Clear Sky Science · nl
Een methode voor entiteitsdisambiguering in korte teksten op basis van het BERT-model en het kortste-pad-algoritme
Waarom het uitzoeken van verwarrende namen belangrijk is
Elke dag zoeken, scrollen en chatten we met korte, vaak rommelige tekstfragmenten—tweets, zoekopdrachten, chatberichten. Deze fragmenten staan vol namen van mensen, plaatsen, bedrijven en zaken die meer dan één betekenis kunnen hebben, zoals “Apple” als fruit of “Apple” als bedrijf. Computers moeten raden welke betekenis we bedoelen, en wanneer ze het mis hebben, worden zoekresultaten, aanbevelingen en online diensten veel minder nuttig. Dit artikel presenteert een nieuwe manier om machines te helpen zulke ambiguïteiten in korte teksten correct te interpreteren, vooral in Chinese sociale media en zoekopdrachten, door moderne taalmodellen te combineren met een slim grafalgoritme.
Van rommelige korte teksten naar heldere doelen
Korte teksten zijn verrassend moeilijk voor computers om te begrijpen. In tegenstelling tot lange artikelen bevatten ze zeer weinig context en staan ze vol jargon, afkortingen en onvolledige zinnen. Traditionele methoden probeerden een naam in de tekst te koppelen aan invoer in een kennisbank, of gebruikten handgemaakte regels en eenvoudigere machine-learningmodellen. Deze benaderingen behandelen woorden vaak alsof ze één vaste betekenis hebben, wat slecht werkt wanneer hetzelfde woord afhankelijk van de context een functietitel, een bedrijf of een lied kan betekenen. Het resultaat is frequente verwarring over naar welke entiteit in de echte wereld een woord in een tweet of zoekopdracht eigenlijk verwijst.
Het systeem leren ambiguïteiten te herkennen
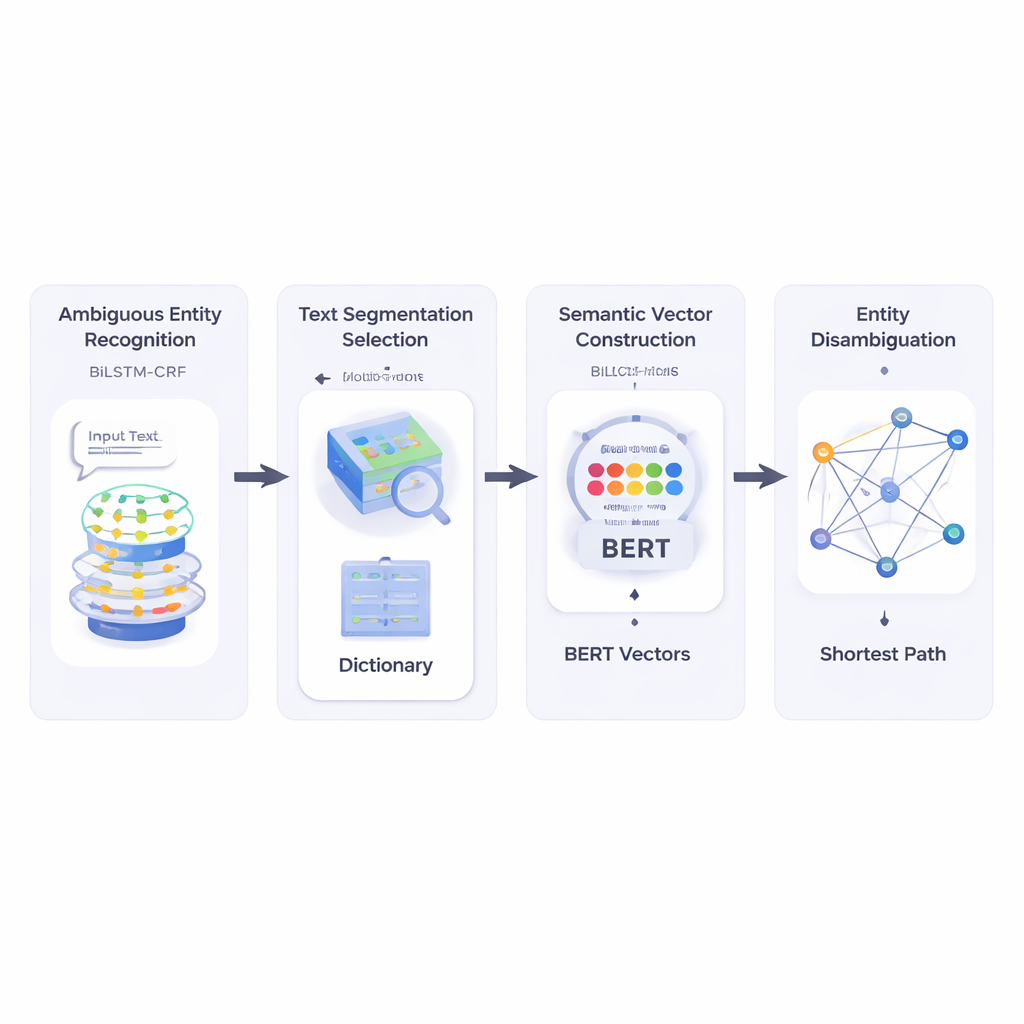
