Clear Sky Science · nl
Versterkend‑leerframework voor computergebaseerde adaptieve toetsen met een multi‑armed bandit‑benadering
Slimmere toetsen voor het digitale klaslokaal
Wie ooit een lange, uniforme toets heeft gemaakt weet hoe saai en oneerlijk dat kan aanvoelen. Sommige vragen zijn veel te makkelijk, andere onmogelijk moeilijk, en de eindscore geeft mogelijk niet goed weer wat je echt weet. Dit artikel presenteert een nieuwe manier om computergestuurde toetsen te bouwen die zich in real‑time aanpassen aan de antwoorden van elke persoon. Door ideeën uit moderne kunstmatige intelligentie te gebruiken, willen de auteurs toetsen korter, nauwkeuriger en beter afgestemd op het werkelijke niveau van iedere deelnemer maken.
Waarom vaste toetsen tekortschieten
Traditionele examens geven elke student dezelfde set vragen. Dat maakt het opstellen van toetsen eenvoudig, maar het verspilt informatie: sterke studenten gaan door veel makkelijke items heen, terwijl zwakkere studenten snel overweldigd raken. Computergebaseerde adaptieve toetsing probeert dit te verbeteren door elke volgende vraag te kiezen op basis van eerdere antwoorden, maar de meeste huidige systemen bouwen nog steeds op decennia‑oude statistische modellen en handgemaakte regels. Deze oudere benaderingen hebben moeite met het vastleggen van complexe antwoordpatronen en kunnen vaak niet volledig rekening houden met de grote verschillen tussen leerlingen in moderne, grootschalige onlineomgevingen.
Moderne AI in de toetsing brengen
De auteurs stellen een nieuw raamwerk voor dat deep learning en versterkend leren combineert om adaptieve toetsen van begin tot eind aan te sturen. Het systeem werkt in herhaalde cycli. Eerst analyseert een eendimensionaal convolutioneel neuraal netwerk (1D‑CNN) iemands recente antwoorden, de moeilijkheid van de vragen en andere samenvattende statistieken. Uit deze stroom gegevens produceert het één getal dat het huidige vaardigheidsniveau