Clear Sky Science · nl
Privacybewuste segmentatie van diepeveneuze trombose met een multimodel-federated learning‑kader en het federated averaging‑algoritme
Waarom bloedstolsels en gegevensprivacy ertoe doen
Bloedstolsels die zich diep in de aderen van de benen vormen, bekend als diepeveneuze trombose (DVT), kunnen stilletjes naar de longen reizen en levensbedreigende noodsituaties veroorzaken. CT‑scans kunnen deze stolsels zichtbaar maken, maar het omzetten van duizenden grijswaardenbeelden in betrouwbare, automatische detecties is een lastige taak voor computers. Tegelijkertijd zijn ziekenhuizen terecht terughoudend met het delen van gevoelige patiëntgegevens. Deze studie onderzoekt hoe meerdere ziekenhuizen kunnen samenwerken om een krachtig AI‑systeem voor het vinden van stolsels te trainen — zonder ooit hun ruwe patiëntscans te bundelen of bloot te geven.
Hersenen delen, niet lichamen
De kern van het werk is een techniek genaamd federated learning, waarmee verschillende instellingen gezamenlijk AI‑modellen kunnen trainen terwijl hun gegevens ter plaatse blijven. In plaats van CT‑beelden naar een centrale server te sturen, traint ieder ziekenhuis een lokaal model op zijn eigen scans. Alleen de aangeleerde parameters van het model — in wezen wat het heeft "uitgezocht" over het herkennen van stolsels — worden naar een centrale server gestuurd. Daar combineert een aanpak genaamd federated averaging deze verschillende sets parameters tot één verbeterd globaal model, dat vervolgens teruggestuurd wordt naar alle ziekenhuizen. Op deze manier profiteert elke locatie van de gezamenlijke ervaring van alle deelnemers, terwijl geen enkel patiëntbeeld ooit de thuissituatie van het instituut verlaat. 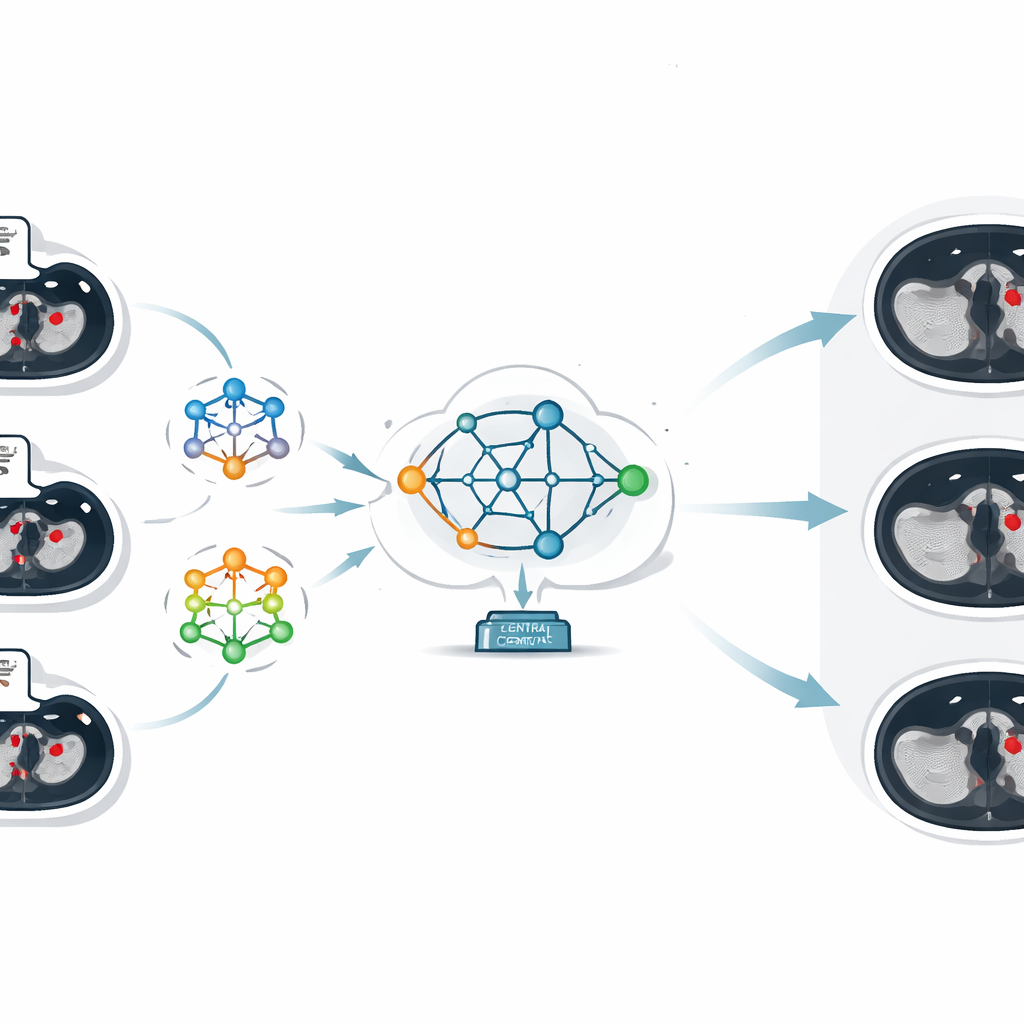
Verschillende AI‑stijlen kijken naar dezelfde aderen