De auteurs bouwen eerst een systeem dat een korte tekst leest en bepaalt welke delen entiteitsnamen zijn en welke daarvan mogelijk ambigu zijn. Ze gebruiken een neurale combinatie genaamd BiLSTM-CRF, die goed is in het taggen van woordvolgordes door zowel linker- als rechtercontext te bekijken. Zodra potentiële entiteiten zijn gemarkeerd, raadpleegt het systeem een grote lexicale bron genaamd HowNet. Als HowNet meerdere betekenissen voor een woord vermeldt, wordt dat woord als ambigu gemarkeerd; bij slechts één betekenis wordt het woord als al duidelijk beschouwd. Deze stap geeft het systeem een gerichte lijst van namen die echt disambiguatie nodig hebben.
Betekenissen omzetten in punten in de ruimte
Vervolgens splitst de methode de korte tekst in kandidaat-woordsegmenten en kiest de beste segmentatie door te controleren hoe goed elke mogelijke scheiding qua betekenis overeenkomt met duidelijk begrepen referentiewoorden in dezelfde zin. Om dit te meten vertrouwen de auteurs op BERT, een krachtig voorgetraind taalmodel dat voor elk woordgebruik een numerieke “semantische vector” produceert die de contextafhankelijke betekenis vastlegt. Door de cosinusgelijkenis tussen deze vectoren te berekenen, vindt het systeem de segmentatie waarvan de stukken semantisch het meest compatibel zijn met de onmiskenbare referentietermen. Dit stelt het model in staat elke mogelijke betekenis van elk woord te representeren als een punt in een multidimensionale ruimte.
Het kortste pad naar de juiste betekenis vinden
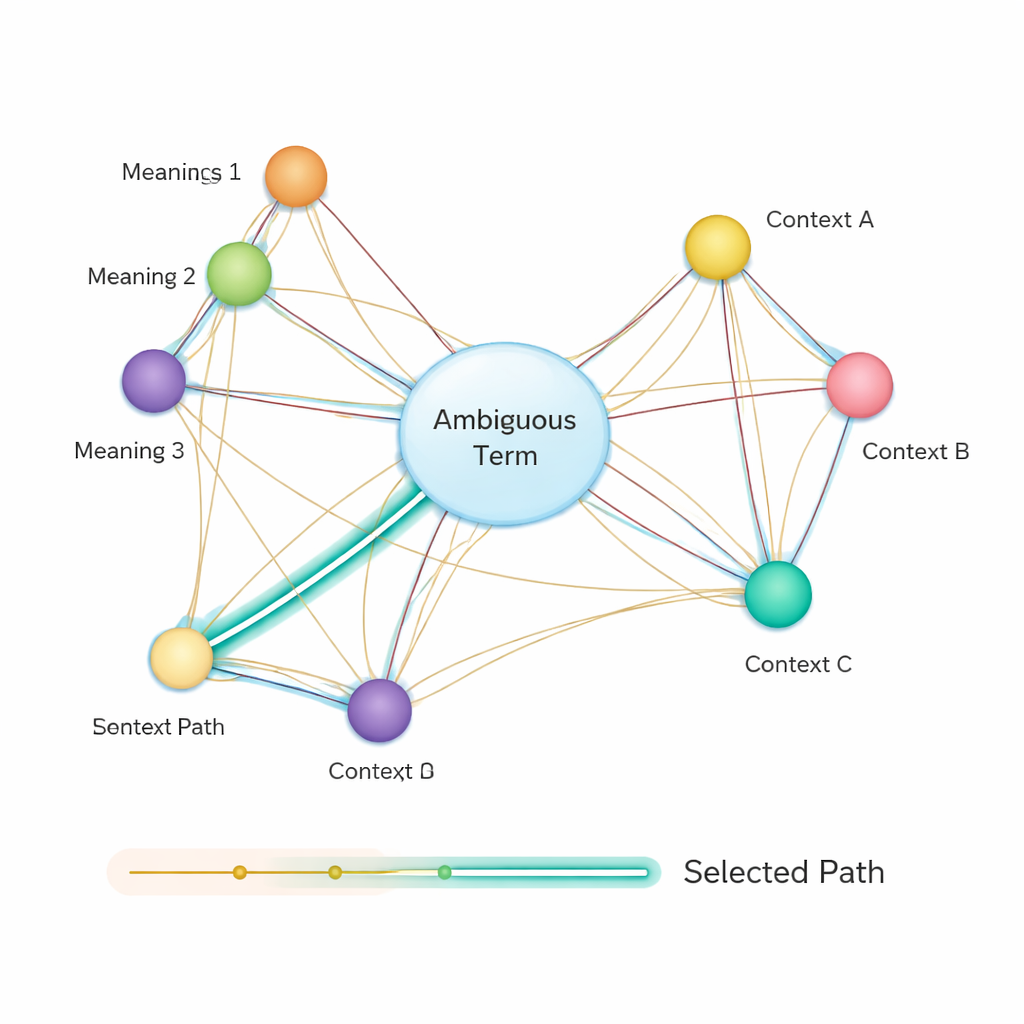
Daarna bouwt de methode een semantisch netwerk: een graaf waarin elke mogelijke betekenis van elk begrip een knoop is, en randen betekenissen verbinden die in dezelfde zin kunnen voorkomen. De sterkte van elke rand is gebaseerd op hoe vergelijkbaar de betekenissen zijn, wederom met behulp van BERT-gebaseerde vectoren. Om te beslissen welke betekenis van een ambigu woord het beste in de zin past, passen de auteurs een klassiek algoritme toe: Dijkstra’s kortste-pad-algoritme. Intuïtief zoekt het systeem naar het pad door deze betekeningsgraaf dat de totale semantische “afstand” zo klein mogelijk houdt. Het gekozen pad komt overeen met een consistente interpretatie van alle termen, en de betekenis van de ambigu entiteit op dit pad wordt geselecteerd als het uiteindelijke antwoord.
