Clear Sky Science · nl
Ontkoppelen van inhoud en stijl voor beeldgeneratie met meerdere stijlen met behulp van latent diffusion-architectuur
Waarom slimmere beeldstijlen ertoe doen
Van filmaffiches en game-art tot socialmediaplugins, we verwachten steeds vaker dat beelden zowel visueel opvallend als sterk gepersonaliseerd zijn. Veel style-transfer-systemen worstelen echter nog achter de schermen: ze kunnen iemands gezicht vervormen, gebouwen uit hun vorm trekken of veel zware hardware vereisen. Dit artikel introduceert een nieuw AI-model dat rijkere artistieke stijlen belooft, terwijl het originele beeld intact blijft en het efficiënt genoeg draait voor alledaagse apparaten.
Het verschil tussen “wat het is” en “hoe het eruitziet”
De kern van dit werk is een model dat Dual-Condition Lightweight Style Diffusion Model (DCLSDM) heet. De hoofdgedachte is om de substantie van een beeld—de objecten, lay-out en scène—als één "kanaal" te behandelen, en de artistieke behandeling—kleuren, texturen, penseelstreken—als een ander, en deze apart te sturen. In plaats van één netwerk deze twee aspecten door elkaar te laten halen, gebruikt DCLSDM twee speciale paden: één voor inhoud en één voor stijl. Het inhoudspad richt zich op het begrijpen van vormen en betekenissen in een invoerbeeld of tekstbeschrijving, terwijl het stijlpad zich richt op het leren van het visuele karakter van een gekozen kunstwerk of stijlbeschrijving.
Hoe het nieuwe model is opgebouwd
DCLSDM bouwt voort op diffusiemodellen, dezelfde familie technieken achter veel moderne beeldgeneratoren. In plaats van direct op volledig-resolutie afbeeldingen te werken, opereert het in een gecomprimeerde "latente" ruimte, wat veel efficiënter is. Een module genaamd Perceiver IO extraheert de inhoud: deze neemt een afbeelding of onderschrift op en destilleert de geometrie en semantiek van de scène tot een compacte representatie. Een aparte stijlmodule leest een of meer stijlafbeeldingen of teksten en zet deze om in stijlfeaturevectoren. Deze stijlfeatures kunnen worden gemengd met een gewogen interpolatieschema, waardoor vloeiende overgangen mogelijk zijn tussen bijvoorbeeld een impressionistische en een minimalistische uitstraling zonder de gebruikelijke "modderige" gemiddeldeffecten.
Structuur behouden terwijl de stijl verandert
Binnen het diffusienetwerk dat het beeld daadwerkelijk genereert, worden de twee soorten informatie via onafhankelijke routes geïnjecteerd. Inhoudssignalen sturen de netwerklagen die om structuur geven—waar randen, objecten en lay-outs moeten komen. Stijlsignalen worden geïnjecteerd via speciale attention-lagen die vooral texturen, kleuren en penseelwerk vormen. Daarbovenop voegt een component genaamd ControlNet extra structurele sturing toe met behulp van rand- of dieptemappen die uit de originele inhoud zijn gehaald. Deze combinatie betekent dat het systeem een zomers landschap in een winters palet kan herschilderen, of een foto kan weergeven als een Van Gogh-achtig schilderij, terwijl bergen, bomen en gebouwen op de juiste plaats blijven en niet vervormen.