Een belangrijke vernieuwing in deze studie is dat de onderzoekers niet op één type neurale netwerk vertrouwden. Ze stelden zeven verschillende modelontwerpen samen, elk goed in het zien van andere aspecten van de CT‑beelden. Eenvoudigere modellen, zoals basale convolutionele netwerken en sequentiële modellen, zijn sneller en gemakkelijker te draaien op beperkte hardware. Geavanceerdere architecturen, waaronder U‑Net, VGG‑19 en twee aangepaste netwerken met residual-, inception-, attention‑ en multi‑scale‑verwerkingsblokken, zijn beter in het volgen van fijne vaatgrenzen, het opsporen van kleine stolsels en het omgaan met ruis in beelden. Door elk ziekenhuis het model te laten gebruiken dat het beste bij zijn data en rekencapaciteit past, weerspiegelt het systeem de rommelige realiteit van klinische omgevingen in de praktijk in plaats van ervan uit te gaan dat iedere locatie hetzelfde is.
Leren van ongelijk en onvolmaakt materiaal
In de geneeskunde lijkt data van het ene ziekenhuis zelden precies op die van een ander. Scanners, beeldvormingsprotocollen en patiëntpopulaties verschillen, dus de studie werkte doelbewust met "non‑IID" data — verzamelingen die ongelijk en niet identiek verdeeld zijn. Dit maakt training gewoonlijk instabieler. De auteurs omarmden die diversiteit en toonden aan dat het bijeenbrengen van kennis uit meerdere, verschillend gestructureerde modellen de generaliseerbaarheid van het globale systeem daadwerkelijk verbeterde. Ze voerden drie experimentele fasen uit: eerst met drie clients, daarna vijf en ten slotte zeven, gebruikmakend van datasets van 1.000, 2.000 en 3.000 CT‑beelden. In elke stap volgden ze niet alleen hoe vaak het globale model stolsels correct segmenteerde, maar ook hoeveel communicatie nodig was, hoe lang de training duurde, hoe verschillend de data van elke client waren en hoe goed de privacybescherming standhield.
Betere stolseldetectie, tegen een rekenkundige prijs