van de persoon op een genormaliseerde schaal vertegenwoordigt, vergelijkbaar met hoe traditionele toetstheorieën vaardigheid beschrijven, maar hier rechtstreeks uit data geleerd. Dit netwerk wordt getraind om subtiele patronen te herkennen, zoals consistent succes bij moeilijkere vragen of onverwachte fouten bij eenvoudigere items. 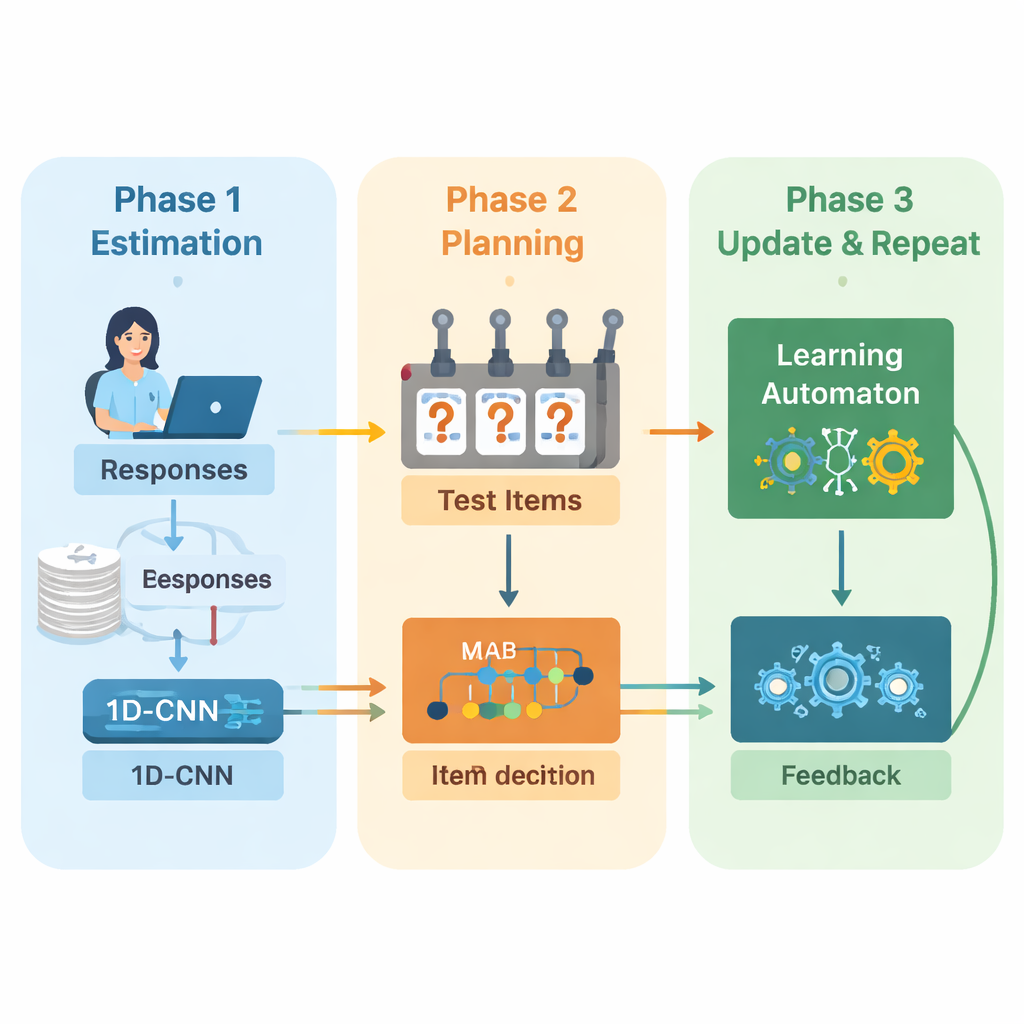
De juiste volgende vraag kiezen
Zodra het systeem een bijgewerkte inschatting van vaardigheid heeft, moet het beslissen wat het volgende is om te vragen. Hier gebruiken de auteurs een "multi‑armed bandit"‑strategie, een klassiek middel uit de besluitvormingstheorie waarbij elke mogelijke actie wordt behandeld als het trekken aan een hendel van een gokautomaat. In deze context is elke vraag in de itembank een arm. Het algoritme kijkt naar vragen waarvan de moeilijkheidsgraad ruwweg overeenkomt met de huidige vaardigheidsschatting en kiest vervolgens die vragen waarvan verwacht wordt dat ze het meest informatief zijn. Het maakt een afweging tussen twee doelen: een goede moeilijkheidsmatch krijgen, zodat antwoorden noch te makkelijk noch te moeilijk zijn, en zoveel mogelijk verschillende inhoudsgebieden beslaan, zodat de toets geen belangrijke onderwerpen negeert. Een beloningsscore die deze twee doelen combineert stuurt het selectieproces aan.
Leren van zijn eigen beslissingen
Om tijdens de toets beter te blijven presteren voegt het systeem een andere leercomponent toe, een zogeheten learning automaton. Deze module kijkt hoe de geschatte vaardigheid zich over rondes heen verandert en of de nauwkeurigheid van de persoon verbetert of verslechtert. Het past een kleine reeks waarschijnlijkheden aan die samenvatten of het model verwacht dat de vaardigheid zal stijgen, gelijk zal blijven of zal dalen. Deze waarschijnlijkheden worden vervolgens als extra invoer teruggegeven aan het neurale netwerk in de volgende ronde. Op die manier leert de toetsmotor niet alleen over de leerling, maar ook over zijn eigen eerdere beslissingen—waardoor trends die tot nauwkeurige schattingen leidden worden versterkt en trends die dat niet deden worden gestraft. 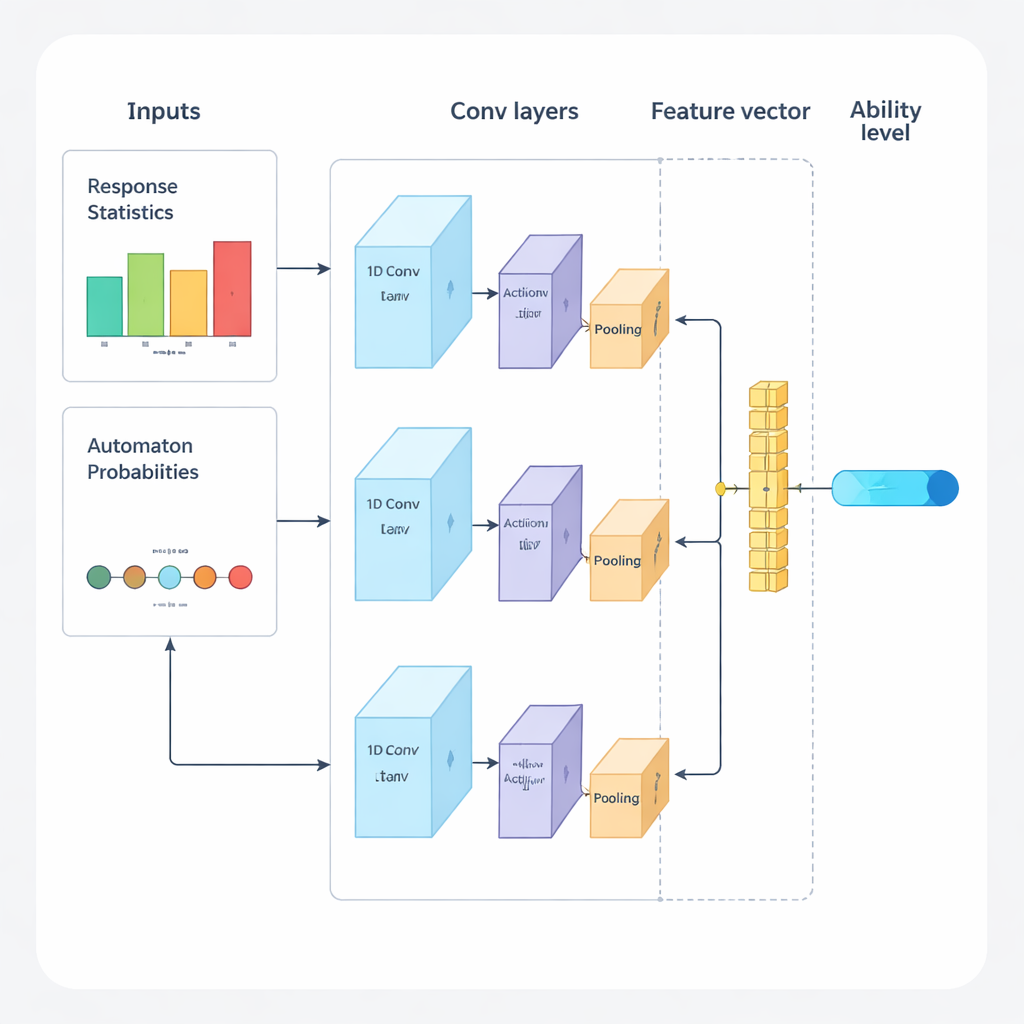