Hoeveel beter werkt dit?
De onderzoekers testten hun methode op een openbare Chinese dataset van de CLUE-benchmark, die realistische korte-tekstscenario’s simuleert zoals berichten op sociale media en zoekopdrachten. Ze vergeleken vier benaderingen: versies met traditionele Word2Vec-embeddings, het ELMo-taalmodel, een BERT-gebaseerd systeem zonder de kortste-pad-stap, en hun volledige BiLSTM-CRF-BERT-SPA-pijplijn. Over duizenden teksten verbeterde hun complete methode de nauwkeurigheid, recall en F1-score gemiddeld met ongeveer een kwart vergeleken met de anderen. In praktische termen was het systeem zowel beter in het vinden van de juiste entiteiten als consistenter over verschillende datagroottes.
Wat dit betekent voor alledaagse technologie
Voor niet-specialisten is de conclusie eenvoudig: door een krachtig taalbegripsmodel (BERT) te combineren met een grafgebaseerde kortste-pad-zoektocht geven de auteurs computers een betrouwbaardere manier om te bepalen waar een ambigu naamwoord in korte, lawaaierige teksten naar verwijst. Dit kan zoekmachines slimmer maken, sociale platformen helpen posts beter te begrijpen en downstream tools verbeteren zoals aanbevelingssystemen en kennisgrafen. Hoewel de methode momenteel gericht is op het Chinees en nog ruimte heeft voor efficiëntieverbeteringen, toont het aan hoe het combineren van moderne AI met klassieke algoritmen verwarring in hoe machines onze alledaagse taal interpreteren sterk kan verminderen.
Bronvermelding: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
Trefwoorden: entiteitsdisambiguering, korte tekst, BERT, kennisgraaf, verwerking van natuurlijke taal