Over alle fasen heen presteerde het gecombineerde globale model consequent beter dan elk individueel lokaal model. Naarmate het aantal beelden toenam en meer geavanceerde modellen zich bij de federatie voegden, steeg de segmentatie‑nauwkeurigheid van ongeveer 91% tot meer dan 96%, en klom een gebalanceerde kwaliteitsmaat, de F1‑score, van ruwweg 0,89 naar 0,95. Tegelijkertijd daalde een op fouten gerichte verliesmaat met meer dan de helft, wat duidt op schonere, betrouwbaardere stolselcontouren. Deze verbeteringen kwamen niet gratis: de communicatie tussen clients en server nam toe van enkele tientallen megabytes naar meerdere gigabytes, en de gemiddelde trainingstijd steeg van seconden naar vele uren naarmate de architecturen complexer werden. Desondanks handhaafde het systeem een sterke formele privacygarantie, wat aangeeft dat de gedeelde updates zeer weinig informatie over individuele patiënten prijsgeven. 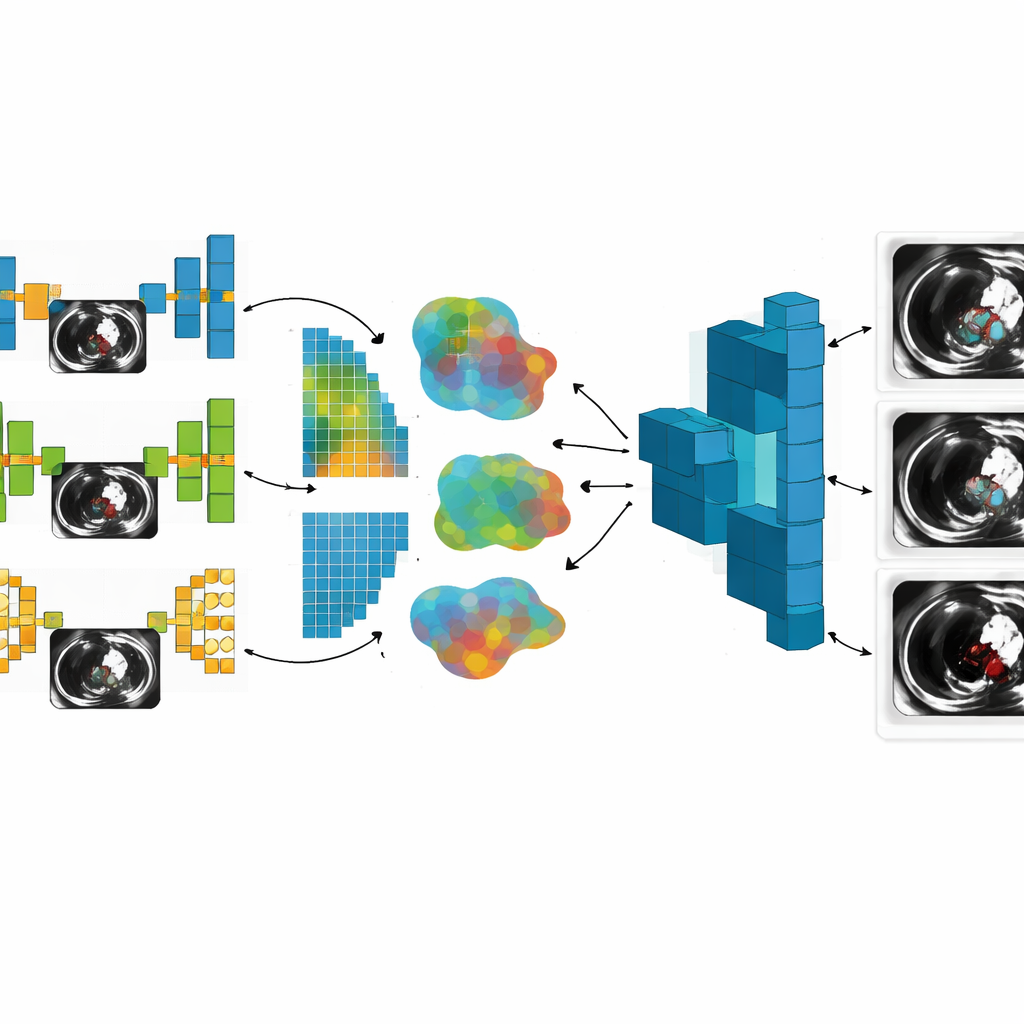
Wat dit betekent voor patiënten en ziekenhuizen
Voor een leek is de kern dat dit werk laat zien hoe ziekenhuizen gezamenlijk een AI kunnen trainen om gevaarlijke bloedstolsels nauwkeuriger te signaleren, zonder de controle over hun gevoelige gegevens op te geven. Door meerdere complementaire modelontwerpen te combineren en zorgvuldig samen te voegen wat ieder model leert, bouwen de auteurs een stolselsegmentatiesysteem dat zowel krachtig als privacybewust is. Hoewel de aanpak aanzienlijke rekenmiddelen en netwerkbandbreedte vereist, wijst het op een toekomst waarin medische centra routinematig samenwerken aan slimmere diagnostische hulpmiddelen, de zorg voor patiënten met risico op DVT en aanverwante aandoeningen verbeteren en tegelijkertijd hun persoonlijke scans veilig achter institutionele muren houden.
Bronvermelding: B, P.L., S, V. Privacy-aware deep vein thrombosis segmentation using a multi-model federated learning framework with the federated averaging algorithm. Sci Rep 16, 11333 (2026). https://doi.org/10.1038/s41598-026-36432-2
Trefwoorden: diepeveneuze trombose, federated learning, medische beeldsegmentatie, privacybehoudende AI, CT‑beeldvorming