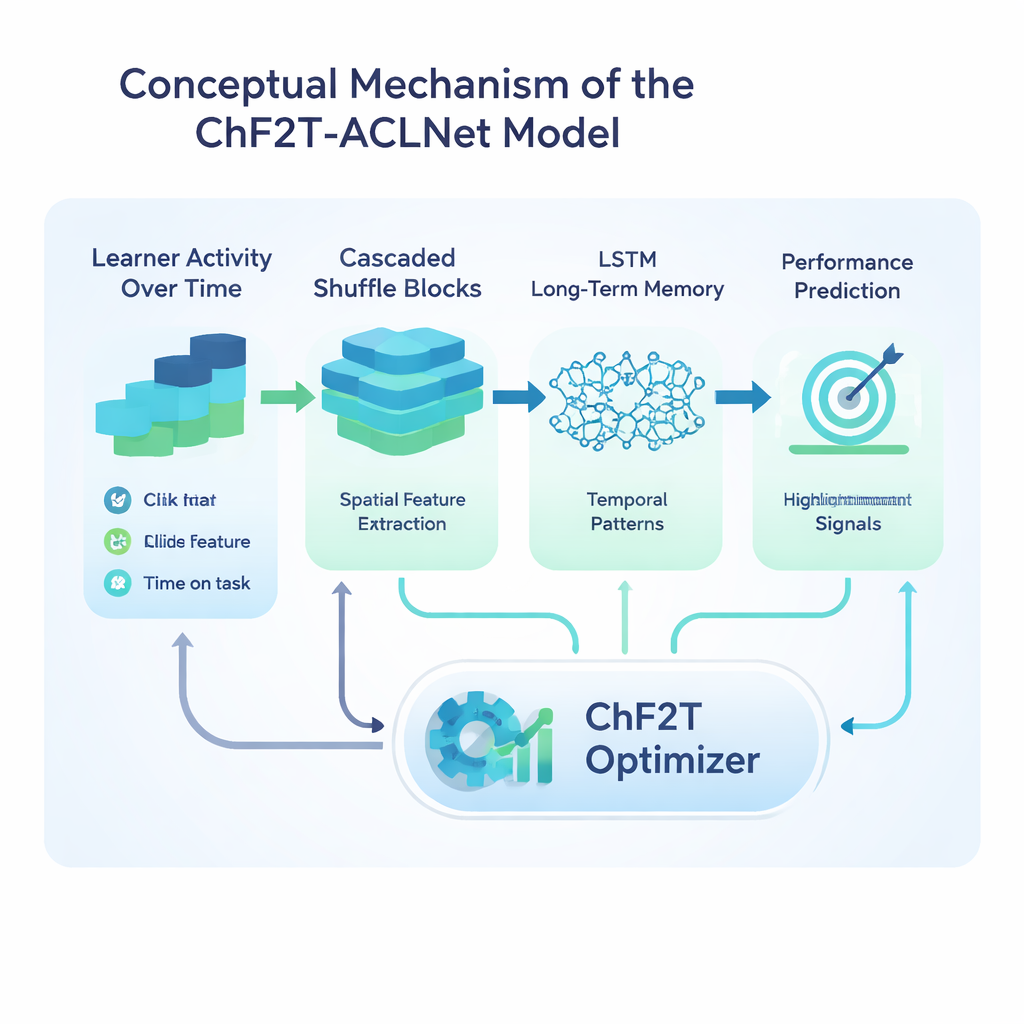
De kern van de studie is een hybride deep‑learningmodel genaamd ACLNet, gecombineerd met een onconventionele trainingsstrategie geïnspireerd op teamsporten. ACLNet gebruikt eerst lichte “shuffle”‑blokken om invoersignalen efficiënt te comprimeren en te mengen, en voert ze vervolgens naar een geheugenmodule die volgt hoe het gedrag van een leerling in de tijd verandert. Een aandachtlaag bovenop benadrukt de meest invloedrijke kanalen—zoals plotselinge dalingen in activiteit of consequent hoge quizscores—voordat een definitieve voorspelling van de prestatiedklasse wordt gemaakt. Om de vele interne instellingen van dit netwerk af te stemmen, introduceren de auteurs het Chaotic Football Team Training (ChF2T)‑algoritme. Virtuele “spelers” verkennen hierin verschillende parameters, imiteren sterke presteerders, vermijden zwakkere instellingen en maken af en toe grote, chaotische sprongen die de zoektocht helpen ontsnappen aan slechte lokale keuzes. Deze mix van structuur en gecontroleerde willekeur versnelt de convergentie en vermindert overfitting.
Hoe goed het systeem in de praktijk presteert
De onderzoekers testen hun pijplijn op een synthetische maar realistische dataset van 1.200 IT‑professionals, opgebouwd om leerbeheersysteemrecords na te bootsen met opzettelijk ongelijke klasseverdelingen. Ze vergelijken hun ChF2T‑ACLNet‑model met verschillende sterke basismodellen, waaronder federated learning‑opstellingen, geavanceerde image‑style netwerken aangepast aan onderwijs, en andere diepe of ensemblemodellen. Over meerdere cross‑validaties bereikt de voorgestelde methode ongeveer 98,9% nauwkeurigheid, met vergelijkbaar hoge precisie, recall en F‑scores. Het behaalt ook een bijna perfecte overeenstemmingsscore gecorrigeerd voor toeval en levert sterke area‑under‑curve‑waarden, wat betekent dat het prestatieniveaus betrouwbaar van elkaar scheidt over veel drempels. Ondanks zijn complexiteit draait het systeem sneller dan concurrerende methoden, dankzij zorgvuldige kenmerksselectie, een efficiënt netwerkontwerp en de snelle convergentie van de optimizer.
Wat dit betekent voor alledaags online leren
Simpel gezegd laat dit werk zien dat het mogelijk is om te observeren hoe professionals door online cursussen bewegen en met hoge zekerheid af te leiden wie moeite heeft, wie het rustig aan doet en wie de stof beheerst—zonder te wachten op een eindexamen. Zo’n systeem kan vroege hints geven, andere oefeningen aanbevelen of mentoren alarmeren lang voordat een leerling achterop raakt. De auteurs noemen nog resterende uitdagingen, zoals opschalen naar zeer grote platforms, aanpassen aan snel veranderende cursusontwerpen en het beter verklaarbaar maken van modelbeslissingen. Toch is hun aanpak een sterke stap richting e‑learning systemen die meer als attente persoonlijke coaches werken dan als statische digitale leerboeken.
Bronvermelding: Yuvapriya, P., Subramanian, P. & Surendran, R. Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals. Sci Rep 16, 6245 (2026). https://doi.org/10.1038/s41598-026-36470-w
Trefwoorden: adaptief e‑learning, learning analytics, deep learning, IT‑professionele training, voorspelling van studentprestaties