Hoe goed werkt het in de praktijk?
De onderzoekers evalueerden hun raamwerk met behulp van een grote, meertalige toetsdataset en duizenden gesimuleerde deelnemers waarvan het werkelijke vaardigheidsniveau bekend was. Ze vergeleken hun aanpak met verschillende toonaangevende adaptieve toetsmethoden. Over een reeks fouten‑ en correlatiematen produceerde het nieuwe systeem nauwkeurigere vaardigheidsschattingen terwijl het minder vragen nodig had. De fouten—gemeten met gangbare statistieken zoals de wortel van de gemiddelde kwadratische fout en de gemiddelde absolute fout—waren duidelijk lager dan bij concurrerende methoden. Tegelijkertijd verspreidde het systeem het gebruik van vragen gelijkmatiger over de itembank, waardoor het risico dat bepaalde vragen te vaak worden gebruikt en uitlekken vermindert.
Wat dit betekent voor toekomstige toetsen
In gewone bewoordingen suggereert dit werk dat toekomstige computergebaseerde toetsen meer kunnen aanvoelen als een op maat gemaakte bijles dan als een rigide examen. Vragen zouden snel de juiste moeilijkheid voor iedere persoon vinden, het volledige scala aan relevante onderwerpen verkennen en afronden zodra het systeem zeker is van je niveau—vaak met minder items dan huidige toetsen. Hoewel de methode nog steeds afhankelijk is van goede trainingsdata en rekencapaciteit, en tot nu toe op één dataset is getest, wijst het op een nieuwe generatie slimmere, eerlijkere en efficiëntere assessments die zich op natuurlijke wijze aan individuele leerlingen aanpassen.
Bronvermelding: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
Trefwoorden: computergebaseerde adaptieve toetsing, educatieve beoordeling, deep learning, versterkend leren, multi‑armed bandit