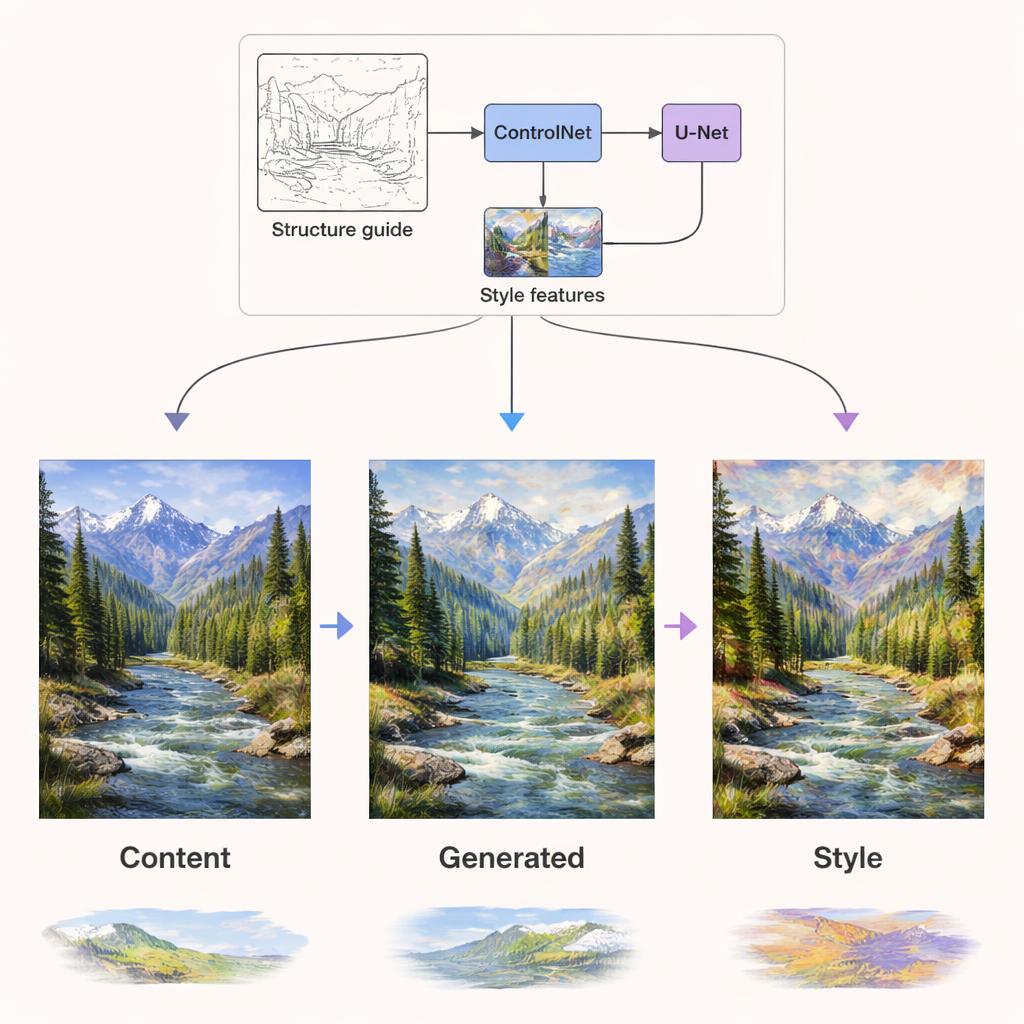
Betere kwaliteit, meer stijlen, minder rekenkracht
De auteurs testen DCLSDM rigoureus op twee openbare datasets: WikiArt, dat tientallen kunststromingen bestrijkt, en Summer2Winter Yosemite, dat zich richt op seizoensveranderingen in een landschap. Ze vergelijken hun model met een reeks state-of-the-art systemen die zowel in onderzoek als industrie worden gebruikt. Over maten van structurele gelijkenis, waargenomen visuele kwaliteit en hoe nauw de gegenereerde beelden echte kunstwerken benaderen, scoort DCLSDM consequent het hoogst. Het draait ook sneller, gebruikt minder geheugen en heeft minder parameters dan veel concurrenten, terwijl het nog steeds flexibele menging van meerdere stijlen biedt en zowel beeldgebaseerde als tekstgebaseerde stijlinput ondersteunt.
Wat dit betekent voor alledaagse creativiteit
In praktische termen laat dit werk zien dat het mogelijk is gebruikers fijnmazige controle te geven over hoe een beeld eruitziet zonder op te offeren wat het beeld toont—en dat op wat bescheidener hardware. Ontwerpers kunnen snel veel artistieke bewerkingen van dezelfde lay-out verkennen, mobiele apps kunnen rijkere filters aanbieden die gezichten of scènes niet vervormen, en projecten rond cultureel erfgoed kunnen oude foto’s herstylen terwijl cruciale structurele details behouden blijven. Door inhoud en stijl binnen een modern diffusiekader helder te scheiden, wijst DCLSDM naar een toekomst waarin creatieve beeldtools zowel krachtiger als betrouwbaarder zijn voor dagelijks gebruik.
Bronvermelding: Chu, K., Shang, Y., Zhang, L. et al. Content style decoupling for multi style image generation using latent diffusion architecture. Sci Rep 16, 6642 (2026). https://doi.org/10.1038/s41598-026-36407-3
Trefwoorden: beeldstijltransfer, diffusiemodellen, inhoud-stijl ontkoppeling, digitale kunstgeneratie, efficiënte beeldgeneratie